
Local Optima Network Analysis of Multi-Attribute Vehicle Routing Problems

1
Departamento de Ingeniería Industrial, Universidad Católica de la Santísima Concepción, Alonso de Ribera 2850, Concepcion 4090541, Chile
2
Facultad de Ingeniería y Ciencias, Universidad Adolfo Ibáñez, Av. Diagonal las Torres 2640, Santiago 7941169, Chile
3
Escuela de Informática y Telecomunicaciones, Facultad de Ingeniería y Ciencias, Universidad Diego Portales, Av. Ejército Libertador 441, Santiago 8370191, Chile
4
Faculty of Applied Mathematics, AGH University of Science and Technology, al. A. Mickiewicza 30, 30-059 Krakow, Poland
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
‡
Current address: Facultad de Ingeniería y Ciencias, Universidad Diego Portales, Av. Ejército Libertador 441, Santiago 8370191, Chile.
Mathematics 2022, 10(24), 4644; https://doi.org/10.3390/math10244644
Submission received: 22 November 2022
/
Revised: 2 December 2022
/
Accepted: 5 December 2022
/
Published: 8 December 2022
Abstract
:Multi-Attribute Vehicle Routing Problems (MAVRP) are variants of Vehicle Routing Problems (VRP) in which, besides the original constraint on vehicle capacity present in Capacitated Vehicle Routing Problem (CVRP), other attributes that model diverse real-life system characteristics are present. Among the most common attributes studied in the literature are vehicle capacity and route duration constraints. The influence of these restrictions on the overall structure of the problem and the performance of local search algorithms used to solve it has yet to be well known. This paper aims to explain the impact of constraints present in different variants of VRP through the alterations of the structure of the underlying search space that they cause. We focus on Local Optima Network Analysis (LONA) for multiple Traveling Salesman Problem (m-TSP) and VRP with vehicle capacity (CVRP), route duration (DVRP), and both (DCVRP) constraints. We present results that indicate that measures obtained for a sample of local optima provide valuable information on the behavior of the landscape under modifications in the problem’s constraints. Additionally, we use the LONA measures to explain the difficulty of VRP instances for solving by local search algorithms.
Keywords:
local optima network; vehicle routing problem; multiple traveling salesman problem; network analysis; fitness landscape analysisMSC:
68T20; 90B061. Introduction
The great variety of Vehicle Routing Problems (VRP) applications present in real life situations is a challenge for research. Organizations operate with diverse particular business rules that have to be represented in the chosen VRP model in order to obtain actionable solutions. Each variant is related to some new attributes added to the Multiple Traveling Salesman Problem (m-TSP) [1], thus modifying its structure. Variants of VRP with at least two attributes are called Multi-Attribute Vehicle Routing Problems (MAVRP). Given the vast body of research on solving MAVRP with different techniques depending on the variant, classification methods are needed to help algorithm developers navigate this diversity.
From the solution methods point of view, Vidal et al. [2] distinguishes three main classes of attributes, considering essential aspects involved in providing a solution to a VRP variant that attempts to model a real life situation: assignments of customers and routes to resources (Assignment), choices of customer visit sequences within routes (Sequence) and evaluations of fixed routes (Evaluation). Cáceres et al. [3] summarize several attribute classifications proposed in the literature. The systematization of attributes proposed by Vidal (above the others) highlights relationships between models and points towards the adjustments to the solution method needed when moving from one model to another.
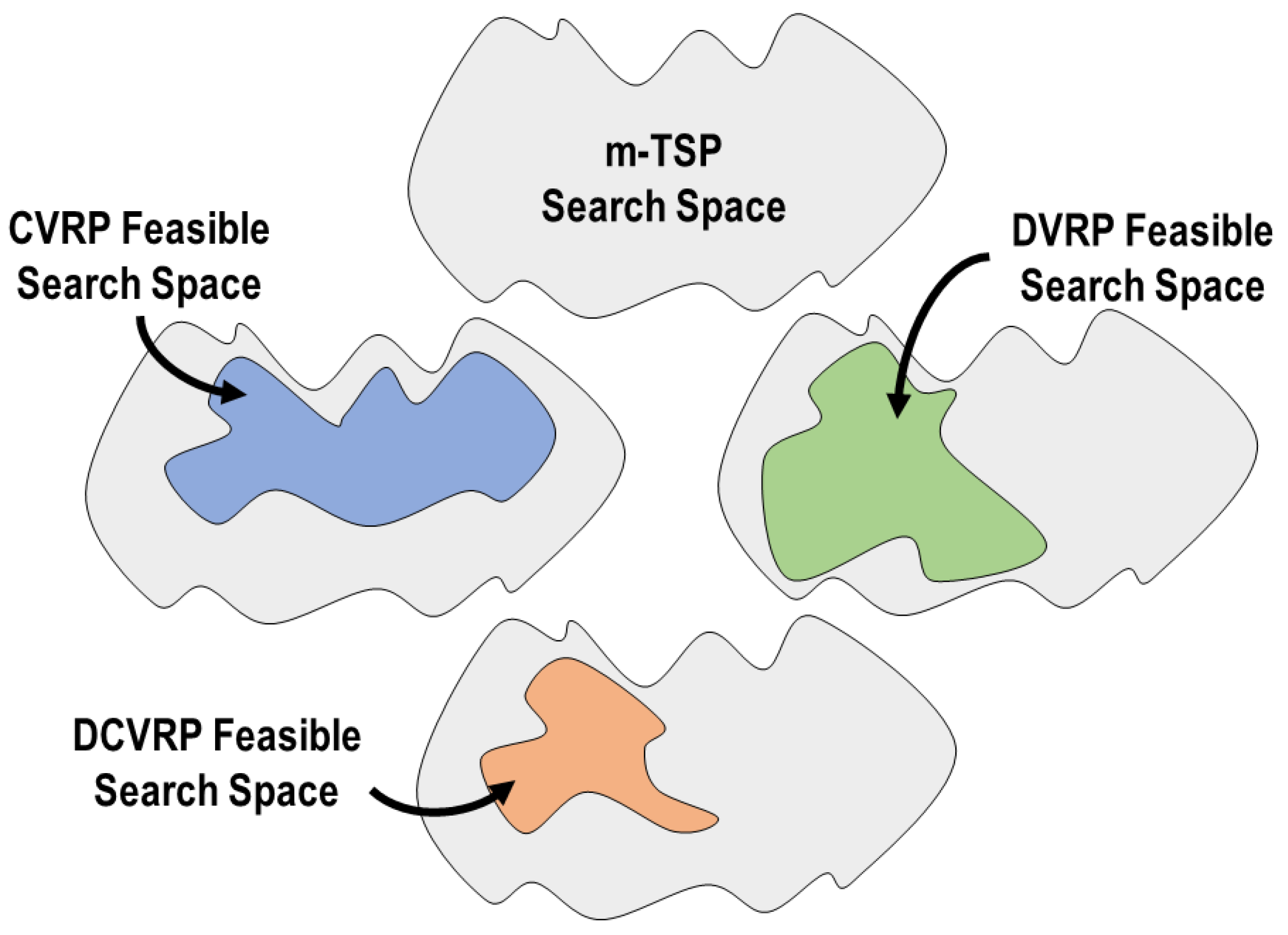
The competitive paradigm [4] has fostered development of many algorithms based only on good empirical performance results. The predominant approach is to argue that a new algorithm is better only because it achieves better results on some standard benchmark instances. The main weakness of this approach, when not accompanied by other methodologies, is that it does not help to understand why an algorithm works well and when it will not be suitable for a specific problem or instance. Fitness Landscape Analysis (FLA) generates an environment to address this deficiency. It aims not to design a new algorithm with better empirical performance, but to explain the behavior of an algorithm based on some properties of the fitness landscape on which it is executed. This is the approach we take in this paper. We aim to explore the impact of vehicle capacity and route duration constraints (see Figure 1) on the overall structure of the search space and on the performance of heuristic algorithms based on local search.
The literature on FLA for VRP is scarce. In particular, to the best of our knowledge, in the context of FLA, our previous research [5] presented the first article to explicitly analyze different levels of constraints in medium-size VRP instances. Other authors have studied the effect of constraints on small instances [6]. The paper analyzed different levels of vehicle capacity in CVRP and ways in which their impact on the search space can be studied with local measures of FLA. In the present paper we expand and complement these results by studying interactions of two VRP attributes (vehicle capacity and route duration constraints), and by using FLA measures of a more global character, as the Local Optima Network Analysis (LONA) measures. In LONA, characteristics of fitness landscapes are studied using a projection in a space formed by the local optima. Thus, the state space is reduced by moving from the solution level (micro scale) with a huge number of solutions to a reduced one (macro/global scale) composed only of local optima.
The paper is structured as follows: Section 2 presents the Mixed Integer Programming (MILP) formulations of the VRP variants studied in this research. Section 3 present some background on Fitness Landscape Analysis (FLA) and leading theories on the structure of fitness landscapes in combinatorial problems, especially from the point of view of Local Optima Network Analysis (LONA). Section 4 describes our experimental design aimed at understanding, with the help of LONA measures, performance of heuristics based on local search when applied to instances of VRP. Section 5 gives the results of Repeated Measures ANOVA applied to determine differences between variants and constraint levels in the measures obtained for LONA. Additionally, we present a bivariate analysis between LONA measures and the heuristic performance; Finally, we present some results related to estimating the difficulty of instances for local search algorithms based on LONA measures and some trends discovered in the data. Section 6 gives a brief discussion of the main contributions of the paper, which include the following:
- To explain the effect of increasing the constraint levels for vehicle capacity and route duration attributes using LONA measures.
- To explore the effect of vehicle capacity and route duration constraints in a Multi-Attribute Vehicle Routing Problem case (DCVRP).
- To predict the difficulty of VRP instances to be solved by local search algorithms using LONA measures.
