At Crossref and ROR, we develop and run processes that match metadata at scale, creating relationships between millions of entities in the scholarly record. Over the last few years, we’ve spent a lot of time diving into details about metadata matching strategies, evaluation, and integration. It is quite possibly our favourite thing to talk and write about! But sometimes it is good to step back and look at the problem from a wider perspective.
This year’s public data file is now available, featuring over 156 million metadata records deposited with Crossref through the end of April 2024 from over 19,000 members. A full breakdown of Crossref metadata statistics is available here.
Like last year, you can download all of these records in one go via Academic Torrents or directly from Amazon S3 via the “requester pays” method.
Download the file: The torrent download can be initiated here.
Earlier this year, we reported on the roundtable discussion event that we had organised in Frankfurt on the heels of the Frankfurt Book Fair 2023. This event was the second in the series of roundtable events that we are holding with our community to hear from you how we can all work together to preserve the integrity of the scholarly record - you can read more about insights from these events and about ISR in this series of blogs.
Crossref is undertaking a large program, dubbed 'RCFS' (Resourcing Crossref for Future Sustainability) that will initially tackle five specific issues with our fees. We haven’t increased any of our fees in nearly two decades, and while we’re still okay financially and do not have a revenue growth goal, we do have inclusion and simplification goals. This report from Research Consulting helped to narrow down the five priority projects for 2024-2025 around these three core goals:
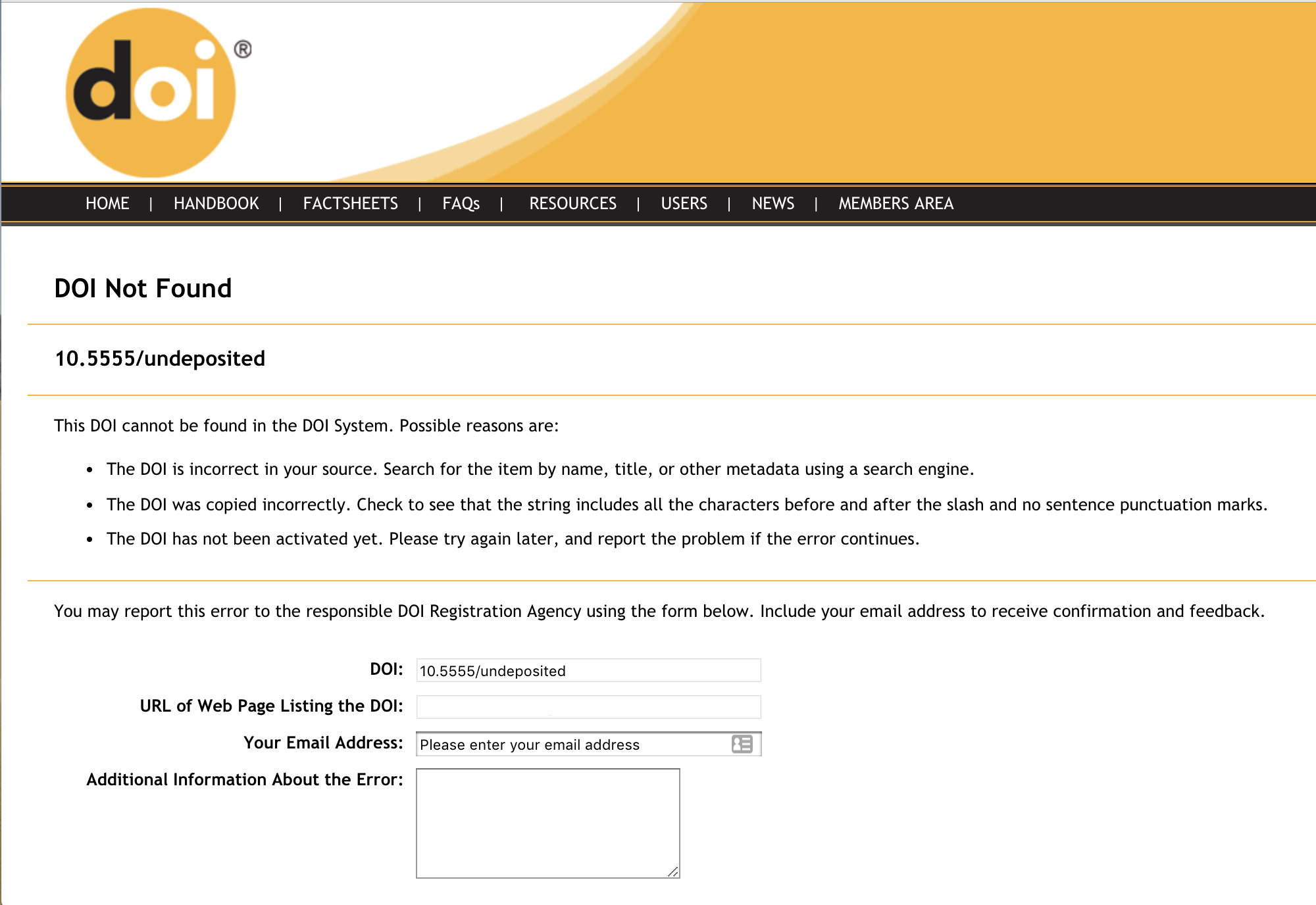
The DOI error report is sent immediately when a user informs us that they’ve seen a DOI somewhere which doesn’t resolve to a website.
The DOI error report is used for making sure your DOI links go where they’re supposed to. When a user clicks on a DOI that has not been registered, they are sent to a form that collects the DOI, the user’s email address, and any comments the user wants to share.
We compile the DOI error report daily using those reports and comments, and email it to the technical contact at the member responsible for the DOI prefix as a .csv attachment. If you would like the DOI error report to be sent to a different person, please contact us.
The DOI error report .csv file contains (where provided by the user):
DOI - the DOI being reported
URL - the referring URL
REPORTED-DATE - date the DOI was initially reported
USER-EMAIL - email of the user reporting the error
COMMENTS
We find that approximately 2/3 of reported errors are ‘real’ problems. Common reasons why you might get this report include:
you’ve published/distributed a DOI but haven’t registered it
the DOI you published doesn’t match the registered DOI
a link was formatted incorrectly (a . at the end of a DOI, for example)
a user has made a mistake (confusing 1 for l or 0 for O, or cut-and-paste errors)
What should I do with my DOI error report?
Review the .csv file attached to your emailed report, and make sure that no legitimate DOIs are listed. Any legitimate DOIs found in this report should be registered immediately. When a DOI reported via the form is registered, we’ll send out an alert to the reporting user (if they’ve shared their email address with us).
I keep getting DOI error reports for DOIs that I have not published, what do I do about this?
It’s possible that someone is trying to link to your content with the wrong DOI. If you do a web search for the reported DOI you may find the source of your problem - we often find incorrect linking from user-provided content like Wikipedia, or from DOIs inadvertently distributed by members to PubMed. If it’s still a mystery, please contact us.
Page owner: Isaac Farley | Last updated 2020-April-08