
Who Cares about the Weather? Inferring Weather Conditions for Weather-Aware Object Detection in Thermal Images
 , , and
, , and
Abstract
:Featured Application
Abstract
1. Introduction
1.1. Estimating Weather
1.2. Adapting to Weather
1.3. Leveraging Metadata for Recognition
1.4. Qualitative vs. Quantitative Thermal Cameras
2. Methodology
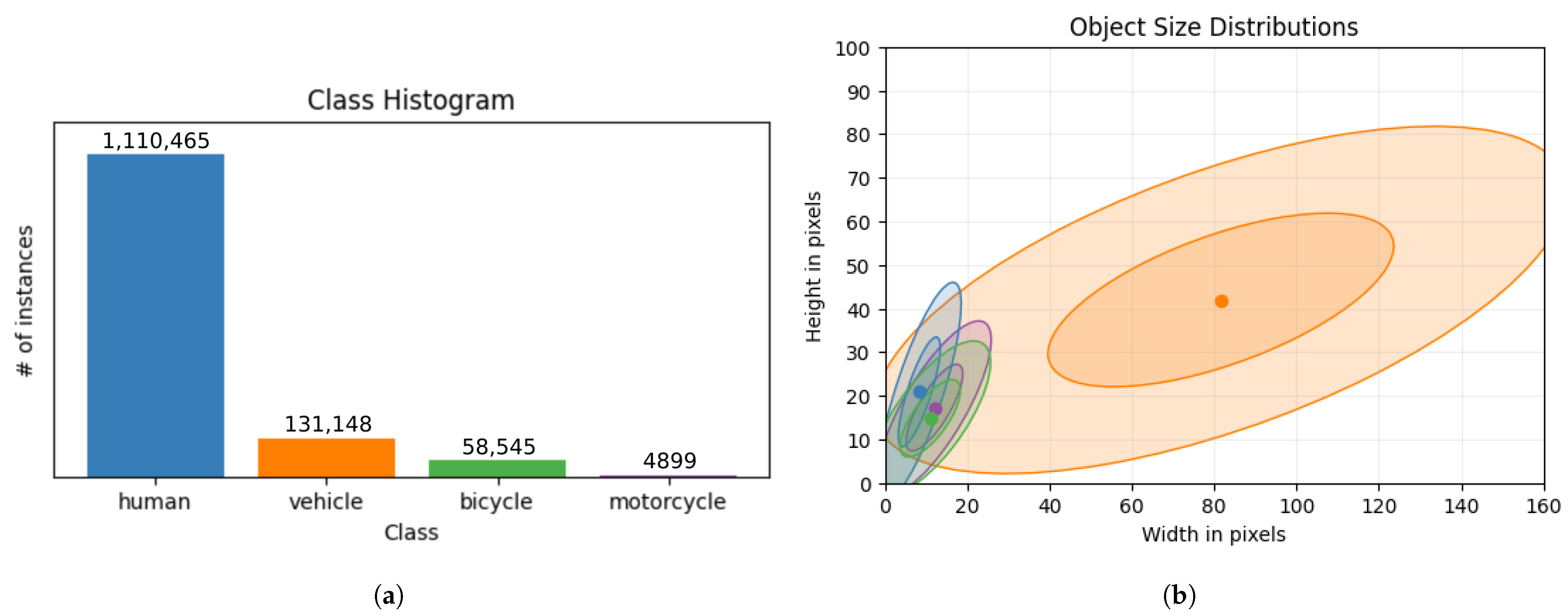
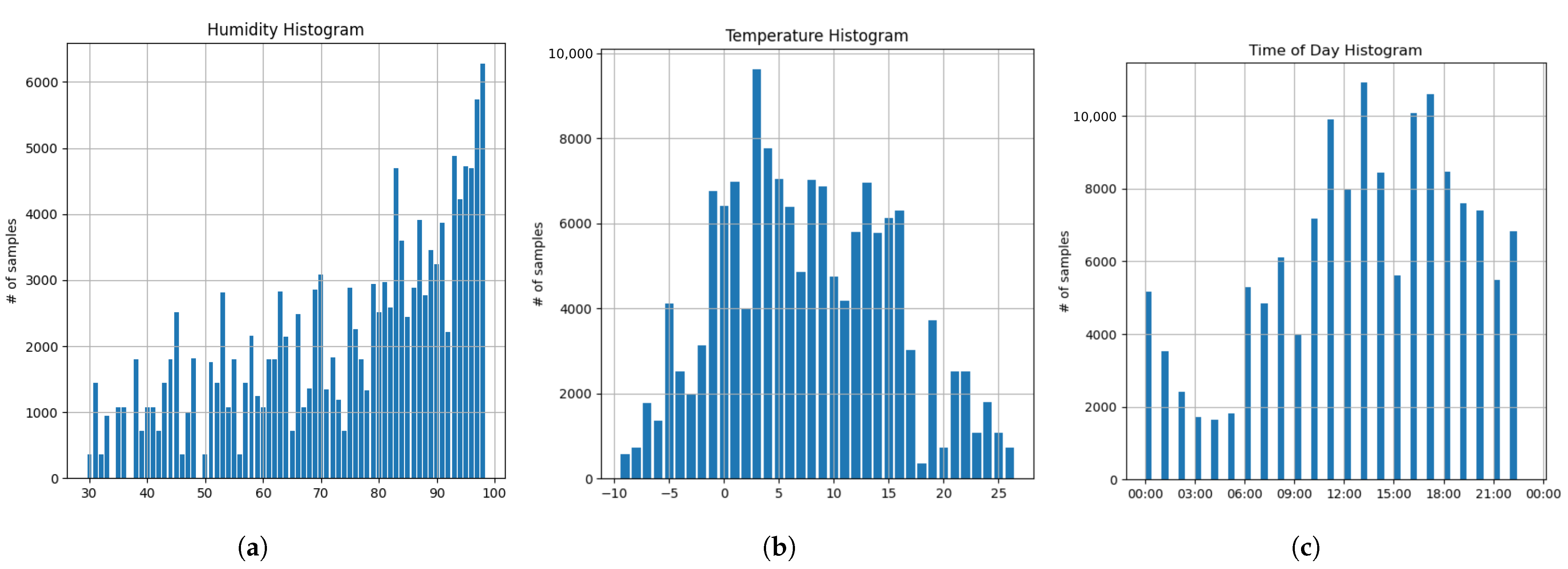
2.1. Dataset
2.2. From Discrete to Continuous Meta-Prediction
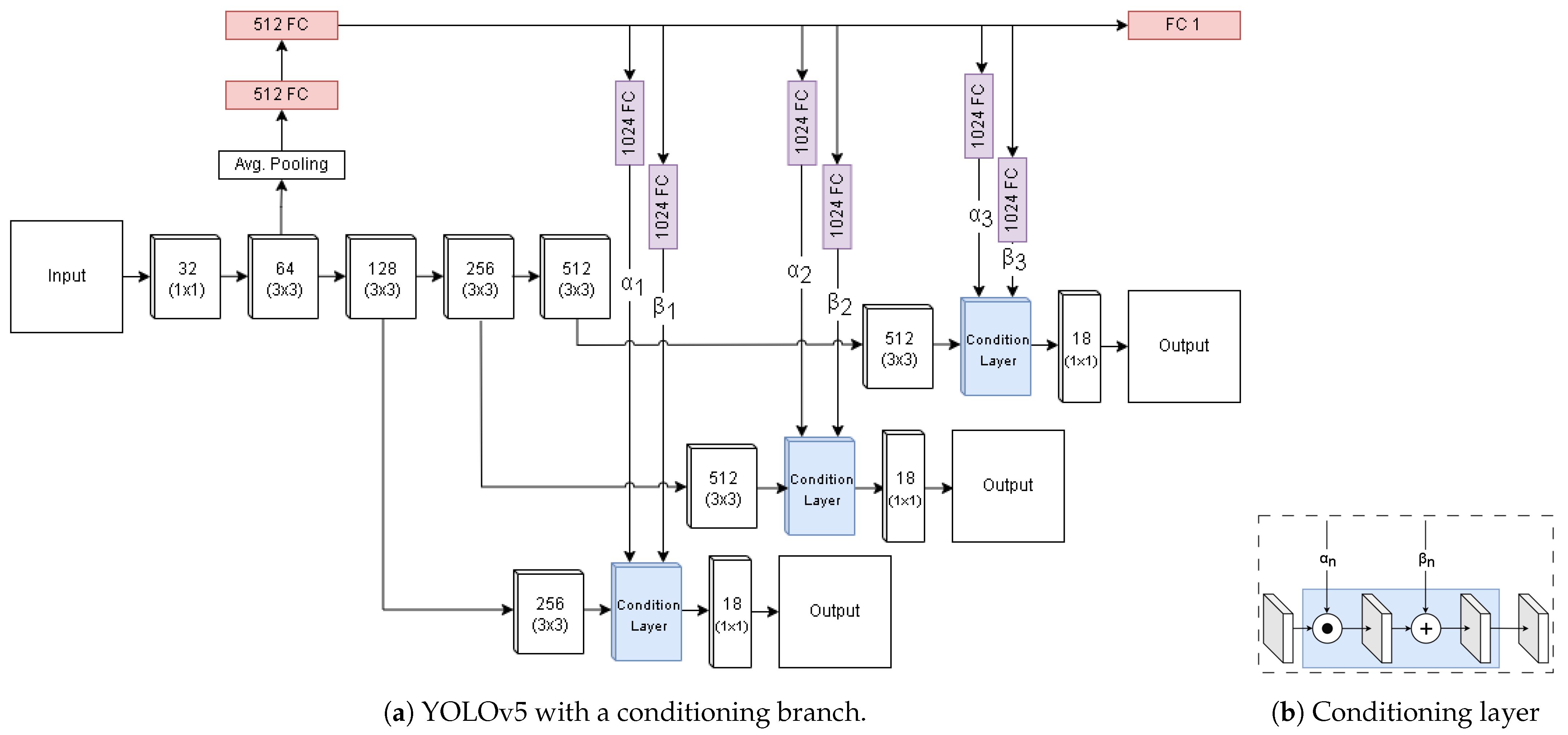
2.3. Direct Conditioning
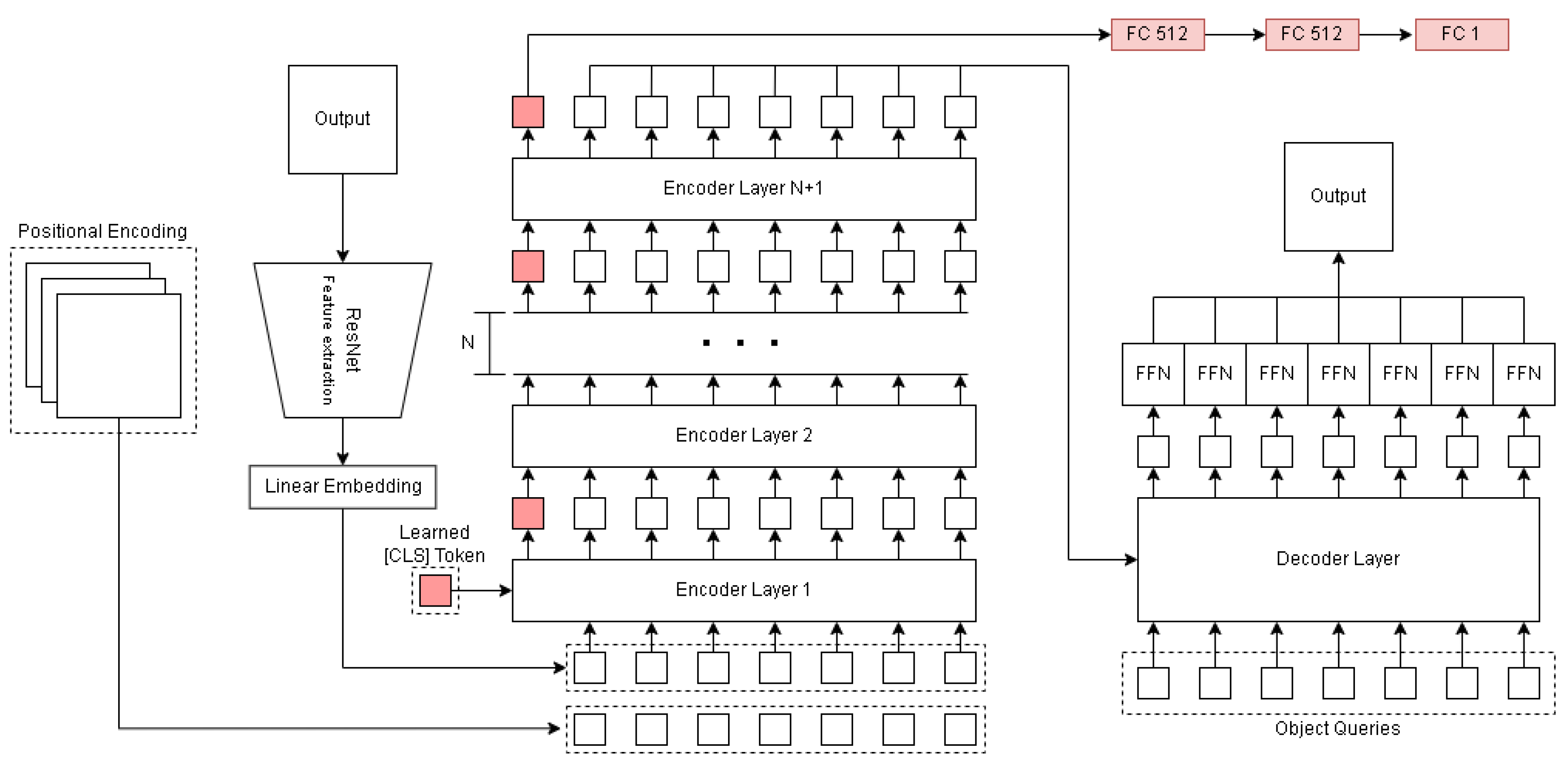
2.4. Indirectly Imposed Conditioning
3. Results
3.1. Experimental Setting
3.2. Evaluating Weather Conditioning
3.3. Accuracy
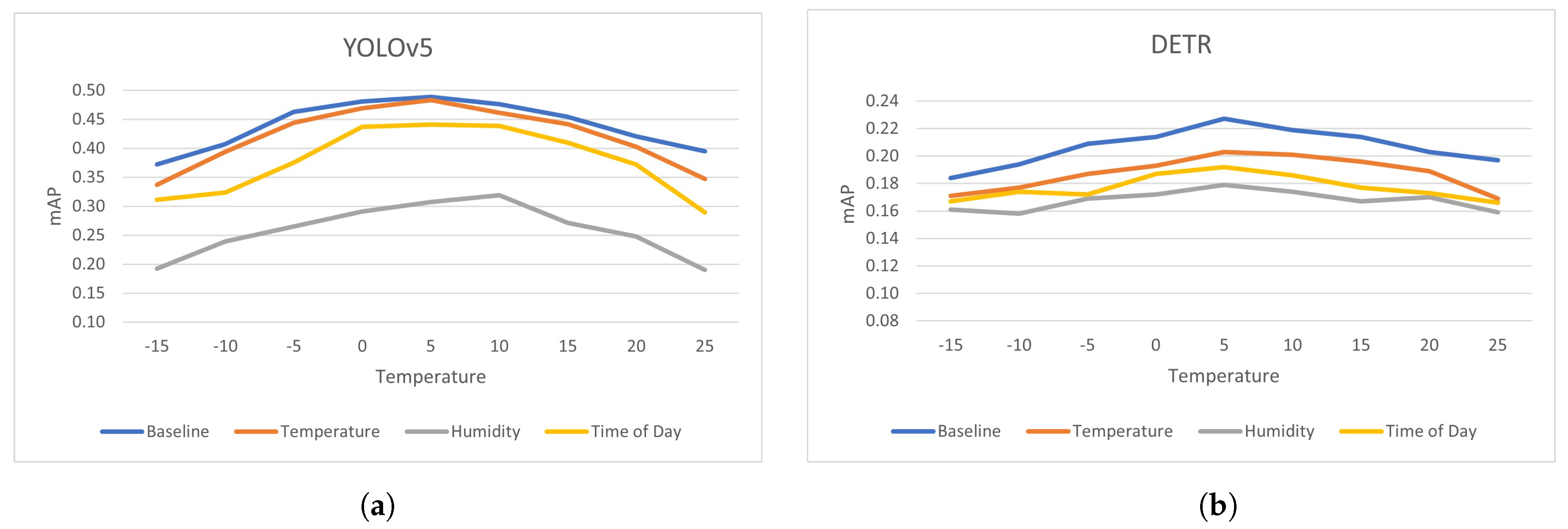
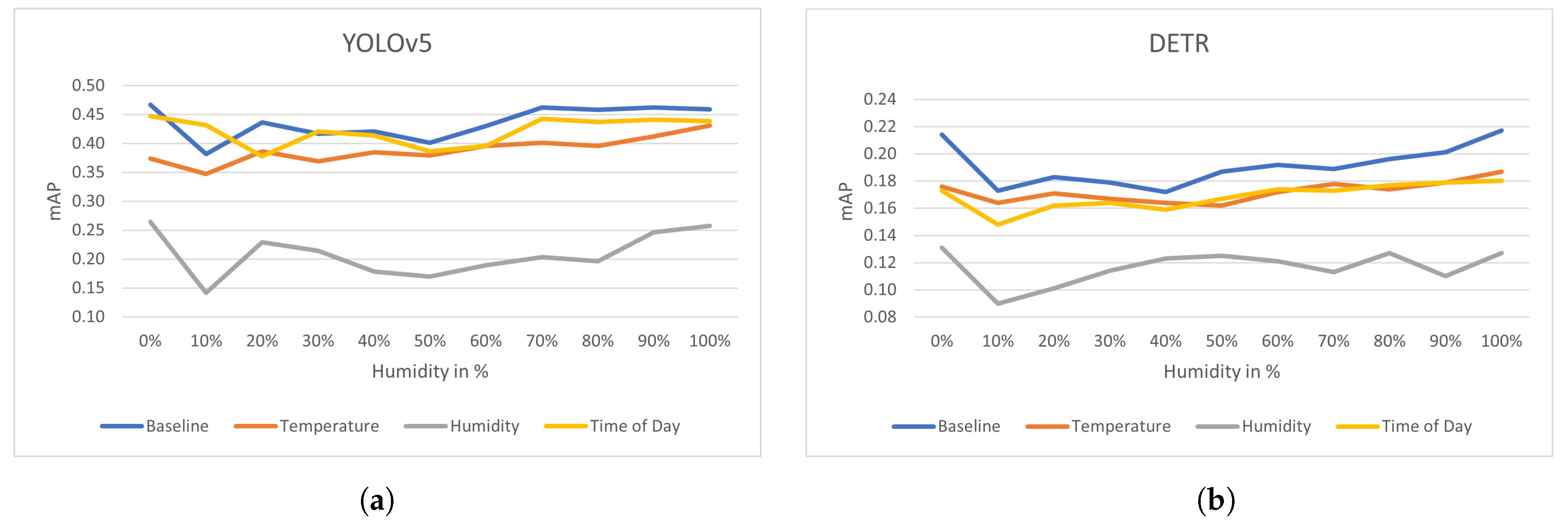
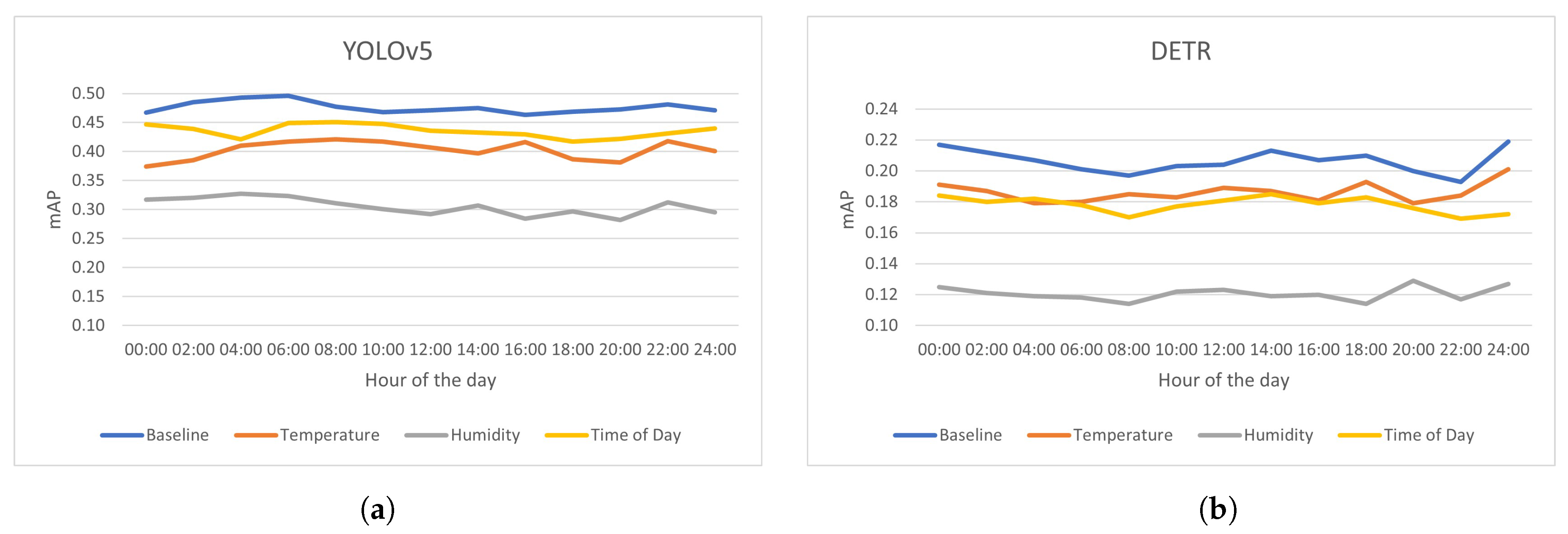
3.4. Accuracy Compared to Weather
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AP | Average Precision 6 |
| CCTV | Closed Circuit Television 3 |
| CNN | Convolutional Neural Network 14 |
| DETR | Detection Transformer 9–11, 14 |
| IoU | Intersection over Union 6, 8, 10 |
| KAIST | KAIST Multispectral Pedestrian Detection 4, 6, 7, 14, 17 |
| LTD | Long-term Thermal Drift 3–7, 10 |
| MAE | Mean Average Error 7, 10 |
| mAP | Mean Average Precision 6, 8, 10, 11, 13–15 |
| MAPE | Mean Average Percentage Error 7 |
| MR | Miss Rate 8, 10, 11, 14, 15 |
| MS COCO | Microsoft Common Objects in Context 6, 10 |
| MWD | Multi-class Weather Dataset 2 |
| RFS | Rain Fog Snow 2 |
| SotA | State of the Art 4 |
| Std. | Standard Deviation 7, 10 |
| VOC | Pascal Visual Object Challenge 6, 10 |
| YOLO | You Only Look Once 2, 4, 8, 10, 14 |