2. Integer Linear Programing Formulations
Consider the classical Traveling Salesman Problem (TSP) in its multiple-salesmen version (m-TSP) [1], where each customer must be visited exactly once, using one vehicle k of the fleet K of independent vehicles that are available at the central depot. Let V denote the set of points of interest: customers and the central depot 0. The objective is to perform the visits with the minimum total distance travelled, where denotes the distance between the points of interest i and j. In the instances that we study, the distance matrix c is symmetric and corresponds to the Euclidean distances between points on the plane. Binary decision variables indicate that the point of interest j is visited immediately after i by vehicle k if , and otherwise if . The following gives one possible formulation of m-TSP.
subject to:
The objective function (1) minimizes the total cost. Expressions (2) ensure that each customer is visited exactly once by a vehicle. Constraints (3) mean that vehicle k leaves customer h if and only if vehicle k arrives at customer h. Constraints (4) indicate that each vehicle leaves the depot exactly once. In (5), sub-tour elimination constraints are applied: Vehicle k does not cycle among the customers in S (with no visit to the central depot). Finally, constraints (6) ensure the nature of the decision variables.
Capacitated Vehicle Routing Problem (CVRP) is one of the most extensively studied extensions of m-TSP, in which each customer has a demand and each vehicle has a limited capacity Q. Thus, CVRP adds to the m-TSP formulation the constraints (7) that ensure that the vehicle capacity is not exceeded on any route [7].
Another common variant of VRP, Distance-constrained Vehicle Routing Problem (DVRP), has a constraint on route duration. This constraint implies that vehicles cannot take routes that exceed a total distance L. The formulation presented by Christofides et al. [7] adds the following constraint to the m-TSP:
3. Background on Fitness Landscape and Local Optima Network Analysis
For ease of presentation, let us focus in the general descriptions that follow on the case of local search used for maximization problems. Given an instance of a problem, let X be its set of solutions, also called the solution space. Let f be the objective function of the problem, also called its fitness function. Finally, let N be the neighborhood function defined by the local operator used for local search, i.e., a solution y belongs to the neighborhood of a solution x if and only if y can be obtained from x by a single application of the local operator. Putting these three together, the triplet is the fitness landscape of the instance [8]. The notion of a fitness landscape is based on a metaphor commonly used to describe the dynamics of evolutionary algorithms. It considers the solution space together with the neighborhood function to define the search space, over which a landscape surface is defined by the fitness function (height of the solution).
Fitness landscape analysis has been used in different contexts and purposes, from explaining the behavior of algorithms to automated algorithm selection and configuration. Malan et al. [9,10] have conducted two comprehensive reviews of different techniques developed to study fitness landscapes. Contrasting the reviews indicates an evolution of the field from theoretical to more application-focused approaches. Among the types of FLA applications found in the literature, we would like to highlight the following:
- Algorithm performance prediction. Generally, the behavior of a metaheuristic is unpredictable, i.e., we have no formal guarantees on its performance, and it is challenging to predict it when applied to a specific instance. Thus, FLA can be helpful when searching for patterns or general characteristics of problems or instances that can be used as input for performance prediction.
- Understanding complex problems. The approach is based on characterizing problems based on features measured in the underlying fitness landscapes. The central hypothesis motivating this approach is that algorithms or sets of algorithms can have similar behavior on similar problems. Various combinatorial problems, including the VRP family, have been studied under this approach.
- Automated algorithm selection and configuration. Two important tasks are complementary to the analysis of performance of an algorithm: (1) selection of the best algorithm to solve a problem, and (2) selection of the values of the parameters used in a given algorithm. Both propose to search for the best alternative to improve algorithmic performance for solving a given problem. Either approach can benefit from the knowledge that can be extracted from FLA.
In this context, the approach of Local Optimal Network Analysis (LONA) is highlighted by Malan [10], as it focuses on the global structure of landscapes and could help understand the behavior of local-search-based algorithms. Malan emphasizes that the broad field of practical application and the evolution of LONA have made it one of the most widely used FLA techniques.
3.1. Local Optima Network Analysis
3.1.1. Representation and Local Operator
For Vehicle Routing Problems, several encodings of solutions are used in search algorithms. The Delimiters representation, one of the most commonly used in the literature, corresponds directly to a set of k individual routes. For a problem with vehicles, this representation considers an array that contains one substring per trip and copies of the depot used as trip delimiters [15]. For example, the solution represents two routes: In the first, the route starts from the depot, then visits customers one and two, to end at the central depot; In the second, the route starts from the depot to then sequentially visit customers three and four, and conclude at the depot. Note that, as in the three-index-based VRP Mixed Integer Linear Programming (MILP) formulations, the routes/vehicles are distinguishable. Similarly, it is essential to recognize the relationship between the feasible search space, i.e., the search space restricted to feasible solutions, obtained with the Delimiters representation and the set of feasible solutions for the MILP formulations for all variants presented in the paper.
The Delimiters representation supports the application of the original operators developed for TSP and their modifications for VRP. In this context, a specific local operator defines the neighborhood associated to a solution x. The function N maps any solution to the set of solutions that can be obtained from x by a single application of the local operator. If , then y is a neighbor of the solution x. One of the most common local operators for the VRP is Relocate, which consists of removing a client from its current position and placing it in another. This movement is executed within the same route (intra-route) or between two different routes (inter-route). For more details, Braysy and Gendreau [16] present a review of the main local operators for VRP.
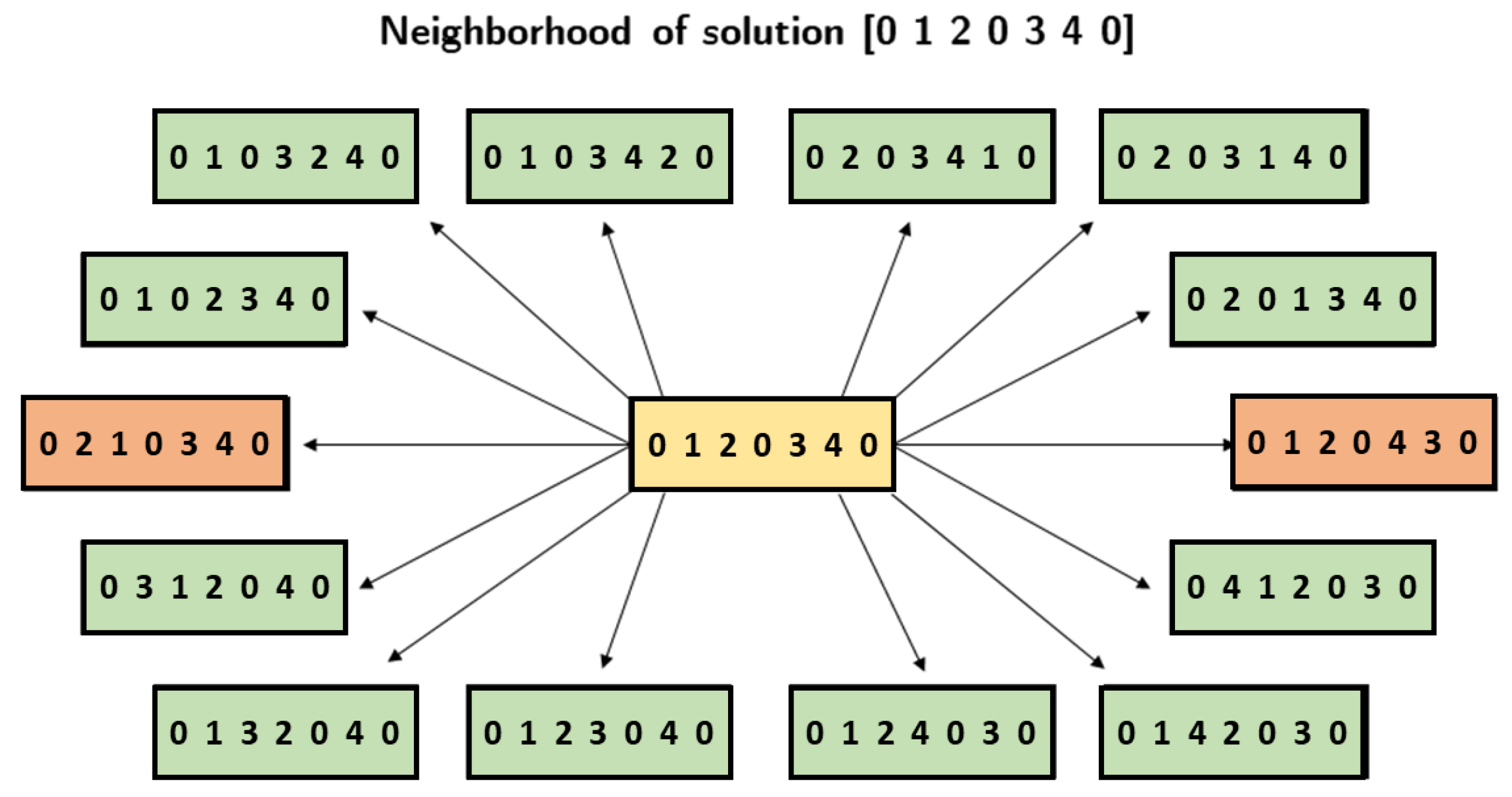
For this article, consider that the solutions of the VRP variants are encoded under the Delimiters representation, and the construction of new solutions is only performed by applying the Relocate operator (Figure 2).
3.1.2. Adjacency of Basins of Attraction
Consider an instance of a maximization problem that has n local optima . The basin of attraction of each local optimum is defined as , where h is an operator that associates a local optimum to every solution s. For example, it is common to consider that is the fixed point obtained by iteratively applying a hill-climbing algorithm starting from s until reaching convergence. The local optima network of this instance is defined as a weighted graph , where the vertex set V is the set of local optima, and the set of edges E represents the adjacency of the corresponding basins of attraction.
