
Abstract
It is generally believed that concepts can be characterized by their properties (or features). When investigating concepts encoded in language, researchers often ask subjects to produce lists of properties that describe them (i.e., the Property Listing Task, PLT). These lists are accumulated to produce Conceptual Property Norms (CPNs). CPNs contain frequency distributions of properties for individual concepts. It is widely believed that these distributions represent the underlying semantic structure of those concepts. Here, instead of focusing on the underlying semantic structure, we aim at characterizing the PLT. An often disregarded aspect of the PLT is that individuals show intersubject variability (i.e., they produce only partially overlapping lists). In our study we use a mathematical analysis of this intersubject variability to guide our inquiry. To this end, we resort to a set of publicly available norms that contain information about the specific properties that were informed at the individual subject level. Our results suggest that when an individual is performing the PLT, he or she generates a list of properties that is a mixture of general and distinctive properties, such that there is a non-linear tendency to produce more general than distinctive properties. Furthermore, the low generality properties are precisely those that tend not to be repeated across lists, accounting in this manner for part of the intersubject variability. In consequence, any manipulation that may affect the mixture of general and distinctive properties in lists is bound to change intersubject variability. We discuss why these results are important for researchers using the PLT.
Similar content being viewed by others

Introduction
It is generally considered that concepts (or at least concrete concepts) can be characterized by their properties (also called features) and those properties’ distributions. In particular, to study natural concepts encoded in language, researchers often ask subjects to provide a list of properties related to a given concept (i.e., the Property Listing Task, PLT; also known as the Feature Listing Task). Accumulating these lists across multiple subjects, Conceptual Property Norms (CPNs) are built. These norms are widely believed to contain information about the underlying semantic structure of those concepts contained in CPNs.
Despite the wide use of the PLT, little attention has been devoted to understanding it. In particular, an often overlooked fact is that the PLT produces intersubject variability (i.e., different people produce somewhat different lists of properties). As we will discuss briefly, this is not a trivial fact. In the current study, we focus on how to understand this variability, how it should be measured, and we explore two variables that seem good a priori candidates to affect it: concept exposure and property generality. To this end, we analyze a large set of normed concepts, with a focus on the PLT rather than on the underlying semantic or conceptual structure. In what remains of this introduction, we discuss the relation between concepts and properties, how the PLT is used to build CPNs and what these norms are used for, and how variability is currently handled in CPNs and other studies.
Concepts and conceptual properties
Two central tenets of the prevailing view of concepts are that representations are perceptually based and that they are learned (Prinz, 2005). For example, through experience, people learn that a face is characterized by properties such as a given nose length, eye separation, mouth width, etc. (e.g., Tversky, 1977). This has come to be a substantial part of the standard theory of concepts, and it holds that concepts are learned by observing category exemplars, extracting the relevant properties (Schyns, Goldstone, & Thibaut, 1998), and estimating the frequency distribution of those relevant properties (Ashby & Alfonso-Reese, 1995; Griffiths, Sanborn, Canini, Navarro, & Tenenbaum, 2011). This then allows organizing a semantic structure and making category judgments (e.g., How typical is a given exemplar of category X? Does the exemplar belong to category X or category Y? How central is property j for category X?).
The nature of the extraction and estimation processes are the concern of many theories, which attempt to explain how properties are combined by the cognitive system in order to achieve correct classification. We pay limited attention to those theories, but the interested reader may consult any of several books devoted to that topic (e.g., Murphy, 2002; Pothos & Wills, 2011). Much of this research has been done in laboratory experiments with artificial categories. However, it is generally assumed that the same processes extrapolate to the real world. Notably, it is assumed that conceptual properties play an important role in categorization both inside and outside the laboratory (e.g., McRae, Cree, Seidenberg, & McNorgan, 2005).
A well-known finding about concepts is that they relate only probabilistically to conceptual properties (Rosch, 1973). This means, among other things, that two concepts that may be applied to a situation or object are generally not able to be discriminated between through a logical rule (i.e., by necessary and sufficient properties), but show a typicality structure instead (Rosch, Simpson, & Miller, 1976). Those exemplars that exhibit frequent properties are more typical than those exhibiting less frequent properties (Rosch & Mervis, 1975) (e.g., an ostrich would be a low typicality exemplar of the BIRD category, whereas a dove would be a typical exemplar). The typicality structure also means that an object can be a member of different categories, though probably to different degrees (e.g., a Chihuahua may be a low typicality exemplar of the DOG category, while simultaneously being a relatively more typical case of the PET category). Importantly for the work we report here, note that all this implies that concepts will to a large extent share properties (e.g., being friendly is a property of DOG, but also of DOLPHIN; being made of metal may be a property of FLUTE, but also of FORK). Henceforth, we refer to this as the degree of generality of properties. General properties are those that are shared across many concepts (e.g., being made of metal). Low generality properties are sometimes referred to as distinctive properties (Cree & McRae, 2003), i.e., those that relate to only a few concepts (e.g., being used to treat headaches). Note, however, that general and distinctive properties are simply two extremes of the same continuous dimension.