Appendix A. Contrast-Enhanced KAIST Examples

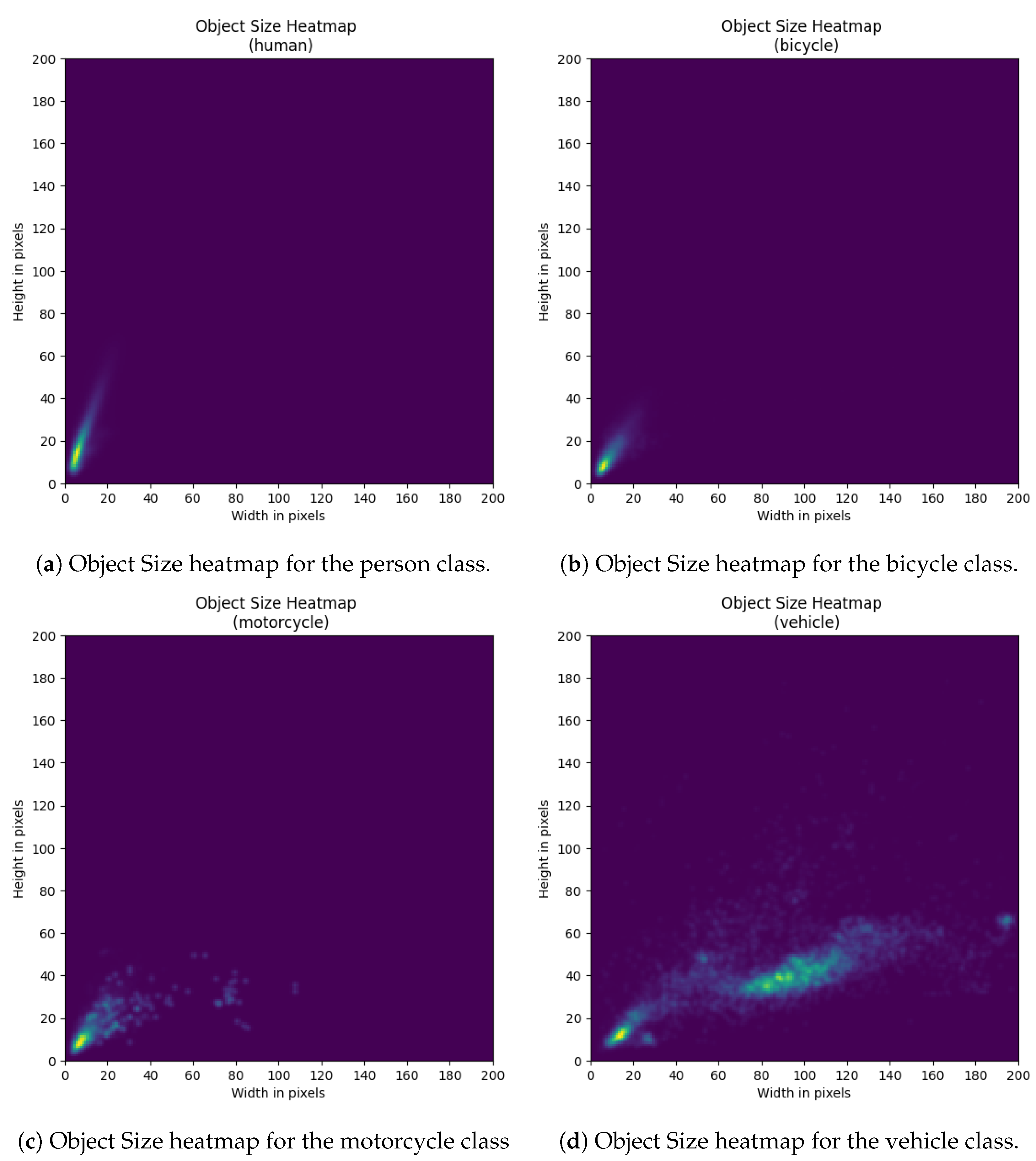
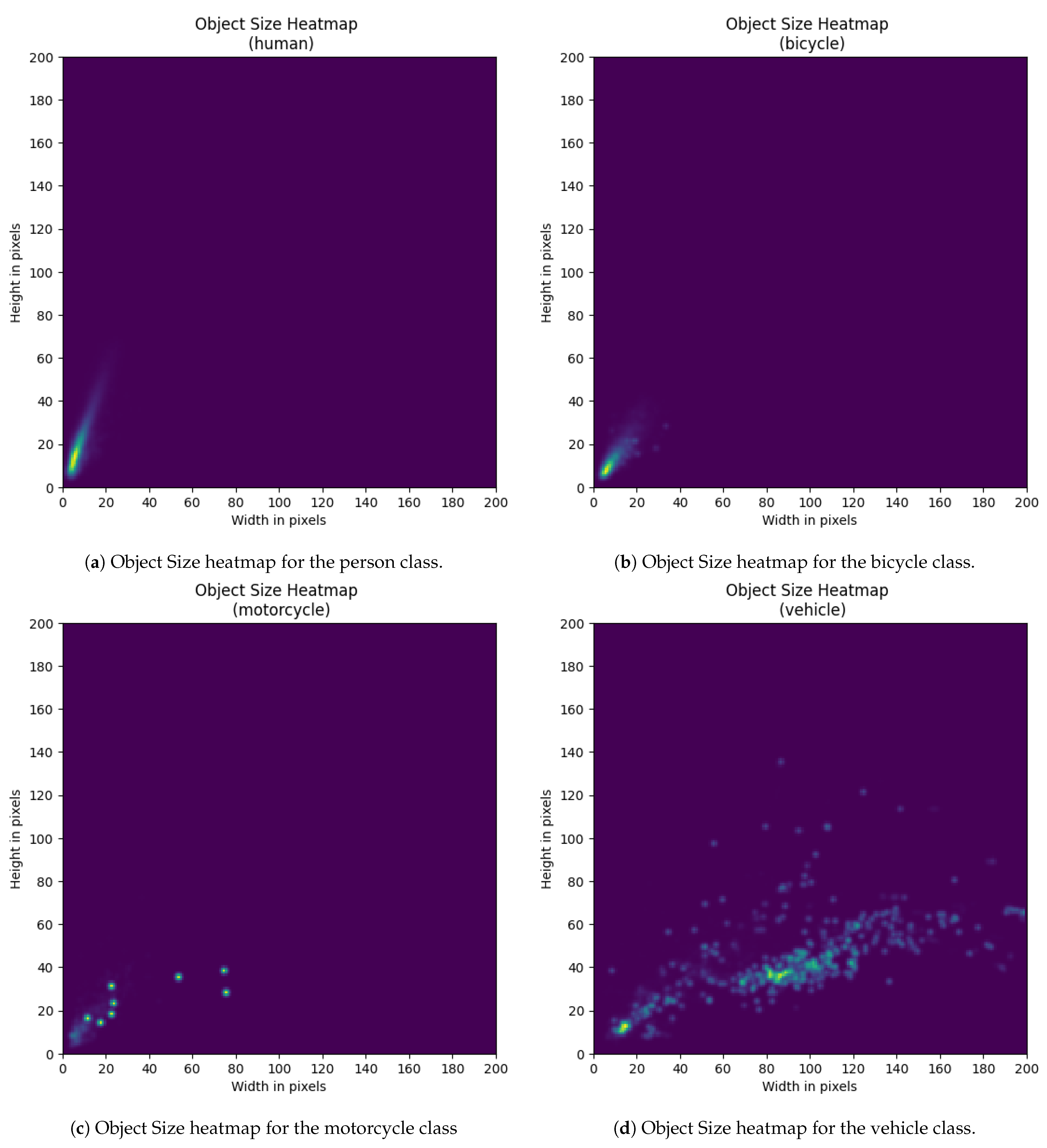
Appendix B. Additional Dataset Figures
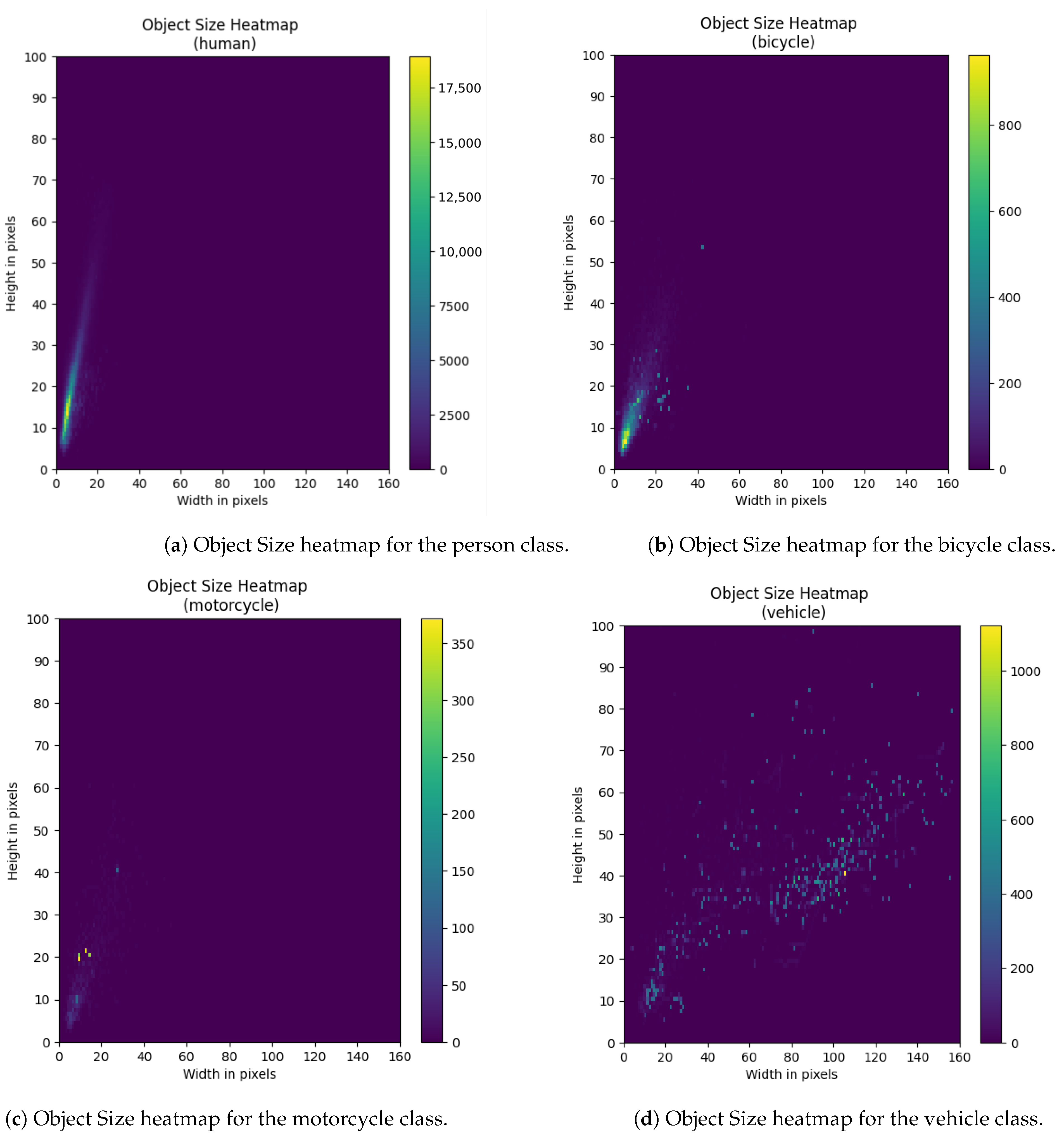
Class-Wise Object Distributions




References
- Nikolov, I.A.; Philipsen, M.P.; Liu, J.; Dueholm, J.V.; Johansen, A.S.; Nasrollahi, K.; Moeslund, T.B. Seasons in drift: A long-term thermal imaging dataset for studying concept drift. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems, Neural Information Processing Systems Foundation, Virtual, 6–14 December 2021. [Google Scholar]
- Kieu, M.; Bagdanov, A.D.; Bertini, M.; Del Bimbo, A. Task-conditioned domain adaptation for pedestrian detection in thermal imagery. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 546–562. [Google Scholar]
- Hu, R.; Singh, A. Unit: Multimodal multitask learning with a unified transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1439–1449. [Google Scholar]
- Heuer, F.; Mantowsky, S.; Bukhari, S.; Schneider, G. Multitask-centernet (mcn): Efficient and diverse multitask learning using an anchor free approach. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 997–1005. [Google Scholar]
- Bhattacharjee, D.; Zhang, T.; Süsstrunk, S.; Salzmann, M. Mult: An end-to-end multitask learning transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12031–12041. [Google Scholar]
- Perreault, H.; Bilodeau, G.A.; Saunier, N.; Héritier, M. Spotnet: Self-attention multi-task network for object detection. In Proceedings of the 2020 17th Conference on Computer and Robot Vision (CRV), Ottawa, ON, Canada, 13–15 May 2020; pp. 230–237. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Dahmane, K.; Duthon, P.; Bernardin, F.; Colomb, M.; Chausse, F.; Blanc, C. Weathereye-proposal of an algorithm able to classify weather conditions from traffic camera images. Atmosphere 2021, 12, 717. [Google Scholar] [CrossRef]
- Bhandari, H.; Palit, S.; Chowdhury, S.; Dey, P. Can a camera tell the weather? In Proceedings of the 2021 36th International Conference on Image and Vision Computing New Zealand (IVCNZ), Tauranga, New Zealand, 9–10 December 2021; pp. 1–6. [Google Scholar]
- Chu, W.T.; Zheng, X.Y.; Ding, D.S. Camera as weather sensor: Estimating weather information from single images. J. Vis. Commun. Image Represent. 2017, 46, 233–249. [Google Scholar] [CrossRef]
- Guerra, J.C.V.; Khanam, Z.; Ehsan, S.; Stolkin, R.; McDonald-Maier, K. Weather Classification: A new multi-class dataset, data augmentation approach and comprehensive evaluations of Convolutional Neural Networks. In Proceedings of the 2018 NASA/ESA Conference on Adaptive Hardware and Systems (AHS), Edinburgh, UK, 6–9 August 2018; pp. 305–310. [Google Scholar]
- Lin, D.; Lu, C.; Huang, H.; Jia, J. RSCM: Region selection and concurrency model for multi-class weather recognition. IEEE Trans. Image Process. 2017, 26, 4154–4167. [Google Scholar] [CrossRef] [PubMed]
- Glasner, D.; Fua, P.; Zickler, T.; Zelnik-Manor, L. Hot or not: Exploring correlations between appearance and temperature. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3997–4005. [Google Scholar]