There are two main ways of defining adjacency of basins of attraction described in the literature:
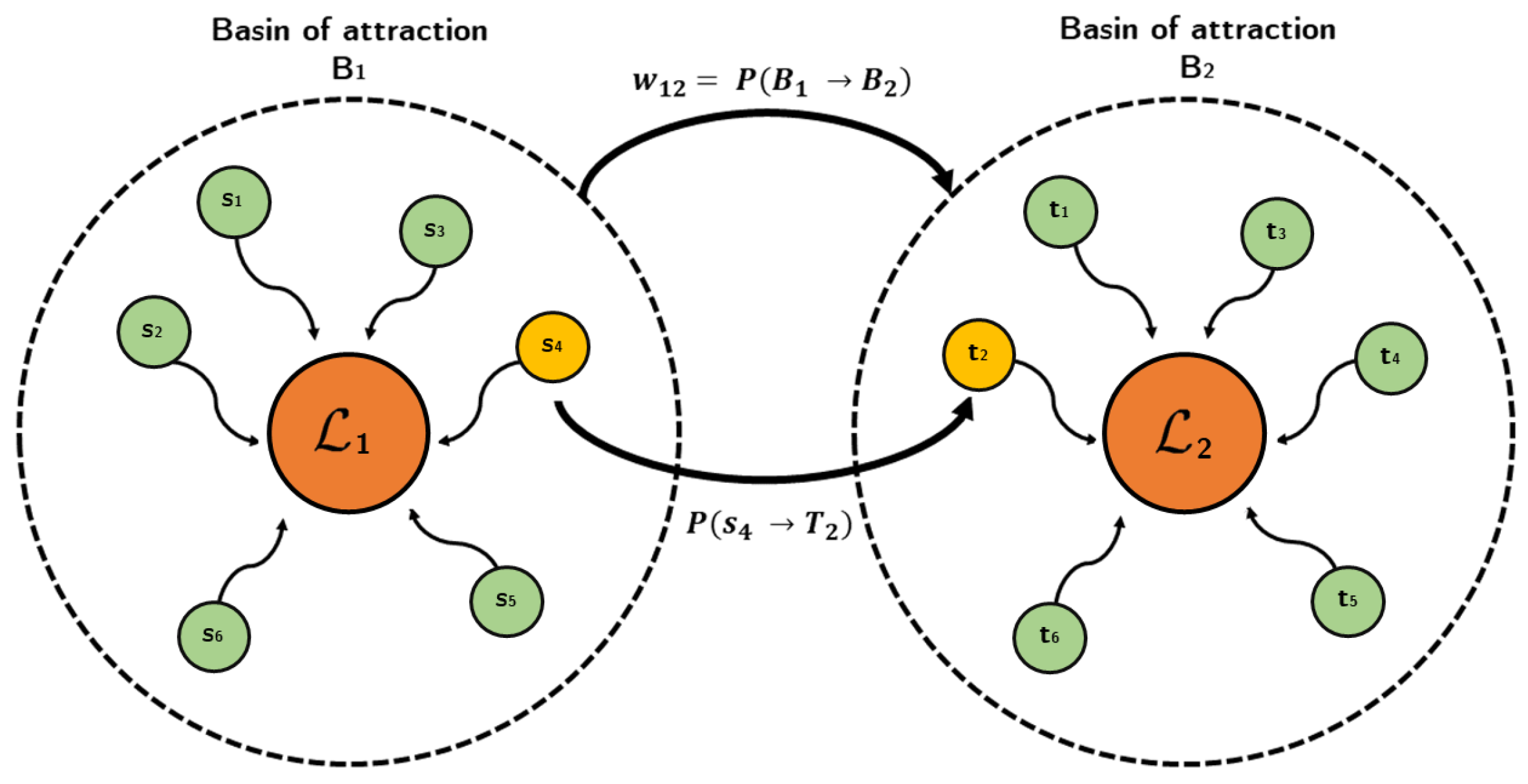
- Basins-transitions requires a complete analysis of the basins of attraction of each local optimum . To exemplify, consider two basins of attraction and , as shown in Figure 3, corresponding to the local optima and , respectively. Likewise, note that the solutions s reach the local optimum by applying the hill-climbing algorithm, just as the solutions t reach . Note that both solutions s and t belong to the solution space S, and that the basins of attraction generate a partition over S such that: and .
The arc from the local optimum to exists if and only if there exist and such that . In this case, the transition probability of passing from a solution to a solution is if , and otherwise . Moreover, the probability of transition from a solution to the basin of attraction is computed by summing up the individual transition probabilities of with each solution belonging to . Finally, the weight of the arc is the average transition probability to of the solutions in .
- 2.
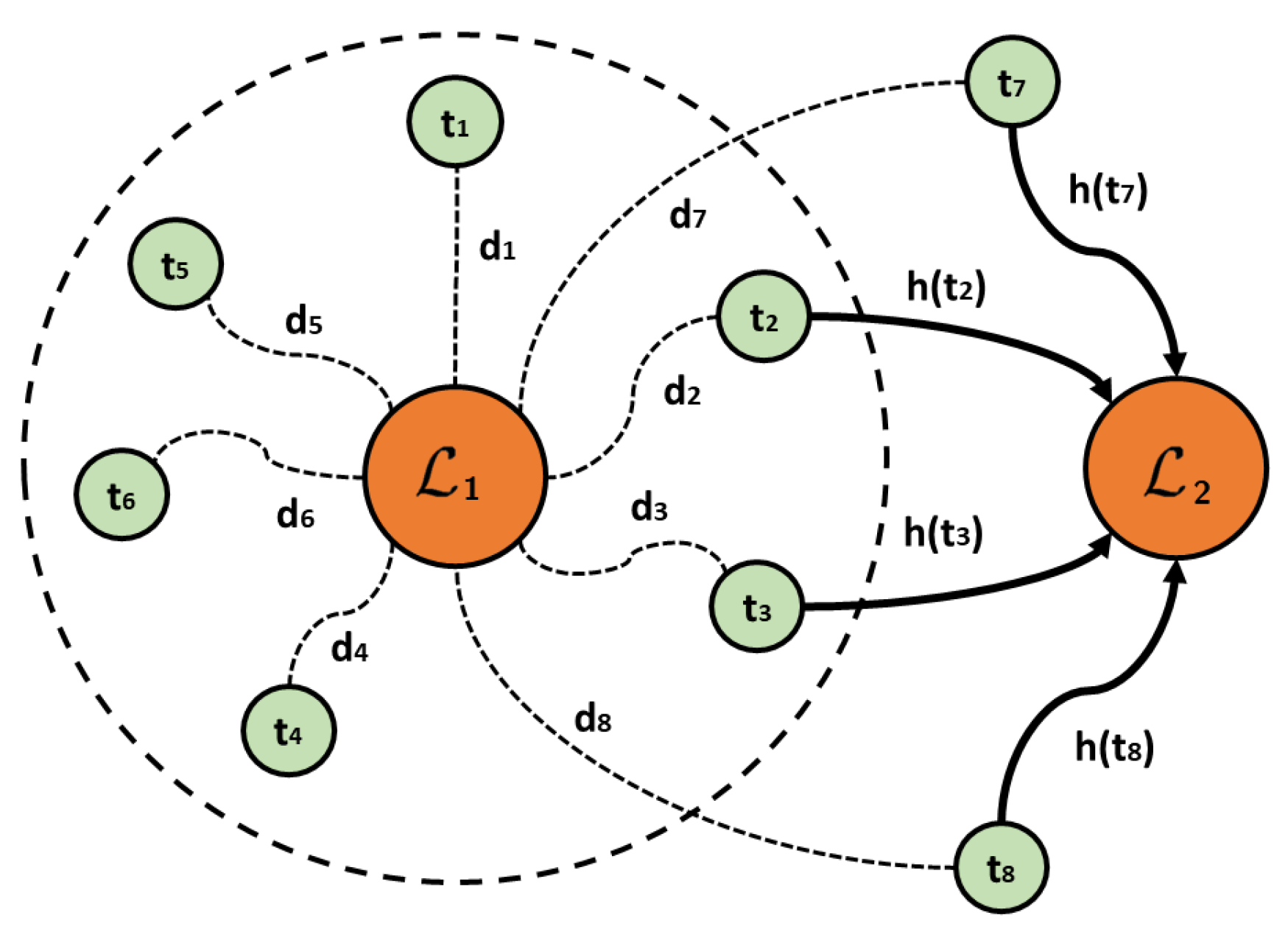
- Escape-edges is based on the distance between each pair of local optima. This new way of establishing the adjacency relationship between local optima was proposed to solve the problem of producing very dense networks that required exhaustive sampling of the basins of attraction. The weights based on Escape-edges do not require a complete calculation of the basins of attraction [17]. The weights are defined according to a distance function d (minimum number of moves between two solutions) and a positive integer . The edge between and exists only if there exists a solution t such that and . The weights are established by counting the number of solutions that are in the basin of attraction of and at a distance less than or equal to D from . The number of solutions that satisfy this condition is normalized by the total number of solutions at a distance less than or equal to D from (regardless of whether they belong to the basin of attraction of ). Figure 4 presents a schematic of the relationship between local optima using transitions based on Escape-edges.
Local Optima Network Analysis (LONA) is a topic in the literature on Fitness Landscape Analysis (FLA) of combinatorial problems that has started to be studied only recently. The problem that has been studied with LONA techniques the most is the NK model. It was used by Ochoa et al. [18] to introduce LONA, and has been studied later for further advances in the development of this tool. In the case of the Quadratic Assignment Problem, Chicano et al. [19] used LONA to predict the performance of search algorithms. With the same motivation of performance prediction, Pavelski et al. [20] used LONA to study two Iterated Greedy algorithms for the Flow Shop Scheduling problem. Chicano et al. [21] proposed the same for the MAX-3SAT problem. In the context of VRP, Ochoa et al. [22] performed a mapping of the global structure for TSP, showing that the difficulty of the search is related to the presence of multiple funnels in the landscape. Additionally, they reported high levels of neutrality. For VRP variants and practical uses of LONA, Lipinski et al. [23] present an evolutionary algorithm for solving the Inventory Routing Problem (IRP), which includes an improvement mechanism based on Simulated Annealing that consists of calculating the transition probabilities obtained with LONA and using them to guide the search.