Conceptual property norms
When researchers want to learn about natural concepts outside of the control offered by the laboratory, they might collect data about linguistic productions, and build Conceptual Property Norms (CPNs). Whereas categories used in laboratory experiments are often arbitrary (e.g., patterns of dots on a screen), categories in the real world are typically conventional and encoded in language (e.g., DOG, CAR, ALLIGATOR). An important tool used to construct CPNs is the Property Listing Task (PLT; e.g., Cree & McRae, 2003; Hampton, 1979; McRae, Cree, Seidenberg, & McNorgan, 2005; Rosch & Mervis, 1975; Rosch et al., 1976). In this task, subjects are asked to produce features typically associated with a given concept (e.g., to the question “What properties are typically true of a DOG?”, “has four legs” may be produced). After coding responses into property types (i.e., grouping together responses with only superficial differences across subjects, e.g., “has four legs” and “is a quadruped”), responses are accumulated to build the CPNs. These norms are frequency distributions of property types produced by a sample of subjects for a large number of concepts encoded in language.
Conceptual Property Norms contain a wealth of information about concepts and their properties. They are widely believed to measure underlying conceptual content, which in turn is thought to reflect the statistical structure of the categories under study (e.g., McNorgan, Kotack, Meehan, & McRae, 2007). This information may be used for different purposes. Norming studies can be used to test theories. For example, it is possible to make predictions based on these norms’ distributional properties, e.g., the pattern of inter-property correlations that typically emerge in these norms (e.g., characterizing differences between tools and animals; Cree & McRae, 2003), or the way properties cluster by sensory modality (e.g., “it makes pleasant sounds” and “it can sing,” both correspond to the auditory modality; e.g., Vigliocco, Vinson, Lewis, & Garrett, 2004; Wu & Barsalou, 2009). The norms may also be used as a source of control variables for experiments, e.g., controlling for frequency of properties, cue validity, number of properties produced, and other such variables (e.g., McRae, Cree, Westmacott, & de Sa, 1999).
Conceptual variability
A fact that may be overlooked is that conceptual content varies across individuals (i.e., intersubject conceptual variability) and even within individuals over time (i.e., intrasubject conceptual variability; see Barsalou, 1987, 1993). When asked to list conceptual properties for a concept, different people produce somewhat different properties and the same person may produce somewhat different properties over time. This is often considered problematic. Based on this, Barsalou (1987, 1993) doubted that concepts are entities in the mind. Converse (1964), based on the instability of public opinion, doubted that public opinion exists. More recently, Gabora, Rosch, and Aerts (2008) suggested that concepts should be modeled with quantum mechanics formalisms, because in their view, concepts, like quantum entities, do not have definite properties unless in a particular measurement situation. Notably, this whole debate predates psychological discussions (see Frege, 1893; Glock, 2009; Russell, 1997).
In the context of CPNs, variability has been treated as measurement error; a less radical option than those discussed above. In particular, a common practice in CPN studies is to weed out from the norms those properties produced by less than a given proportion of the sample, on the account that low frequency responses would obscure the general patterns in the data (e.g., in McRae et al., 2005, features produced by less than five out of 30 participants were not included in the analyses).
In the current work, rather than sweeping it under the rug, we deliberately focus on conceptual variability. In our analysis, the issue of variability is intimately linked with the PLT. Several reasons for conceptual variability in the PLT come to mind. People may produce different conceptual content because of contextual effects (i.e., slight differences in the context present when individuals are producing conceptual properties result in different conceptual content being accessed), because of differences in interest or salience (i.e., people may be differentially motivated to produce content for a given concept), because of exposure (i.e., being differentially exposed to a concept may lead to changes in the identity and number of properties learned and reported), or because of differences in the level of generality of properties being produced (i.e., people producing more general properties may achieve less intersubject variability than people producing more distinctive properties). Of these potential factors, in the current work we focus on the latter two.
Theory
As noted by Barsalou and collaborators (Santos, Chaigneau, Simmons, & Barsalou, 2011; Wu & Barsalou, 2009), though the PLT is used by researchers across psychology (e.g., in cognitive psychology, social psychology, cognitive neuroscience, neuropsychology, consumer psychology), little is known about its characteristics. Hence, our goal in the current work is to analyze the PLT. In particular, we will show how to compute an index of intersubject variability, and then use this formulation to test the effects of exposure and generality on PLT variability. A mathematical tool will aid us in this undertaking. In the current work, we use the probability of true agreement (event labeled a1, being p(a1) its corresponding probability) as a measure of intersubject conceptual variability (Canessa & Chaigneau, 2016; Chaigneau, Canessa, & Gaete, 2012).