- Ye, R.; Yan, B.; Mi, J. BIVS: Block Image and Voting Strategy for Weather Image Classification. In Proceedings of the 2020 IEEE 3rd International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 14–16 August 2020; pp. 105–110. [Google Scholar]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. CSUR 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef]
- Xiang, Q.; Zi, L.; Cong, X.; Wang, Y. Concept Drift Adaptation Methods under the Deep Learning Framework: A Literature Review. Appl. Sci. 2023, 13, 6515. [Google Scholar] [CrossRef]
- Bahnsen, C.H.; Moeslund, T.B. Rain removal in traffic surveillance: Does it matter? IEEE Trans. Intell. Transp. Syst. 2018, 20, 2802–2819. [Google Scholar] [CrossRef]
- Wei, W.; Meng, D.; Zhao, Q.; Xu, Z.; Wu, Y. Semi-Supervised Transfer Learning for Image Rain Removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, H.; Yue, Z.; Xie, Q.; Zhao, Q.; Zheng, Y.; Meng, D. From rain generation to rain removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14791–14801. [Google Scholar]
- Li, S.; Ren, W.; Zhang, J.; Yu, J.; Guo, X. Single image rain removal via a deep decomposition–composition network. Comput. Vis. Image Underst. 2019, 186, 48–57. [Google Scholar] [CrossRef]
- Chen, J.; Tan, C.H.; Hou, J.; Chau, L.P.; Li, H. Robust video content alignment and compensation for rain removal in a cnn framework. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6286–6295. [Google Scholar]
- Li, K.; Li, Y.; You, S.; Barnes, N. Photo-Realistic Simulation of Road Scene for Data-Driven Methods in Bad Weather. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Rao, Q.; Frtunikj, J. Deep learning for self-driving cars: Chances and challenges. In Proceedings of the 1st International Workshop on Software Engineering for AI in Autonomous Systems, Gothenburg, Sweden, 28 May 2018; pp. 35–38. [Google Scholar]