4. Methods
This section presents the main aspects of the experimental design we use for studying different VRP variants under multiple constraint levels: (a) construction of instances for each problem, (b) creation of local optima networks, (c) computation of LONA measures, (d) computation of measures related to the difficulty in local search, and (e) analysis of relationships between the LONA measures and the difficulty of local search.
4.1. Instance Creation
To analyze the role of constraints, we create new experimental instances based on 61 base instances taken from the literature. They are selected among the base instances used in our previous study [5] by the criterion of having at most 60 nodes. For each base instance, we create a feasibility sample of m-TSP solutions where each Delimiter representation is chosen uniformly at random, with the depot 0 repeated times, where k is the number of vehicles. The sample thus obtained is used to compute four constraint levels for each restriction (vehicle capacity and route duration) as described in the following:
- For CVRP, for each base instance, we create an experimental instance at 4 levels: Level 0 where all m-TSP solutions are feasible; Level 1 in which 75% of m-TSP solutions are feasible; Level 2 such that 50% of m-TSP solutions are feasible; and Level 3 where 25% of m-TSP solutions are feasible. For each base instance, we choose the minimum capacity for which the required proportion of the respective feasibility sample is feasible for CVRP.
- For DVRP, we proceed like for CVRP, only considering restrictions on route durations instead of vehicle capacities. We also create experimental instances at 4 levels: Level 0 where all solutions are feasible for DVRP, Level 1 in which 50% of the solutions are feasible), Level 2 such that 30% of the solutions are feasible, and Level 3 where 10% of the solutions are feasible.
- For the DCVRP case, we create only one experimental instance for each base instance. We set both the vehicle capacity and the route duration at the value that comes from the corresponding Level 3. Note that, unlike the cases of CVRP and DVRP in which the proportion of feasible solutions is pre-set, in DCVRP experimental instances this proportion changes from one to another.
From the formal point of view, an m-TSP instance considers only the locations of the customers (or the distances between them) and the number of vehicles. For CVRP, the customer demands and the vehicle capacity are incorporated. In DVRP, we add the maximum route length. Finally, for DCVRP, the features of DVRP and CVRP are incorporated together. However, Level 0 experimental instances for CVRP and DVRP based on a fixed base instance have the same feasible solutions with the same value of the objective function, in spite of formally corresponding to different instances (of different problems). Thus, they yield the same fitness landscape. Adopting the point of view of fitness landscapes, such two experimental instances are considered the same for our analysis. So, based on 61 base instances, we create the following: 61 experimental instances for Level 0, 366 experimental instances for Levels 1, 2, and 3 of CVRP and DVRP, and 61 experimental instances for DCVRP. In total, we get 488 experimental instances.
We create several datasets to achieve the research objectives: The main is the MAVRP dataset [24] containing all the measurements taken on the local optima network and the local search behavior for each one of the 488 experimental instances. The CVRP dataset is obtained from the MAVRP dataset by considering only the 244 experimental instances relevant for analyzing CVRP: Levels 0 through 3 for CVRP. In an analogous way, the DVRP dataset considers the 244 experimental instances relevant for DVRP. Finally, the DCVRP dataset is based on 183 experimental instances: Level 3 for CVRP and DVRP, and the DCVRP experimental instances.
4.2. Local Optima Network Construction
4.2.1. Nodes: Local Optima
For each experimental instance, we consider a random feasible solution sample of solutions where each Delimiter representation is chosen uniformly at random, with the depot 0 repeated times, where k is the number of vehicles. However, we keep the solution only if it is feasible for the experimental instance. Each element of the feasible solution sample is used as the initial solution for the First-Improvement hill-climbing algorithm (Algorithm 1) to obtain the corresponding local optimum. We use to denote the local optima sample, the set of local optima thus obtained.
| Algorithm 1 First-Improvement Hill-Climbing |
| procedure First-Improvement Hill-Climbing initial solution while x is not a Local Optimum do random solution from if then end if end while end procedure |
4.2.2. Edges: Relocate Distance
Most local operators that have been defined in the literature on local-search-based algorithms for VRP are inspired by those used for TSP [16]. The majority of them are symmetric, i.e., if a solution y can be obtained by one application of the local operator to a solution x, then the same holds in the opposite direction. And it is the case for the Relocate operator considered in this research.
Each local operator is associated to a notion of distance. Given two solutions x and y, the corresponding distance is the minimum number of applications of the local operator necessary to transform x into y. In other words, computing corresponds to computing a shortest path from x to y in the corresponding search space.
For many local operators, the corresponding distances in the TSP search space can be computed efficiently (e.g., such is the case for the Relocate and Exchange operators), which results in their wider use. But in some cases computing the corresponding distance is NP-hard (e.g., it holds for the distance based on 2-Opt). The reader is referred to the survey by Schiavinotto and Stützle [25] for more details (therein, Relocate, Exchange and 2-Opt are called insert, interchange and 2-edge-exchange, respectively). These complexity results can be easily adapted to the versions of these operators for m-TSP, thus computing the distance in a m-TSP space is polynomial for Relocate and Exchange, whereas it is NP-hard for 2-Opt.
Constraining the search space tends to make computing the distance harder. For example, computing a shortest path between two solutions of TSP in the search space generated by 2-Opt is “only” NP-complete when any solution can be visited along the way. Adding a restriction that only TSP routes of duration at most a certain constant K can be visited along the way makes the problem of computing a shortest path PSPACE-hard. This can be seen with a simple reduction from the Hamiltonian Cycle Reconfiguration problem based on 2-Opt, that was proved by Takaoka [26] to be PSPACE-complete. Thus computing the 2-Opt distance in DVRP is PSPACE-hard.
Up to out knowledge, no results on the complexity of reconfiguration for Hamiltonian Cycle (or other VRP variants) with other local operators have been published. Nevertheless, we believe that computing the distances based on Relocate or Exchange in the solution space of DVRP, CVRP or DCVRP is at least NP-hard. This intuition comes from the fact that even reconfiguration problems based on very simple optimization problems tend to be hard. For example, the Shortest Path problem in general unweighted graphs can be solved in linear time (for example, using Breadth-First Search), but the Shortest Path Reachability problem (its reconfiguration version) is PSPACE-complete event when limited to unweighted graphs of bounded bandwidth [27]. For this reason, we limit ourselves to computing the distances between solution in the underlying m-TSP space even when working with DVRP, CVRP or DCVRP.
In this research, we analyze search spaces based on the Delimiters representation and the Relocate operator. Sörensen and Schittekat [15] described in depth the use of the Relocate Distance based on the Delimiters representation for VRP. Consequently, for each experimental instance, we built the corresponding local optima network as follows:
- We take the corresponding local optima sample and construct a complete graph using every local optimum as vertex and every pair of local optima as edge . Then, we calculate the Relocate Distance for every pair of local optima.
- We delete every edge for which . The parameter D is set to the percentile 25 (first quartile) of all the distances computed in the step 1.
Note that the local optima network is undirected, because the distances between the local optima are symmetric.
4.3. Local Optima Network Analysis: Measures
4.3.1. Measure 1: Density
The Density measure presented in Equation (9) is defined as the ratio of observed edges to the number of possible edges for a given network. Let denote the order of a network, which refers to the number local optima. The number of all possible edges for an undirected network of order is . Let be the number of edges in the network. Then, Density can be expressed as:
4.3.2. Measure 2: Transitivity
Transitivity, also known as Clustering Coefficient is a measure of the tendency of the nodes to cluster together. Perfect transitivity implies that, if local optimum is connected (through an edge) to local optimum , and is connected to local optimum , then is connected to as well. The Clustering coefficient T of a network is the average clustering coefficient for all local optima in the network; Thus, the computation of T is as follows:
is the number of triangles through local optimum and is the degree of . implies perfect transitivity, i.e., a network whose connected components are all cliques. implies no triangles (transitive relations) in the network.
4.3.3. Measure 3: Assortativity
Assortativity measures the tendency of similar local optima to be grouped. In this work, we measure Assortativity based on node degree of each local optimum . Let be the degrees of the corresponding local optima in the network. Then, we define the following parameters:
- Mixing matrix represents the number of edges from nodes with degree to nodes with degree .
- Degree correlation matrix represents the probability of finding nodes with degrees and as the two ends of an edge selected at random. Thus, .
- Degree probability is the probability that there is a node with degree at the end of the randomly selected edge. Thus, .
The Assortativity can be described using the Degree Correlation Coefficient A proposed by Newmann (citar), that is defined as:
Hence, A is the Pearson correlation coefficient between the degrees found at the two end of the same edge. For the network is assortative, for the network is neutral and for the network is disassortative.
4.3.4. Measure 4: Distance Ratio
The Distance Ratio estimates the closeness between local optima. For this, we calculate the median distance () between the local optima and normalize using the diameter of the search space (equal to the number of customers ). Thus, networks constructed from different instances of the VRP are comparable. Therefore, the Distance Ratio (DR) computation is as follows:
Consequently, the closer DR is to zero, the closer the local optima of the network tend to be to each other.