In a CPN study, after raw data has been collected and properties have been coded, all that researchers have are different lists of properties produced by individual subjects. Each of these lists can be thought of as a sample of conceptual content taken from the total population of properties produced by participants in the CPN study. These samples vary in length and in content (respectively, the number of properties and the specific properties they contain). We can quantify these differences via the probability of true agreement (p(a1)). This is defined as the probability that a property that is picked randomly from one of these samples is also found in another randomly picked sample. Note that p(a1) is a measure of intersubject variability in conceptual content because it will achieve a value of 1 if and only if all subjects produce the same list of properties in the PLT (i.e., same content and same length), and it will achieve a value of 0 (zero) if and only if all subjects produce completely different lists of properties in the PLT. Thus, p(a1) = 1 means that there is no conceptual variability, and p(a1) = 0 means that conceptual variability is maximal. A desirable property of p(a1) is that it is strictly comparable across conditions. As will become evident from our discussions, this probability is applicable across concepts, regardless of how their properties are distributed. (Note that our measure could be applied to other data collection procedures in which participants’ responses are accumulated to obtain frequency distributions, and where intersubject variability is likely to arise, such as word association and top-of-mind procedures. However, we will not explore this issue further.)
Expression (1) puts these ideas into mathematical form. Due to space restrictions, we do not derive the equation here. The interested reader may find its development and a fuller explanation in Chaigneau, Canessa and Gaete (2012). In lieu of that, after explaining the terms in the equation, we provide a simplified example of its computation illustrating its meaning.
Equation (1) is the summation of the expected value of the number of common properties between all possible pairs of samples (lists of size s 1 ) of properties randomly obtained from a concept in a PLT (i.e., the S 1 i and S 1 j in the equation, and the corresponding cardinality of the intersection, i.e., the # (S 1 i ∩ S 1 j ) term), taking into account the probabilities of each sample (i.e., the p i and p j ). Assuming that all properties in the samples have the same probability of being selected from a given sample, p(a1) is calculated as the summation in (1) divided by s 1 . The terms in Eq. (1) are defined in Table 1.
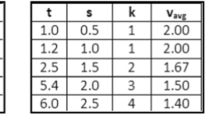
The following is a worked out example of how p(a1) is computed. Let us assume a PLT for the concept DOG, and that after coding, three properties are obtained. In this case, a = “is a pet”, b = “has four legs,” c = “is hairy.” Also assume that, on average, each of the lists produced by subjects has two properties, i.e., s 1 = 2. Figure 1 shows this hypothetical example.

A concept with its corresponding properties {a, b, c}, with k 1 (number of properties) = 3, and two lists of properties obtained in a PLT, each on average of size s 1 = 2
The relevant quantities that are necessary to compute p(a1) are:
k 1 = 3
s 1 = 2
and
That is, the n 1 S 1 i and S 1 j possible samples are {ab, ac, bc}
Though Eq. (1) allows handling any distribution of properties and sample probabilities, assume for simplicity that each sample has an equal probability of being selected and, thus, p i = p j = 1/n 1 = 1/3 (for an example with an unequal frequency distribution of properties, see Appendix A). Then, using Eq. (1),
In Eq. (B4), the double summation corresponds to the sum of counts of coincidences between each sample S 1 i and S 1 j , for example:
#(S 11 ∩ S 11 ) = #(ab ∩ ab) = 2
#(S 11 ∩ S 12 ) = #(ab ∩ ac) = 1 and so on until,
#(S 13 ∩ S 13 ) = #(bc ∩ bc) = 2
For this example, each term of the double summation is
Hence, p(a1) = 12/18 = 2/3
From inspecting the example presented in Fig. 1, it is easily seen that a given property contained in a sample of size s 1 will be also contained in two out of all possible three randomly selected samples of the same size. Note that this is precisely the value obtained above (i.e., 2/3). Although not readily apparent, we treated the example above as a case of equiprobable properties (all properties have an equal chance of being selected in a sample, and thus all samples have an equal probability of occurring). Importantly, note also that s 1 /k 1 = 2/3. This is not coincidental. In fact, it is always true that for equiprobable properties, Eq. (1) reduces to:
This is an important property, and it aids in understanding p(a1) (a demonstration may be found in Canessa & Chaigneau, 2016). Examining Eq. (3) readily shows that the probability of true agreement is a measure of the agreement in conceptual content among subjects, so that the larger the total number of properties describing a concept (k 1 ) compared with the average number of properties that describe the concept in people´s conceptual content samples (s 1 ), the smaller p(a1), and vice-versa. Thus, it is clear that k 1 and s 1 are mathematically related to p(a1). All other things being equal, as k 1 increases while leaving s 1 constant, p(a1) decreases. A smaller s 1 relative to k 1 implies that it is more difficult to find coincidences between the s 1 sized samples. In contrast, as s 1 increases while leaving k 1 constant, p(a1) increases.
The same discussion above about s 1 and k 1, is valid for the general (and more realistic) case of non-equiprobable properties expressed in Eq. (1). To understand why this is the case, first consider that Eq. (3) is also a lower bound on p(a1), i.e., p(a1) cannot take a value smaller than the one in Eq. (3) (see a demonstration in Appendix B). There is an intuitive explanation for the lower bound. If all samples (i.e., combinations of properties) were equiprobable, and we increased the probability of one of those samples (i.e., if we made the samples not equiprobable), then there would be an increased probability of that sample being chosen for comparison. By Eq. (1), this means that p(a1) increases. In contrast, if we were to decrease the probability of one of those samples, other samples would increase in probability (given that the sum of all the probabilities for all samples must be one), meaning that p(a1) could not in any case be smaller than s 1 /k 1 . Consequently, p(a1) calculated by Eq. (1) will always be larger than s 1 /k 1 .