- Tremblay, M.; Halder, S.S.; De Charette, R.; Lalonde, J.F. Rain rendering for evaluating and improving robustness to bad weather. Int. J. Comput. Vis. 2021, 129, 341–360. [Google Scholar] [CrossRef]
- Halder, S.S.; Lalonde, J.F.; Charette, R.d. Physics-based rendering for improving robustness to rain. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10203–10212. [Google Scholar]
- Gao, J.; Wang, J.; Dai, S.; Li, L.J.; Nevatia, R. Note-rcnn: Noise tolerant ensemble rcnn for semi-supervised object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 9508–9517. [Google Scholar]
- Solovyev, R.; Wang, W.; Gabruseva, T. Weighted boxes fusion: Ensembling boxes from different object detection models. Image Vis. Comput. 2021, 107, 104117. [Google Scholar] [CrossRef]
- Körez, A.; Barışçı, N.; Çetin, A.; Ergün, U. Weighted ensemble object detection with optimized coefficients for remote sensing images. ISPRS Int. J. Geo-Inf. 2020, 9, 370. [Google Scholar] [CrossRef]
- Walambe, R.; Marathe, A.; Kotecha, K.; Ghinea, G. Lightweight object detection ensemble framework for autonomous vehicles in challenging weather conditions. Comput. Intell. Neurosci. 2021, 2021, 5278820. [Google Scholar] [CrossRef] [PubMed]
- Dai, R.; Lefort, M.; Armetta, F.; Guillermin, M.; Duffner, S. Self-supervised continual learning for object recognition in image sequences. In Proceedings of the Neural Information Processing: 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, 8–12 December 2021; Proceedings, Part V 28. Springer: Berlin/Heidelberg, Germany, 2021; pp. 239–247. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Tian, Y.; Bai, K. End-to-End Multitask Learning with Vision Transformer. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–12. [Google Scholar] [CrossRef]