4.3.5. Measure 5: Quality of Local Optima Sample
The Hill-Climbing Gap (HC-Gap) measure explores the quality of the local optima sample. We use the Lin–Keninghan–Helgsaun (LKH) algorithm and extensions [28] to estimate the global optimum for each experimental instance (the best of ten runs). The solution obtained with LKH on m-TSP, CVRP, and DCVRP instances offers a sufficiently good (potentially optimal) benchmark to measure the quality of other solutions. The benchmark results presented in the cited reports indicate that the LKH algorithm achieved the best-known or new best solutions for 96.85%, 72.88%, and 81.81% of m-TSP, CVRP and DCVRP instances tested, respectively. Moreover, the experiments presented by Helgsaun cover computationally more challenging instances than those used in this research. The computation of the Gap measure (%) relates the median fitness value of the local optima sample computed with First-Improvement Hill-Climbing () and the best fitness value of LKH solutions () using the following definition:
Thus, better quality solutions have a HC-Gap(%) close to zero.
4.3.6. Measure 6: Number of Steps to Local Optimum
The Number of steps to local optimum , executed when applying First-Improvement Hill-Climbing, estimates the closeness between local optima and their respective starting points . To compute the Steps measure for an experimental instance, we use the median , over the feasible solution sample , of the number of steps performed by the local-search-based algorithm to reach the respective local optimum. Similarly to the Distance Ratio measure, the number of steps is adjusted considering the diameter of the search space in the respective instance. So we get the following formula:
Consequently, the closer Steps is to zero, the closer the local optima of the network tend to be to their respective starting points.
4.3.7. Measure 7: Dispersion
The Dispersion measures the variability of fitness values of the local optima in the network. We use the Dispersion Coefficient based on the coefficient of variation. The DC is the ratio between the standard deviation and the mean of the fitness in the local optima sample. The coefficient of variation is applicable in our research because it is dimensionless (i.e., independent of the measurement unit) and is, therefore, comparable between experimental instances.
Hence, when is close to zero, the local optima tend to have similar fitness values.
4.4. Performance Measure: Difficulty for Local Search
The Simulated-Annealing Gap (SA-Gap) measure explores the performance of local search algorithms. As we did for computing the HC-Gap, we use the Lin–Keninghan–Helgsaun (LKH) algorithm and extensions to compute the SA-Gap measure (%). The measure relates the median fitness value of twenty runs computed with Simulated Annealing () and the best fitness value of LKH solutions () using the following definition:
Thus, a SA-Gap(%) close to zero implies a better algorithmic performance.
We generate an initial solution for SA from a permutation of the customers chosen uniformly at random (TSP solution space), by applying a Split algorithm [5,29]. Then, with each move, a neighboring feasible solution is chosen—as is usual in SA algorithms for VRP. We propose an SA parametrization that uses an initial temperature , and the temperature varies across the iterations using a linear cooling schedule with a fixed cooling rate t = 0.9 [30]. For each temperature, the algorithm performs iterations.
4.5. An Example of LONA and Performance Measures
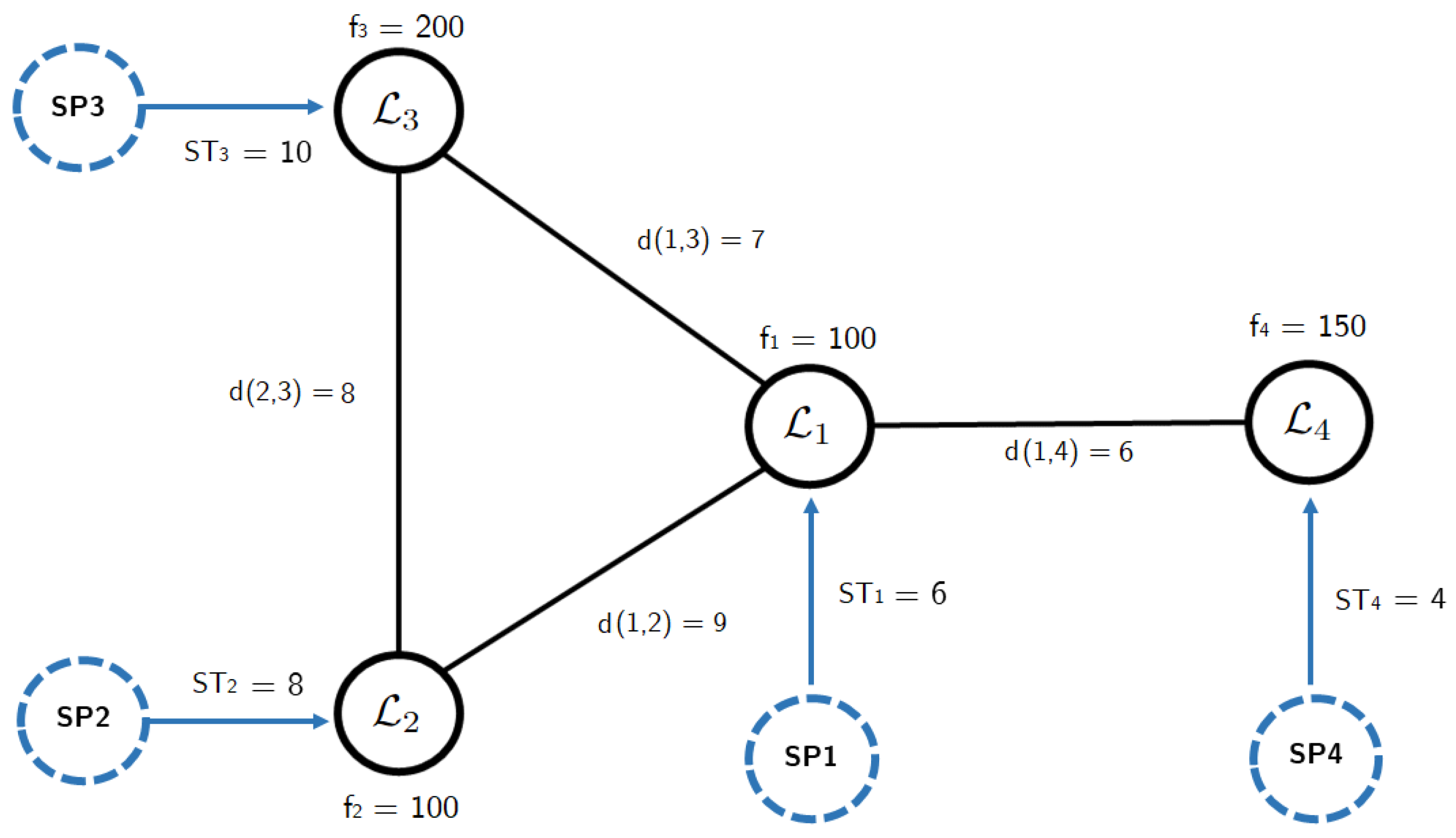
Consider the local optima network presented in Figure 5, which is based on a local optima sample of , , , obtained from a feasible solution sample of , , , . The local optima network has edges: , , , . It is obtained for a VRP instance with ten customers.
The fitness levels of the local optima are , representing the node weights; and the respective edges have weights determined by the relocate distance between the corresponding local optima, as shown in Figure 5. Moreover, the median fitness value of twenty runs computed with Simulated Annealing is . Thus, the LONA and Performance measures would be calculated as follows:
- Density (DS): The number of arcs that could exist in the network is six, equivalent to . In the network shown in Figure 5, only four of the six possible arcs exist, so the network density is .
- Transitivity (T): The transitivity coefficient corresponds to the fraction of triads that are closed. In the above example, for instance, there are five triads: one centered at , one at , and three at . Three of them are closed triads (centred in , and , respectively), and two are open (both centred in ). Hence the transitivity coefficient is
- Assortativity (A): To calculate the assortative coefficient, it is necessary to calculate the degree of each node and relate it to adjacent ones (see Table 1). In this case, the relationship between the degrees of neighboring nodes is inversely proportional, indicating a disassortative network ().
- Distance Ratio (DR): The distances between local optima that are presented in the example are , , and . In that context, the median of the distances is 7.5. Furthermore, the representation of the solutions for the VRP instance for which the local optima network was constructed has a search space diameter of ten (), considering that the instance has ten customers. Thus, the distance ratio .
The local search measures for the examples are:
- Quality of Local Optima Sample (HC-Gap): The fitness of the local optima are . Therefore, the median . If the best solution of the LKH algorithm is , then the .
- Steps to Local Optima (Steps): The number of steps from the starting points (SP) to the local optima (LO) are , , and . So the median . Similar to the distance ratio, it is adjusted using the search space diameter. For this network the measure .
- Dispersion Coefficient (DC): The local optima network has a standard deviation of the fitness of 40.82 and a mean of 150. Therefore, the dispersion coefficient .
- Performance Measure (SA-Gap): The median fitness value of Simulated Annealing is and the best solution of the LKH algorithm is , then the .
4.6. Guidelines to Analyze Local Search Performance Based on Local Optima Network Analysis
Here we present our guidelines for analyzing the performance of local search (exemplified by SA) in VRP using LONA. For this research, the main objectives are:
- To determine whether measures based on information obtained from LONA can be useful to detect differences between VRP instances. The differences are studied using the CVRP, DVRP and DCVRP datasets.
- To understand the relationship that exists between pairs of LONA measures. We seek to describe changes in the direction and strength of associations between variables when exploring search spaces at different levels of constraint, both for individual attributes (CVRP and DVRP) and the multi-attribute case (DCVRP).
- To explore whether LONA measures are related with the behavior observed in local search algorithms.
The main steps of the research methodology are as follows:
- Preliminary analysis of local optima networks: To determine the differences between the VRP instances under study, we perform an analysis based on Repeated Measures ANOVA to detect significant differences in the LONA measures. This procedure is performed between variants (Multi-Attribute Perspective) and between constraint levels (Single-Attribute Perspective).
- Single-Attribute Perspective: We use the CVRP and DVRP datasets independently, emphasizing differences in LONA measures between constraint levels.
- Multi-Attribute Perspective: We use the DCVRP dataset, emphasizing the differences in LONA measures between the individual attributes of distance or capacity (Level 3) with those obtained when both are studied together.