We can express the idea above as p(a1) = θ s 1 /k 1 , with θ > 1. Of course, the value of factor θ will vary depending on the parameters p i , p j (i.e., the frequency distribution of properties), but the key issue is that θ will always be bigger than one. Now, given that p(a1) = θ s 1 /k 1 , and θ > 1, this means that an increase in s 1 will also increase p(a1) (apart from the effect of θ ) and an increase in k 1 will also decrease p(a1) (apart from the effect of θ ). In our analyses, we will use this mathematical relation as a validity check. If our formulations are correct and in fact have empirical content, they should pan out in data from any CPN study.
Equation (1) does not exhaust the issues of intersubject variability. What is not clear from Eq. (1) is that k 1 and s 1 are also related to each other. An analysis of the role of the PLT in CPNs shows that the only way in which k 1 can increase is by an increase in s 1 (i.e., everybody produces longer lists with the same content, and thus k 1 will be larger), or by an increase in the diversity from one list to another (i.e., if lists contain low frequency properties that tend not to be repeated in other lists, then k 1 will increase because k 1 is the combination of all the different lists). Furthermore, it seems that the longer the individual lists are, the higher the probability that those lists will contain low frequency properties that are not repeats in other lists (e.g., idiosyncratic properties). When lists are accumulated across subjects, as is done in a CPN study, it seems intuitive that the longer the lists, the higher the probability that those lists will contain properties that are not frequently repeated in other lists, thus increasing the total number of properties listed across subjects. Note that this implies an exponential relation. This is our Hypothesis 1a, which states that s 1 and k 1 will be positively related and that their relation will be nonlinear.
Another consequence of this analysis is that we can predict that, though both k 1 and s 1 should correlate with p(a1) (correspondingly, a negative and a positive correlation), it is likely that k 1 will show a higher correlation than s 1 , given that the s 1 parameter contains information only about the number of properties, whereas the k 1 parameter contains additional information about the diversity of properties across subjects, and this latter information is precisely what p(a1) captures. This is our Hypothesis 1b.
From the discussion in the preceding paragraphs, we hope it is apparent that the list length in the PLT (variable s 1 ) should be the critical variable regarding conceptual variability. As it changes, it drives changes in k 1 and in p(a1). Now, recall that in the section on conceptual variability we suggested two different factors that could affect the length and composition of lists in the PLT. We will discuss each in turn, explaining why they should affect s 1 (and consequently, k 1 and p(a1)).
One such factor is exposure. Assuming that increasing exposure leads to learning more about a concept, and therefore to longer lists, we predict that exposure will be positively correlated to s 1 and to k 1 , but negatively to p(a1). Thus, because as people have more to report due to exposure, there will presumably be a greater chance that their reported list will contain different properties, decreasing p(a1). This is our Hypothesis 2.
Another factor that could affect s 1 is the generality of properties. As we have already discussed, the statistical structure of concept to properties relations implies that some properties are shared across concepts. Here, we refrain from speculating about why this is the case. The fact is that properties vary in how general or distinctive they are, depending on how many concepts contain them. Assuming that general properties are fewer than distinctive properties, we predict that generality will be associated with shorter lists, a lower chance of having different properties across lists, and an increased p(a1). This is our Hypothesis 3.
Data
In this work, we used two publicly available norm studies. Our main data comes from the Centre for Speech, Language and the Brain concept property norms (from here and on, the CSLB norms; Devereux, Tyler, Geertzen, & Randall, 2014). To perform other secondary analyses, we used the SUBTLEX-UK British English word frequency database (from here and on, the SUBTLEX-UK norms; van Heuven, Mandera, Keuleers, & Brysbaert, 2014). We will describe each in turn. Table 2 shows a list of all variables used throughout the analyses that follow. For each variable, we indicate its name, in which of the two sets of norms it is found, and how it is computed.
Participants in the CSLB norms (n = 123; 18–40 years of age) were presented with a set of 30 concrete concepts, and asked to produce at least five properties for each. The task was performed online, and subjects could participate in more than one session. Interestingly for our purposes, the CSLB norms contain more detailed information than other comparable norms. Not only does it provide the frequency distributions for each of the 638 concepts, but also the specific properties produced by each subject (allowing us to compute the s 1 parameter). Just as importantly, the CSLB norms retain all properties produced by at least two subjects. This allowed us to compute a p(a1) that is representative of the original intersubject variability in the norms.
The SUBTLEX-UK word frequency norms were obtained by collecting words from the subtitles of nine British Broadcasting Corporation channels during a 3-year period (over 45,000 broadcasts). This produced a register of 159,235 word types, and a total number of approximately 201.3 million word tokens. To combine both sets of norms, we searched in the SUBTLEX-UK norms for the 638 concrete nouns in the CSLB norms. Of those, we were able to unambiguously identify 603 which were in both sets of norms. Thus, we supplemented the CSLB norms with data for frequency of occurrence in natural language for 603 concepts.