- Singh, S.; Khim, J.T. Optimal Binary Classification Beyond Accuracy. Adv. Neural Inf. Process. Syst. 2022, 35, 18226–18240. [Google Scholar]
- Ghosh, S.; Delle Fave, F.; Yedidia, J. Assumed density filtering methods for learning bayesian neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Akkaya, I.B.; Altinel, F.; Halici, U. Self-training guided adversarial domain adaptation for thermal imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4322–4331. [Google Scholar]
- Chen, G.; Liu, S.J.; Sun, Y.J.; Ji, G.P.; Wu, Y.F.; Zhou, T. Camouflaged object detection via context-aware cross-level fusion. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6981–6993. [Google Scholar] [CrossRef]
- Liu, Z.; Tan, Y.; He, Q.; Xiao, Y. SwinNet: Swin transformer drives edge-aware RGB-D and RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4486–4497. [Google Scholar] [CrossRef]
- Huo, F.; Zhu, X.; Zhang, Q.; Liu, Z.; Yu, W. Real-time one-stream semantic-guided refinement network for RGB-thermal salient object detection. IEEE Trans. Instrum. Meas. 2022, 71, 2512512. [Google Scholar] [CrossRef]
- Huo, F.; Zhu, X.; Zhang, L.; Liu, Q.; Shu, Y. Efficient context-guided stacked refinement network for RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3111–3124. [Google Scholar] [CrossRef]