- Correlation analysis: We use the Spearman Rank Correlation coefficient [31] to analyze the strong monotonic correlations between the LONA measures and whether these correlations hold between variants and constraint levels. Thus, we have a first approach to evaluate the effect that the restrictions have on the relationships between the measures we use. Therefore, this is an exploratory step in the study of the behavior of the LONA measures. We study the correlations in the CVRP and DCVRP datasets at each constraint level. In addition, we present the Spearman Rank Correlations obtained using the DCVRP dataset.
- Prediction of Difficulty for Local Search: Finally, we use the method of Logistic Regression to predict the difficulty of the instances using LONA measures. For this task, we propose a discretization of the performance measures in the CVRP, DVRP and DCVRP datasets. We split the instances in each one of these datasets into two equal-sized classes, based on the local search measures: Low (≤) and High (>). These categories let us capture the performance behavior and explore the underlying patterns associated with the LONA measures. We apply Logistic Regression over each dataset and extract the performance evaluation metrics using a re-sampling technique. For each one among the CVRP, DVRP and DCVRP datasets, we create 100 sample datasets that contain only one constraint level for each base instance. In this way, we create a Logistic Regression model for each sample dataset, and based on all the sample datasets, we obtain confidence intervals for the performance evaluation of the Logistic Regression used a method for classification [5].
5. Results
5.1. Preliminary Analysis of Local Optima Networks
The first objective is to understand the differences among the VRP variants considered in the research. In this context, Table 2 and Table 3 present the analysis based on Repeated Measures ANOVA on the single attribute datasets (CVRP and DVRP) and the multi-attribute dataset (DCVRP), respectively.
5.1.1. Single-Attribute Perspective
The analyses work with the following null () and alternative () hypotheses:
- : The corresponding LONA measure at different constraint levels has the same population mean. Thus, for the CVRP and DVRP datasets, for each measure.
- At least one population mean is different from the rest.
We do these analyses to know if different constraint levels lead to significantly different values of LONA measures. If the Fisher-test is significant (✓), it implies that at least two groups among those compared are significantly different (); otherwise (×) there is no evidence of a significant difference between the groups. The results are shown in Table 2.
For the distance attribute (DVRP dataset), most LONA measures present no significant differences. However, there are differences in the Distance Ratio. The result indicates that when considering a more constrained landscape, the local optima tend to present a greater distance between them. On the other hand, the measures related to local search show significant differences in Quality of Local Optima and Steps to Local Optima. Note that the local search is performed on constrained landscapes, so the visited solutions must be feasible. We observe that, in a more constrained landscape, the local optimum reached by Hill-Climbing is closer to the starting point and the median quality of local optima is better. On the other hand, no significant difference is observed in the fitness dispersion; Dispersion Coefficient does not change between the different constraint levels.
On the other hand, the capacity attribute (CVRP dataset) has different results from those obtained for the distance attribute. For the LONA measures, Density and Transitivity of the network maintain the behavior observed for the distance attribute. However, we find significant differences concerning Assortativity. At this point, it is important to note that the networks present low Assortativity (mean at level 0 and at level 3 of the CVRP). That is, local optima with a similar degree tend to be more connected. Similarly, for the local search measures, the results for Quality of Local Optima and Steps to Local Optima are maintained. However, for the capacity attribute, there are significant differences in Dispersion Coefficient. Thus, the dispersion is slightly higher at higher constraint levels.
It is common for the datasets that we study that we observe no differences for Density and Transitivity, even when both types of constraints are involved. This indicates no significant differences in the number of edges or the tendency to cluster in the network. On the other hand, there are some differences in the distribution of local optima, both in Distance Ratio and Assortativity.
5.1.2. Multi-Attribute Perspective
The analyses work with the following null () and alternative () hypotheses:
- : and : The population mean is different.
- : and : The population mean is different.
- : and : The population mean is different.
For the Multi-Attribute Perspective, we observe that for DVRP and CVRP, there are significant differences in the behavior observed for the LONA measures in DCVRP. The results imply a difference in the overall structure of the search space when distance and capacity attributes are considered simultaneously. The above is valid for all measures, except for network density and transitivity, in both CVRP and DVRP. Furthermore, in the case of CVRP, there are also no significant differences from DCVRP in network assortativity.
5.2. Correlation Analysis of LONA Measures
The previous subsection presents the univariate analysis of LONA. In contrast, here we seek to expand the research to a bivariate view. From this perspective, the use of Spearman Rank Correlation is proposed to quantify the relationship between pairs of measures without assuming linear behavior.
Table 4 and Table 5 show that Quality of Local Optima Sample has a moderately high and monotonically positive relationship with the Distance Ratio. Thus, the HC-Gap tends to be larger when the local optima are more distant. Moreover, we observe that this relationship is stronger at higher constraint levels.
Another aspect to mention is that Quality of Local Optima Sample has a moderately low and monotonically negative relationship with Assortativity. As with Distance Ratio, this behavior is stronger at higher levels of constraint for the capacity attribute. Local optima networks with more connections between local optima with a similar degree tend to produce a smaller HC-Gap.
Additionally, we observe that Dispersion Coefficient has a moderately high and monotonically positive relationship with Quality of Local Optima Sample. Thus, we observe a large HC-Gap when the variability in the fitness of the local optima is higher. The relationship between DC and HC-Gap is stronger in instances with lower constraint levels. Furthermore, the relationship is stronger for the distance attribute than for the capacity attribute.
The tables show a moderately positive Spearman Rank Correlation between Steps to Local Optima and Distance Ratio. Both measures focus on the number of moves; consequently, we expect that local optima networks with higher distances between local optima tend to force more hill-climbing movements to achieve the local optimum.
There also exists a significant negative relationship between Steps to Local Optima and the network’s Assortativity. These results show that in more assortative networks fewer steps are need to achieve the local optimum. The relationship is stronger in more constrained landscapes.
With DVRP and m-TSP, we observe that Distance Ratio has a moderate and negative correlation with Transitivity of the network, i.e., the greater the distance between the local optima, the lower the tendency to clustering. Furthermore, we note a moderate negative correlation between Assortativity and Distance Ratio for both the capacity and the distance attributes. It is important to note that the most significant correlations are associated with the distance between local optima.
5.3. Prediction of Difficulty for Local Search
The analysis is performed separately on CVRP, DVRP, and DCVRP datasets. As mentioned in the guidelines for the research, we propose to partition the fitness landscapes in each dataset into two equal-sized classes based on the average Gap obtained by SA: Low (≤median) and High (>median). The classes are created based on the performance of SA on all the instances in the respective dataset (without differentiating between occupancy rates, nor the instances selected in a particular sample dataset). SA-Gap is categorized as having a high Gap when it exceeds the Gap of 4.1% for CVRP, 6.2% for DVRP, and 4.4% for DCVRP.
Applying the re-sampling technique, we split each sample dataset into training (70% of the dataset) and test (30% of the dataset) sets. We use the training set to fit a Logistic Regression model and the test set to extract the classification metrics: Accuracy, F1 and ROC AUC scores. Furthermore, we build a confidence interval (95%) for the classification metrics using the results of the re-sampling process.
As shown in Table 6, the LONA measures show promising results in predicting the difficulty of the instances. Furthermore, we observe that the classification metrics present better results when the attributes are studied individually, i.e., when the LONA measures describe either a CVRP or a DVRP search space. In contrast, there is a decrease in predictive power when both types of attributes are considered simultaneously.
The results suggest that the difficulty of the instance can be explained (to a great extent) by information obtained from a simple sampling method on local optima. As shown in Table 7, note that there are differences with respect to which variables are significant for each variant. However, the effect of some variables is cross-sectional for the variants studied, such as Distance Ratio, Assortativity, Steps to Local Optima, and Quality of Local Optima Sample. The main differences are associated with the presence or absence of capacity constraints. In the case of DVRP, the only additional variable that affects instance difficulty is related to Transitivity. That is the grouping of local optima that facilitates transitions between them. On the other hand, by including the capacity constraint, both in CVRP and DCVRP, Transitivity ceases to be significant, being replaced by Dispersion Coefficient, i.e., elements related to the variability in the fitness of local optima are incorporated.
6. Conclusions
The literature associated with Multi-Attribute Vehicle Routing Problems has been focused mainly on designing new algorithms. Consequently, little literature refers to the effect of constraints in a local search performed only on the feasible search space, considering that the local operators in use tend to be designed originally for the unconstrained search space. From our perspective, understanding the constraints’ impact on local search generates valuable information for constructing new and better algorithms, advancing toward understanding the patterns observed in the family of Vehicle Routing Problems.
Recently, the perspective of studying complex problems using Fitness Landscape Analysis has advanced toward understanding and describing the behavior of algorithms, performance prediction, and automation in algorithm selection and configuration. Thus, this paper provides new information about algorithmic behavior on constrained search spaces under different attributes. We present a disaggregated way to explore Distance-Constrained Capacitated Vehicle Routing Problems, studying them at different constraint levels for both attributes.
We present a methodology for constructing local optima networks based on the Relocate operator, which is widely used in algorithms that seek to solve Vehicle Routing Problems. So, we give a preliminary idea of the effect of constraints on local search, with comparisons to the unconstrained search space. Thus, we base our analyses on the m-TSP search space, although the local optima are found using the respective constrained search space.
Focused on studying the behavior of the search algorithm, we establish specific measures that are extracted from the construction of the local optima network. Thus, we determine that some measures such as Density and Transitivity, remain invariant to the constraint level and the interaction between attributes. On the other hand, in the distance attributes, a more constrained landscape tends to present a greater distance between local optima. This behavior is not observed in the capacity attribute. Likewise, in the capacity attribute, we observe that a more constrained scenario favors an assortative behavior between local optima, which is not observed in distance attribute. From the Quality of Local Optima Sample, both the MAVRP and the individual attributes show significant differences in the behavior in the face of more constrained scenarios and multi-attribute cases.