We inspected all our variables to check for departures from normality. As Table 3 illustrates, our variables are in general slightly positively skewed and leptokurtic. However, visual inspection showed they do not deviate noticeably from normality.
Analyses
Note that our theory views all our different variables as interrelated (as is evident from Eqs. (1), (B3), and (3)). However, for practical purposes, we fractioned these relations and used multiple regression as our fundamental tool. Because we had reasons to predict non-linear relations between some of our variables (as per our discussion of the k 1 to s 1 relation), we used linear and quadratic terms and then chose the best model according to the following criteria. We first built a complete model with linear and quadratic terms. A Variance Inflation Factor (VIF) greater than 10 suggested a problem of multicollinearity among predictor variables (Hair, Anderson, Tatham, & Black, 1992). We handled this multicollinearity by building separate linear and quadratic models. If the predictors in the combined model were non-significant, but became significant when considered separately, then this corroborated the multicollinearity problem. In this latter case, the complete model was never preferred over its alternatives. When two or more models remained possible, they were evaluated depending on statistical significance, magnitude of their unstandardized coefficients, overall explained variance, and parsimony (i.e., all other things being equal, we preferred linear to quadratic models).
How does the number of properties affect the PLT?
Does increasing k 1 decrease p(a1)? Recall that Eqs. (1) and (3) imply that variability in conceptual content should increase (i.e., a decrease in p(a1)) as a function of the total number of properties produced by a group for a given concept (i.e., k 1 ). This is our validity check. An additional issue we wanted to address was whether the relation between k 1 and p(a1) is linear or not. Thus, we calculated k 1 and p(a1) for each of the 638 concepts in the CSLB norms, and computed a regression equation with k 1 as predictor and p(a1) as criterion variable. To test for nonlinearity, we added a quadratic term to the equation (i.e., k 1 2).
As Table 4 (model 1) shows, the complete model is statistically significant, as are both its linear and quadratic coefficients. Furthermore, the model has an R2 of 0.353, and its VIF is lower than 10 (thus, we had no concerns of multicollinearity). Hence, we can say that indeed as k 1 increases, p(a1) decreases, but that this decrement tends to stabilize at higher k 1 values.
Does increasing s 1 increase p(a1)? This is also part of our validity check. Equations (1) and (3) imply that as s 1 increases, so should p(a1). In words, all other things being equal, as people individually produce more content for a given concept, this content should become less variable. Just as above, an additional issue we wanted to address was whether the relation between s 1 and p(a1) is linear or not. Thus, we calculated s 1 and p(a1) for each of the 638 concepts in the CSLB norms, and computed a regression equation with s 1 as predictor and p(a1) as criterion variable. To test for nonlinearity, we added a quadratic term to the equation (i.e., s 1 2).
Results showed that the complete model is statistically significant, but with a low R2 of 0.034. As shown in Table 4 (model 2), the linear and quadratic coefficients are both significant. Notably, the model’s VIF was 59.13, which led us to suspect multicollinearity. Thus, we built two additional models, each with one term (either the linear or the quadratic one; see Table 4, models 3 and 4). The linear model is significant, with a very low R2 of 0.008. The linear coefficient is also significant. The quadratic model is non-significant, with a very low R2 of 0.005. Because there is no clear evidence of multicollinearity (i.e., both coefficients in model 3 are significant), we decided between models by comparing R2s. Here, the complete model’s R2 (model 2) was significantly greater than the single predictor models’ (for the linear model, F(1,635) = 16.9; p < .001; for the quadratic model, F(1,635) = 19.14; p < .001). Therefore, the complete model is the overall best. Thus, as expected, p(a1) increases as s 1 also increases. Note that the negative quadratic coefficient in model 2 in Table 4 indicates that as s 1 increases, its positive effect on p(a1) decreases, such that p(a1) exhibits a maximum (see Fig. 2).

Graph of model 2 in Table 4, showing the relation between s 1 (mean list length) and p(a1) (true agreement probability) for 638 concepts
One further analysis we needed to perform was to compare the correlation of s 1 and p(a1) versus that of k 1 and p(a1). Recall here that our Hypothesis 1b was that s 1 is bound to show a smaller covariance with p(a1) than k 1 , due to k 1 growing from an increase in sample size and from the inter-individual differences in sample content. This analysis showed that the rxy between p(a1) and k 1 is −0.566 (p < .001) and the one between p(a1) and s 1 is 0.089 (p = 0.024). A z test for dependent correlations with a shared term (Steiger, 1980) showed that this is a significant difference (z = −23.5; p < .001).
Because s 1 and k 1 have divergent effects on p(a1) (i.e., as per Eqs. (1) and (3), and as the analyses above confirm), we performed a partial correlation analysis between s 1 and p(a1) controlling for k 1 . If our discussion about the relation between s 1 and k 1 is correct, then controlling for k 1 should increase the R2 between s 1 and p(a1), relative to when no control was performed (i.e., in the regression analysis above). As we predicted, the partial correlation between s 1 and p(a1) controlling for k 1 is 0.801 (p < .001). This is an 81-fold increase in explained variance relative to the corresponding correlation with no control (i.e., .089).