- Levinshtein, A.; Sereshkeh, A.R.; Derpanis, K. DATNet: Dense Auxiliary Tasks for Object Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1419–1427. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Wang, Y.; Zhang, L.; Wang, L.; Wang, Z. Multitask learning for object localization with deep reinforcement learning. IEEE Trans. Cogn. Dev. Syst. 2018, 11, 573–580. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Johansen, A.S.; Junior, J.C.J.; Nasrollahi, K.; Escalera, S.; Moeslund, T.B. Chalearn lap seasons in drift challenge: Dataset, design and results. In Proceedings of the Computer Vision–ECCV 2022 Workshops, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part V.. Springer: Berlin/Heidelberg, Germany, 2023; pp. 755–769. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13619–13627. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A comprehensive survey of loss functions in machine learning. Ann. Data Sci. 2020, 9, 187–212. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wang, B.; Lu, J.; Yan, Z.; Luo, H.; Li, T.; Zheng, Y.; Zhang, G. Deep uncertainty quantification: A machine learning approach for weather forecasting. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2087–2095. [Google Scholar]
- Wortsman, M.; Ilharco, G.; Gadre, S.Y.; Roelofs, R.; Gontijo-Lopes, R.; Morcos, A.S.; Namkoong, H.; Farhadi, A.; Carmon, Y.; Kornblith, S.; et al. Model soups: Averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 23965–23998. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MR | |||||
|---|---|---|---|---|---|---|
| YOLOv5 (Baseline) | 0.604 | 0.465 | 0.825 | 0.640 | 0.491 | 0.342 |
| YOLOv5 (Pretrain) | 0.600 | 0.454 | 0.831 | 0.621 | 0.489 | 0.324 |
| YOLOv5 (Temp.) | 0.584 | 0.410 | 0.796 | 0.590 | 0.468 | 0.322 |
| YOLOv5 (Hum.) | 0.493 | 0.293 | 0.675 | 0.560 | 0.268 | 0.357 |
| YOLOv5 (ToD) | 0.549 | 0.439 | 0.805 | 0.566 | 0.431 | 0.356 |