Additionally, we analyze the effectiveness of using LONA measures to predict instance difficulty. Using measures based on local optima samples can differentiate between instances with greater or lesser difficulty for Simulated Annealing. In addition, we show specific differences and similarities between the capacity and distance attributes. For both attributes, we find that the instance difficulty is related to certain common measures, such as the Distance Ratio, Quality of Local Optima Sample, Assortativity, and Number of Steps to Local Optimum. On the other hand, we show that the difficulty of the distance attribute is also related to the Transitivity measure. In contrast, the difficulty of the capacity attribute is related to the Dispersion Coefficient.
The analyses presented in this paper indicate that further study of the effect of constraints on Vehicle Routing Problems is required and that analyzing global measures of the landscape structure provides valuable information on the difficulty of the instance. It is important to note that the results of this paper are complementary to those presented in Muñoz-Herrera and Suchan [5], since: (1) We present different methods and techniques to study the impact of the global structure of the search space on the behavior of metaheuristic algorithms; (2) We present a multi-attribute approach, including vehicle capacity and route duration. These attributes have different impacts on the landscape structure. In that context, both types of constraints directly affect the assignment of customers to vehicles, however, the capacity constraints only affect the definition of the neighborhood of each solution. In contrast, distance constraints affect both the neighborhood and the fitness function.
Recent advances in Fitness Landscape Analysis, including our contributions to the study of Vehicle Routing Problems, suggest the following directions for future work: (1) Explore the relationship between FLA measures and other metaheuristic algorithms, including more complex local operators and different search mechanisms; (2) Study the landscape behavior of other common VRP attributes such as time windows, pickup and delivery, multiple depots, and split deliveries. An interesting perspective is to study the impact of constraints that affect the sequence of customer visits; (3) Establish the relationship between measures taken at the solution level (micro-scale), such as information, statistical, or feasibility measures, and those taken at the level of the local optima network (macro scale); (4) Study approximations to the distance measure in the constraint search space, under different local operators and representations, to complement the distance computed in the unconstrained search space. It is only natural to hypothesize that a good approximation could bring valuable additional information for the study of search algorithm performance.
In the last 15 years, advances in the methods related to Fitness Landscape Analysis have demonstrated their value in algorithm behavior description, performance prediction, and automation in algorithm selection and configuration. So, any advance in this area of knowledge will provide substantial improvements in the decision-making processes associated with the solution of complex optimization problems.
Author Contributions
Conceptualization, S.M.-H. and K.S.; Methodology, S.M.-H. and K.S.; Codes, S.M.-H.; Validation, S.M.-H.; Formal analysis, S.M.-H. and K.S.; Investigation, S.M.-H. and K.S.; resources, S.M.-H.; Writing—original draft preparation, S.M.-H.; writing—review and editing, K.S.; Supervision, K.S.; Project administration, S.M.-H. and K.S.; Funding acquisition, S.M.-H. and K.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by ANID BECAS/DOCTORADO NACIONAL 21191028 (S.M.-H.) and Programa Regional STICAMSUD 19-STIC-05 (K.S.).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The CVRP, DVRP and DCVRP datasets are available in Muñoz-Herrera and Suchan [24].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bektas, T. The Multiple Traveling Salesman Problem: An Overview of Formulations and Solution Procedures. Omega 2006, 34, 209–219. [Google Scholar] [CrossRef]
- Vidal, T.; Crainic, T.C.; Gendreau, M.; Prins, C. Heuristics for Multi-Attribute Vehicle Routing Problems: A Survey and Synthesis. Eur. J. Oper. Res. 2013, 231, 1–21. [Google Scholar] [CrossRef]
- Caceres-Cruz, J.; Arias, P.; Guimarans, D.; Riera, D.; Juan, A. Rich Vehicle Routing Problem. ACM Comput. Surv. 2015, 47, 1–28. [Google Scholar] [CrossRef]
- Hooker, J.N. Testing Heuristics: We Have It All Wrong. J. Heuristics 1995, 1, 33–42. [Google Scholar] [CrossRef]
- Muñoz-Herrera, S.; Suchan, K. Constrained Fitness Landscape Analysis of Capacitated Vehicle Routing Problems. Entropy 2022, 24, 53. [Google Scholar] [CrossRef]
- Van Stein, B.; Emmerich, M.; Yang, Z. Fitness Landscape Analysis of NK Landscapes and Vehicle Routing Problems by Expanded Barrier Trees. In EVOLVE—A Bridge Between Probability, Set Oriented Numerics, and Evolutionary Computation IV; Emmerich, M., Deutz, A., Schuetze, O., Bäck, T., Tantar, E., Tantar, A.A., Del Moral, P., Legrand, P., Bouvry, P., Coello, C.A., Eds.; Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2013; Volume 227, pp. 75–89. [Google Scholar]
- Christofides, N.; Mingozzi, A.; Toth, P. Exact Algorithms for the Vehicle Routing Problem, based on Spanning Tree and Shortest Path Relaxations. Math. Program. 1981, 20, 255–282. [Google Scholar] [CrossRef]
- Stadler, P.F. Towards a Theory of Landscapes. In Complex Systems and Binary Networks; Lecture Notes in Physics; Springer: Berlin/Heidelberg, Germany, 1995; Volume 461, pp. 78–163. [Google Scholar]
- Malan, K.M.; Engelbrecht, A.P. A Survey of Techniques for Characterising Fitness Landscapes and Some Possible Ways Forward. Inf. Sci. 2013, 241, 148–163. [Google Scholar] [CrossRef] [Green Version]
- Malan, K.M. A Survey of Advances in Landscape Analysis for Optimisation. Algorithms 2021, 14, 40. [Google Scholar] [CrossRef]
- Kovács, L.; Agárdi, A.; Bányai, T. Fitness Landscape Analysis and Edge Weighting-Based Optimization of Vehicle Routing Problems. Processes 2020, 8, 1363. [Google Scholar] [CrossRef]
- Agárdi, A.; Kovács, L.; Bányai, T. An Attraction Map Framework of a Complex Multi-Echelon Vehicle Routing Problem with Random Walk Analysis. Appl. Sci. 2021, 11, 2100. [Google Scholar] [CrossRef]
- Tomassini, M. A Local Optima Network View of Real Function Fitness Landscapes. Entropy 2022, 24, 703. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Luo, S. Adaptive Differential Evolution Algorithm Based on Fitness Landscape Characteristic. Mathematics 2022, 10, 1511. [Google Scholar] [CrossRef]
- Sörensen, K.; Schittekat, P. Statistical Analysis of Distance-Based Path Relinking for the Capacitated Vehicle Routing Problem. Comput. Oper. Res. 2013, 40, 3197–3205. [Google Scholar] [CrossRef]
- Braysy, O.; Gendreau, M. Vehicle Routing Problem with Time Windows, Part II: Metaheuristics. Transp. Sci. 2005, 39, 119–139. [Google Scholar] [CrossRef]
- Verel, S.; Daolio, F.; Ochoa, G.; Tomassini, M. Local Optima Networks with Escape Edges. In Artificial Evolution. EA 2011; Hao, J.K., Legrand, P., Collet, P., Monmarché, N., Lutton, E., Schoenauer, M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7401. [Google Scholar]
- Ochoa, G.; Verel, S.; Daolio, F.; Tomassini, M. Local Optima Networks: A New Model of Combinatorial Fitness Landscapes. In Recent Advances in the Theory and Application of Fitness Landscapes; Richter, H., Engelbrecht, A., Eds.; Emergence, Complexity and Computation; Springer: Berlin/Heidelberg, Germany, 2014; Volume 6. [Google Scholar]
- Thomson, S.L.; Ochoa, G.; Verel, S.; Veerapen, N. Inferring Future Landscapes: Sampling the Local Optima Level. Evol. Comput. 2020, 28, 621–641. [Google Scholar] [CrossRef] [PubMed]
- Pavelski, L.C.; Kessaci, M.E.; Delgado, M. Local Optima Network Sampling for Permutation Flowshop. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Kraków, Poland, 28 June–1 July 2021; pp. 1131–1138. [Google Scholar]
- Ochoa, G.; Chicano, F. Local Optima Network Analysis for MAX-SAT. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Association (GECCO 2019—Prague, Czech Republic) for Computing Machinery, New York, NY, USA, 13–17 July 2019; pp. 1430–1437. [Google Scholar]
- Ochoa, G.; Veerapen, N. Mapping the Global Structure of TSP Fitness Landscapes. J. Heuristics 2018, 24, 265–294. [Google Scholar] [CrossRef] [Green Version]
- Lipinski, P.; Michalak, K. Deriving Knowledge From Local Optima Networks for Evolutionary Optimization in Inventory Routing Problem. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Association (GECCO 2019—Prague, Czech Republic) for Computing Machinery, New York, NY, USA, 13–17 July 2019; pp. 1551–1558. [Google Scholar]
- Muñoz-Herrera, S.; Suchan, K. [Data Set] Local Optima Network Analysis of Multi-Attribute Vehicle Routing Problem; Zenodo: Genève, Switzerland, 2022. [Google Scholar] [CrossRef]
- Schiavinotto, T.; Stützle, T. A Review of Metrics on Permutations for Search Landscape Analysis. Comput. Oper. Res. 2007, 34, 3143–3153. [Google Scholar] [CrossRef] [Green Version]
- Takaoka, A. Complexity of Hamiltonian Cycle Reconfiguration. Algorithms 2018, 11, 140. [Google Scholar] [CrossRef] [Green Version]
- Wrochna, M. Reconfiguration in Bounded Bandwidth and Tree-depth. J. Comput. Syst. Sci. 2018, 93, 1–10. [Google Scholar] [CrossRef]
- Helsgaun, K. An Extension of the Lin-Kernighan-Helsgaun TSP Solver for Constrained Traveling Salesman and Vehicle Routing Problems; Technical Report; Roskilde University: Roskilde, Denmark, 2017. [Google Scholar]
- Vidal, T. Split Algorithm in O(n) for the Capacitated Vehicle Routing Problem. Comput. Oper. Res. 2016, 69, 40–47. [Google Scholar] [CrossRef] [Green Version]
- Van Breedam, A. Improvement Heuristics for the Vehicle Routing Problem Based on Simulated Annealing. Eur. J. Oper. Res. 1995, 86, 480–490. [Google Scholar] [CrossRef]
- Corder, G.W.; Foreman, D.I. Nonparametric Statistics; John Wiley & Sons: Nashville, TN, USA, 2014. [Google Scholar]
Figure 1.