Does increasing s 1 increase k 1 ? Recall that we expected that an increase in individual content being produced (i.e., s 1 ) should increase the group-level number of properties (k 1 ). This is our Hypothesis 1a. Furthermore, recall that we expected this relation to be nonlinear. To this end, we computed a regression equation with s 1 and s 1 2 as predictors and k 1 as criterion.
Results showed that the complete model is statistically significant, with an R2 of 0.484. As shown in Table 4 (model 5), the linear term is non-significant, while the quadratic term is significant. However, because the VIF is 59.13 (i.e., greater than 10), we suspected multicollinearity and computed a regression equation with only the quadratic term (shown in Table 4, model 6). This model is also significant and exhibits the same R2 as before (0.484), with a significant quadratic coefficient. Thus, our data corroborates our hypothesized non-linear relation between s 1 and k 1 (see Fig. 3).

Graph of model 6 in Table 4, showing the relation between s 1 (mean list length) and k 1 (total number of properties) for 638 concepts generality, but the quadratic term suggests that
How does exposure affect the PLT?
Does exposure affect s 1 ? Recall that we hypothesized that, assuming that being exposed to a concept leads to learning more about it, exposure would lead to people having more conceptual content to inform (i.e., increasing s 1 ). This is our Hypothesis 2. We used word-frequency as a proxy for exposure. The SUBTLEX-UK norms provided us with a measure of how often someone might encounter a linguistically encoded concept in natural language settings. A total of 603 concepts in the CSLB norms were also found in the SUBTLEX-UK word-frequency norms, and so the following analyses are based on them. Because of the long-tailed distribution of word frequency and the clustering of data points in the low-frequency values, we computed the base 10 logarithm of the frequency reported in the SUBTLEX-UK norms. This is a usual practice when handling this type of distribution (Kleinbaum, Kupper, & Muller, 1988). Henceforth, we label this variable log10(exposure).
We submitted the s 1 and log10(exposure) values to a regression analysis with log10(exposure) and its squared value as predictors (see Table 5, model 1). Results showed that the complete model is statistically significant, with an R2 of 0.138. However, as shown in Table 5 (model 1), neither the linear term nor the quadratic term are significant. Furthermore, the model’s VIF is 45.57, suggesting that variables exhibit multicollinearity. Thus, we performed two separate regressions, one with log10(exposure) as predictor and another with squared log10(exposure) (see Table 5, models 2 and 3). The linear model yields a significant R2 of 0.138, with a significant coefficient. The quadratic model is also significant, with an R2 of 0.136, and a significant coefficient. Given that the R2s for models 2 and 3 are similar, based on parsimony we preferred the linear model. However, recall that the predictor is a logarithmic transformation, meaning that the relation between s 1 and the original exposure values is actually non-linear. That is, relative to the original untransformed variable, an increase in exposure at the small exposure range increases s 1 much more than the same increase at the large exposure range. In other words, there is a saturation effect between exposure and s 1 , where the increase in s 1 due to an increase in exposure is much bigger for small values of exposure than for larger ones.
Does exposure affect k 1? Consistent with the analysis above, we expected that the log10(exposure) values also predicted k 1 . Thus, we computed a regression equation with log10(exposure) and squared log10(exposure) as predictors, and k 1 as criterion. As shown in Table 5 (model 4), the complete model is significant, with an R2 of 0.075 and a VIF of 45.57. Furthermore, neither the linear nor the quadratic coefficients are significant. Thus, due to multicollinearity concerns, and as done before, we computed two separate models. The linear model (Table 5, model 5) yields a significant R2 of 0.075, and a significant coefficient. The quadratic model (Table 5, model 6) also shows a significant R2 of 0.075, and a significant coefficient. Given the equivalent R2s, for parsimony we chose the linear model. This model shows that exposure indeed increases k 1 . Here again, since the predictor is log10(exposure), the relation between exposure and k 1 is actually non-linear, with the same saturation effect explained before.
Does exposure affect p(a1)? Recall that part of our Hypothesis 2 holds that exposure should affect p(a1). Thus, as we have shown, exposure has a positive relation with s 1 and k 1 , and both these variables relate to p(a1). Because from our two previous analyses we know there is a multicollinearity problem with log(exposure) and log(exposure)2, we did not compute the complete model. Instead, we went on to directly compute two separate models, regressing p(a1) on log10(exposure) in the first and on log10(exposure)2 in the second (respectively, models 7 and 8 in Table 5). Both models are not significant, suggesting an absence of effect of exposure on p(a1). As a way of testing for the independent (i.e., mutually controlled) effects of s 1 , k 1 and log10(exposure) on p(a1), we built a third model in which we regressed p(a1) on s 1 , k 1 and log10(exposure). This model is significant (F(3,599) = 619.6, MSe = .001; p < .001) and has an R2 of 0.756. The coefficient for s 1 is 0.042 (t(599) = 31.3; p < .001), for k 1 is −0.009 (t(599) = −42.884; p < .001) and for log10(exposure) is 0.002 (t(599) = 1.02; p = .306). Thus, the effects on p(a1) are positive for s 1 , negative for k 1 , and null for exposure.