| DN-DETR Baseline | 0.378 | 0.348 | 0.123 | 0.344 | 0.563 | 0.421 |
| DN-DETR (Temp.) | 0.225 | 0.148 | 0.100 | 0.190 | 0.682 | 0.389 |
| DN-DETR (Hum.) | 0.191 | 0.132 | 0.100 | 0.160 | 0.671 | 0.415 |
| DN-DETR (ToD) | 0.219 | 0.142 | 0.00 | 0.169 | 0.661 | 0.410 |
| Def. DETR Baseline | 0.332 | 0.202 | 0.005 | 0.051 | 0.637 | 0.383 |
| Def. DETR (Temp.) | 0.297 | 0.184 | 0.001 | 0.045 | 0.620 | 0.351 |
| Def. DETR (Hum.) | 0.213 | 0.114 | 0.000 | 0.020 | 0.517 | 0.416 |
| Def. DETR (ToD) | 0.289 | 0.178 | 0.001 | 0.040 | 0.619 | 0.395 |
| Model | MAE | MAPE | Std. | |
|---|---|---|---|---|
| Dir. | Temperature | 7.1 | 18% | 3.7 |
| Humidity | 18.9 | 49% | 9.4 | |
| Time of Day | 7.3 | 19% | 7.1 | |
| Indir. | Temperature | 5.1 | 14% | 2.9 |
| Humidity | 15.3 | 43% | 8.9 | |
| Time of Day | 8.3 | 22% | 7.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Johansen, A.S.; Nasrollahi, K.; Escalera, S.; Moeslund, T.B. Who Cares about the Weather? Inferring Weather Conditions for Weather-Aware Object Detection in Thermal Images. Appl. Sci. 2023, 13, 10295. https://doi.org/10.3390/app131810295
Johansen AS, Nasrollahi K, Escalera S, Moeslund TB. Who Cares about the Weather? Inferring Weather Conditions for Weather-Aware Object Detection in Thermal Images. Applied Sciences. 2023; 13(18):10295. https://doi.org/10.3390/app131810295
Chicago/Turabian StyleJohansen, Anders Skaarup, Kamal Nasrollahi, Sergio Escalera, and Thomas B. Moeslund. 2023. "Who Cares about the Weather? Inferring Weather Conditions for Weather-Aware Object Detection in Thermal Images" Applied Sciences 13, no. 18: 10295. https://doi.org/10.3390/app131810295