Relation between the VRP variants considered in this research.

Figure 2.
Example: Neighborhood of solution [0120340] (yellow): intra-route neighbors (orange) and inter-route neighbors (green).
Figure 2.
Example: Neighborhood of solution [0120340] (yellow): intra-route neighbors (orange) and inter-route neighbors (green).

Figure 3.
Basins-transitions between local optima.

Figure 4.
Transitions between local optima based on Escape-edges. The dotted circumference represents solutions at a distance less than D from .
Figure 4.
Transitions between local optima based on Escape-edges. The dotted circumference represents solutions at a distance less than D from .

Figure 5.
Example: local optima network and measures.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Degree of each pair of adjacent nodes in the example.
| 3 | 3 | 3 | 2 | 2 | 2 | 2 | 1 | |
| 2 | 2 | 1 | 3 | 2 | 3 | 2 | 3 |
Table 2.
Results for Repeated Measures ANOVA for LONA measures-Single-Attribute Perspective.
| Measures | DVRP | CVRP |
|---|---|---|
| Density | × | × |
| Transitivity | × | × |
| Assortativity | × | ✓ |
| Distance Ratio | ✓ | × |
| Dispersion Coefficient | × | ✓ |
| Quality of Local Optima | ✓ | ✓ |
| Steps to Local Optima | ✓ | ✓ |
Table 3.
Results for Repeated Measures ANOVA for LONA measures—Multi-Attribute Perspective.
| DVRP | DVRP | CVRP | |
|---|---|---|---|
| Measures | CVRP | DCVRP | DCVRP |
| Density | × | × | × |
| Transitivity | × | × | × |
| Assortativity | ✓ | ✓ | × |
| Distance Ratio | ✓ | ✓ | ✓ |
| Dispersion coefficient | ✓ | ✓ | ✓ |
| Quality of local optima | ✓ | ✓ | ✓ |
| Steps to Local Optima | ✓ | ✓ | ✓ |
Table 4.
Spearman Rank Correlation for LONA measures, comparison for the capacity attribute. Bold values denotes the coefficients that are significant at a .
Table 4.
Spearman Rank Correlation for LONA measures, comparison for the capacity attribute. Bold values denotes the coefficients that are significant at a .
| Measure 1 | Measure 2 | MTSP | CVRP75 | CVRP50 | CVRP25 | DCVRP |
|---|---|---|---|---|---|---|
| Quality of | Dispersion Coefficient | 0.83 | 0.55 | 0.61 | 0.58 | 0.59 |
| Local | Steps to Local Optima | 0.24 | 0.28 | 0.34 | 0.42 | 0.43 |
| Optima | Density | 0.05 | 0.13 | −0.12 | −0.10 | −0.18 |
| Sample | Transitivity | −0.18 | 0.004 | 0.08 | −0.09 | −0.13 |
| Assortativity | −0.31 | −0.24 | −0.28 | −0.46 | −0.47 | |
| Distance Ratio | 0.46 | 0.73 | 0.67 | 0.71 | 0.77 | |
| Dispersion | Steps to Local Optima | −0.04 | −0.10 | 0.07 | 0.10 | 0.16 |
| Coefficient | Density | 0.08 | −0.08 | −0.12 | −0.21 | −0.22 |
| Transitivity | 0.06 | 0.20 | 0.28 | 0.34 | 0.35 | |
| Assortativity | −0.09 | −0.17 | −0.18 | −0.16 | −0.23 | |
| Distance Ratio | 0.16 | 0.30 | 0.27 | 0.29 | 0.32 | |
| Steps to | Density | −0.31 | 0.03 | −0.13 | −0.10 | −0.17 |
| Local Optima | Transitivity | −0.16 | 0.10 | 0.23 | 0.08 | 0.11 |
| Assortativity | −0.38 | −0.51 | −0.67 | −0.81 | −0.81 | |
| Distance Ratio | 0.49 | 0.45 | 0.54 | 0.51 | 0.57 | |
| Density | Transitivity | 0.31 | 0.27 | 0.43 | 0.37 | 0.41 |
| Assortativity | −0.24 | 0.10 | 0.02 | 0.05 | 0.08 | |
| Distance Ratio | −0.05 | 0.14 | −0.01 | −0.09 | −0.21 | |
| Transitivity | Assortativity | 0.23 | 0.05 | −0.19 | −0.10 | −0.08 |
| Distance Ratio | −0.64 | −0.09 | −0.02 | 0.25 | −0.27 | |
| Assortativity | Distance Ratio | −0.56 | −0.29 | −0.40 | −0.57 | −0.59 |
Table 5.
Spearman Rank Correlation for LONA measures, comparison for the distance attribute. Bold values denotes the coefficients that are significant at a .
Table 5.
Spearman Rank Correlation for LONA measures, comparison for the distance attribute. Bold values denotes the coefficients that are significant at a .
| Measure 1 | Measure 2 | MTSP | DVRP50 | DVRP30 | DVRP10 | DCVRP |
|---|---|---|---|---|---|---|
| Quality of | Dispersion Coefficient | 0.83 | 0.83 | 0.82 | 0.81 | 0.59 |
| Local | Steps to local optima | 0.24 | 0.23 | 0.26 | 0.28 | 0.43 |
| Optima | Density | 0.05 | −0.18 | −0.31 | 0.05 | −0.18 |
| Sample | Transitivity | −0.18 | −0.30 | −0.33 | −0.08 | −0.13 |
| Assortativity | −0.31 | −0.15 | −0.10 | −0.24 | −0.47 | |
| Distance Ratio | 0.46 | 0.46 | 0.47 | 0.50 | 0.77 | |
| Dispersion | Steps to local optima | −0.04 | −0.06 | −0.05 | −0.03 | 0.16 |
| Coefficient | Density | 0.08 | −0.18 | −0.24 | 0.04 | −0.22 |
| Transitivity | 0.06 | −0.13 | −0.17 | −0.02 | 0.35 | |
| Assortativity | −0.09 | 0.07 | 0.10 | −0.01 | −0.23 | |
| Distance Ratio | 0.16 | 0.17 | 0.18 | 0.17 | 0.32 | |
| Steps to | Density | −0.31 | −0.25 | −0.34 | −0.15 | −0.17 |
| local optima | Transitivity | −0.16 | −0.20 | −0.21 | −0.02 | 0.11 |
| Assortativity | −0.38 | −0.43 | −0.41 | −0.48 | −0.81 | |
| Distance Ratio | 0.49 | 0.48 | 0.49 | 0.49 | 0.57 | |
| Density | Transitivity | 0.31 | 0.33 | 0.38 | 0.33 | 0.41 |
| Assortativity | −0.24 | −0.17 | −0.12 | −0.18 | 0.08 | |
| Distance Ratio | −0.05 | −0.09 | −0.20 | 0.01 | −0.21 | |
| Transitivity | Assortativity | 0.23 | 0.44 | 0.43 | 0.32 | −0.08 |
| Distance Ratio | −0.64 | −0.72 | −0.70 | −0.50 | −0.27 | |
| Assortativity | Distance Ratio | −0.56 | −0.57 | −0.45 | −0.57 | −0.59 |
Table 6.
Classification summary for Logistic Regression to predict difficulty for local search.
| Metric | CVRP | DVRP | DCVRP |
|---|---|---|---|
| Accuracy | 0.775 ± 0.016 | 0.781 ± 0.016 | 0.731 ± 0.016 |
| F1 Score | 0.784 ± 0.017 | 0.798 ± 0.017 | 0.727 ± 0.019 |
| Roc Auc Score | 0.844 ± 0.015 | 0.846 ± 0.015 | 0.796 ± 0.015 |
Table 7.
Significance of the variables for Logistic Regression to identify difficulty of instances. Statistically significant variables () are represented with (✓).
Table 7.
Significance of the variables for Logistic Regression to identify difficulty of instances. Statistically significant variables () are represented with (✓).
| Measure | CVRP | DVRP | DCVRP |
|---|---|---|---|
| Density | × | × | × |
| Transitivity | × | ✓ | × |
| Assortativity | ✓ | ✓ | ✓ |
| Distance Ratio | ✓ | ✓ | ✓ |
| Dispersion Coefficient | ✓ | × | ✓ |
| Quality of local optima | ✓ | ✓ | ✓ |
| Steps to Local Optima | ✓ | ✓ | ✓ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Muñoz-Herrera, S.; Suchan, K. Local Optima Network Analysis of Multi-Attribute Vehicle Routing Problems. Mathematics 2022, 10, 4644. https://doi.org/10.3390/math10244644
AMA Style
Muñoz-Herrera S, Suchan K. Local Optima Network Analysis of Multi-Attribute Vehicle Routing Problems. Mathematics. 2022; 10(24):4644. https://doi.org/10.3390/math10244644
Chicago/Turabian StyleMuñoz-Herrera, Sebastián, and Karol Suchan. 2022. "Local Optima Network Analysis of Multi-Attribute Vehicle Routing Problems" Mathematics 10, no. 24: 4644. https://doi.org/10.3390/math10244644
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.