In hindsight, though contrary to our hypothesis, this result does not appear surprising. From our analysis in the Theory section, we know that k 1 and s 1 are related. The only way in which k 1 can increase is if subjects in a CPN study produce longer lists that have the same content, or by an increase in the diversity from one list to another (i.e., if lists contain low frequency properties that tend not to be repeated in other lists). Our results suggest that in the CSLB norms, exposure increases both components of lists, leading the s1/k1 proportion to remain approximately constant. From Eqs. (1) and (3), this means that such a factor would be unable to correlate with p(a1).
How does generality affect the PLT?
Are generality and s 1 related? Recall here that generality is the number of categories in the CSLB norms in which a property appears. As discussed in the section on Theory, if generality is to have an effect on conceptual variability, it should relate to s 1 (this is our Hypothesis 3). For this analysis, we tested whether s 1 was able to predict the average generality of properties produced for each of the 638 concepts in the CSLB norms. To this end, we computed a regression equation with average generality as criterion, and s 1 as predictor. Again, as done before, we added an s 1 2 quadratic term as predictor (see Table 5).
The complete model (see Table 5, model 1) is significant, and with a small R2 of 0.061. However, neither the linear nor the quadratic coefficients are significant and the VIF is 59.13, indicating multicollinearity. Thus, we computed two separate regressions, one with s 1 as predictor and the other with s 1 2. The model with s 1 (see Table 5, model 2) is significant as a whole, has a significant coefficient, and its R2 is 0.059. The model with s 1 2 (see Table 5, model 3) is also significant as a whole, has a significant coefficient, and its R2 is 0.06. As the two R2s are very similar, we selected the simpler linear model. Consequently, our results show that the more individuals can report about a concept, the more distinctive (less general) are those properties, though this is a small effect.
Are generality and k 1 related? Given that generality is related to s 1 , and k 1 is affected by s 1 , it is reasonable to expect that generality affects k 1 . Moreover, since the relation between generality and s 1 is negative, and between s 1 and k 1 is positive, we should expect a negative relation between generality and k 1 . To test that, we regressed mean generality on k 1 and k 1 2. The complete model (see Table 5, model 4) and its two coefficients (linear and quadratic) are significant, and it shows an R2 of 0.139. Because the complete model’s VIF is lower than 10 and both coefficients are significant, we retained this as our preferred model. Thus, a higher k 1 entails a lower mean this negative effect saturates as k 1 increases (see Fig. 4).

Graph of model 4 in Table 5, showing the relation between k 1 (total number of properties) and Average Generality for 638 concepts
Notably, our data show that k 1 is able to predict much more of generality than s 1 (more than twice the explained variance). This dovetails nicely with our previous results, and suggests that low generality properties (i.e., distinctive properties) tend to be low frequency properties (i.e., properties reported by relatively few subjects). If this is the case, a decrease in the generality of properties being produced by a group of subjects, must imply a relatively large increase in k 1 (due to more distinctive properties having a greater chance of being low frequency, non-shared properties, and thus contributing more to an increase in k 1 ). We will offer a test of this explanation later.
Are generality and exposure related? We know from our previous results that s 1 and exposure are related. Thus, it is likely that average generality and exposure are also related. Given that we already know that log10(exposure) exhibits multicollinearity with log10(exposure)2, we estimated two separate models for predicting average generality (see Table 5, models 5 and 6). The model for log10(exposure) and its coefficient are significant, and shows a small R2 of 0.036. The corresponding quadratic model and its coefficient are also significant, with a similarly small R2 of 0.036. As done before, for parsimony we retain the linear model for interpretation. Note that though the relation is linear, the predictor is a logarithmic transformation, and thus the relation between exposure and average generality is non-linear, with a much more prominent decrease in average generality for increases in exposure when exposure is small than when it is large (i.e., the saturation effect already explained for exposure and k 1 ). Note also, that the overall effect is small (3.6%), which seems consistent with the null effect we found between exposure and p(a1).
Are generality and p(a1) related? Given that less average generality in the properties produced in a PLT associates with an increased k 1 , and that k 1 has a negative effect on p(a1), we expected a positive relation of average generality and p(a1) (i.e., concepts with a greater average generality of their properties, should show a higher p(a1)). This is our Hypothesis 3 again. To assess this, we built a model with average generality and squared average generality as predictors of p(a1) (see Table 5, model 7). This model is significant, with an R2 of 0.117. Both, the linear and the quadratic coefficients are also significant. However, given that the VIF is 21.87, bigger than 10, we suspected multicollinearity and built two separate models. The linear model and its coefficient are significant (see Table 5, model 8), with an R2 of 0.089. The quadratic model and its coefficient are also significant (see Table 5, model 9), and it has an R2 of 0.107. To decide if the linear component should be kept in the complete model, we compared models 7 and 9 regarding their R2 values. The test showed that the complete model explained significantly more variance than the one with only the quadratic term (F(1, 635) = 6.832; p < .01). Thus, as generality increases, there is a slight positively accelerated tendency to increase p(a1).
Are property generality and property frequency related? Recall that when we analyzed how average generality and k 1 are related, we reasoned that our pattern of results implied that properties that are more distinctive must tend to be low frequency properties (i.e., non-shared properties that, in the PLT, are produced by fewer subjects), in contrast to general properties, which must have a relatively higher frequency. This is a novel prediction, not anticipated in our theoretical analysis. To test this explanation more directly, we correlated generality across the 638 concepts in the CSLB norms, with property frequency. Just as happens with exposure, the distribution of generality at the property level is highly skewed, and thus we applied a base 10 logarithmic transformation to it (henceforth, log10(generality)). Because log10(generality) is a property level variable, and property frequency is a property by concept level variable, we could not accumulate these variables across concepts to perform a single analysis. Consequently, we computed a separate linear correlation between these two variables for each of the 638 concepts in the CSLB norms, and then submitted these correlation values to a t-test with the null hypothesis that Rho = 0. This test showed that the mean correlation value (mean r = .229; S.D. = .158) was significantly different from zero (t(637) = 36.6; p < .001).
To provide further evidence, we counted the number of concepts that exhibited the same correlation sign. Of the 638 concepts, the correlation between log10(generality) and property frequency was positive in 588 concepts (more than 92%), and significant (at α = .05) in 149 of them. Importantly, only 50 concepts showed a negative correlation (less than 8%), none of which was significant. Thus, for most concepts there is a tendency for general properties to be listed more frequently than distinctive properties. It is important to note here that because log10(generality) is a logarithmic transformation, the relation between the original generality measure and property frequency is really nonlinear, such that at low values of generality, a small increase in generality implies a relatively large increase in property frequency; whereas at higher values of generality, the same small increase in generality implies a relatively smaller increase in property frequency. Just as we have shown for earlier analyses, the effect of generality on property frequency saturates as generality increases.
Discussion
In this work we aimed at contributing to a better understanding of the PLT. This task is widely used in psychology, but little is known about its characteristics. An often overlooked aspect of the PLT, but that we used as our starting-point, is that people typically produce different sets of properties. Here, instead of dealing with this inter-subject variability in conceptual content by treating it as measurement error, we used it as the driving force in our analyses. To that effect, we used a formula that includes the average size of lists provided by subjects in a CPN study, the total number of properties listed at the group level, and the frequency distribution generated by those lists, to compute a measure of inter-subject variability (p(a1)). Aided by this mathematical machinery, and by combining two sets of publicly available norms (the CSLB and the SUBTLEX-UK norms), we investigated how variability relates to concept exposure, property generality, and property production frequency.
Rather than offering a summary of our results in a piecemeal fashion, in this section we integrate them to offer a characterization of the PLT and its relation to inter-subject variability. To favor readability, in this discussion we will mostly use the verbal descriptions of the relevant variables, rather than the corresponding letters or abbreviations used in data analysis. The basic element of this characterization is that lists of conceptual properties produced in the PLT are mixtures of properties of different levels of generality. Low generality properties are less likely to appear in individual conceptual properties lists than higher generality properties. This effect is stronger at the lower end of the generality scale. A simple explanation for this is that properties that describe more concepts are more cognitively accessible (cf., Grondin, Lupker, & McRae, 2009).
The nature of these mixtures of properties relates to the length of individual property lists, and, consequently, to the total number of properties informed for a given concept by a group of individuals. Our results show that this latter quantity will be sensitive to any factor capable of changing the mixture of general and distinctive properties, even when the length of individual lists does not change. Because generality correlates with property frequency, less generality (i.e., more distinctiveness) also implies lower frequencies. These lower frequency properties increase the total count of properties much more than the relatively higher frequency properties. To clarify this, consider the extreme case where everyone produced the same properties. In that case, individual list length and total number of properties would covary linearly. In contrast, due to low frequency properties, there is an exponential relation between average list length and total number of properties. Consequently, the total number of properties for a concept contains information about the distribution of general and distinctive properties in lists. When this distribution skews towards low generality properties, the total number of properties listed for a concept grows, and so does intersubject variability in the PLT. In fact, we found a strong relation between total number of properties and p(a1) (35% shared variance).
A related issue that our results address is what type of factor might affect intersubject variability. A result we did not predict is that though exposure to concepts in naturally occurring language affected mean list length and total number of properties, it did not affect intersubject variability. Apparently, more exposure to a concept in natural language increases the availability of its properties (i.e., more exposure increases mean list length and total number of properties). However, this seems to increase general and distinctive properties to a similar extent. In consequence, the relation between mean list length and total number of properties remains stable and so does p(a1). This suggests that exposure as defined in the current work does not change the distribution of general and distinctive properties that are experienced (i.e., it has no effect on semantic structure). If we were to perform an experiment where people were put in high and low exposure conditions in a natural language environment, we would presumably see that with both conditions they would experience the same proportions of general and distinctive properties. Note that this does not mean that exposure in general should have this same effect. Other conditions, such as an increase in expertise, might increase exposure to distinctive more than to general properties, and could therefore change the distributions of general and distinctive properties, thus increasing intersubject variability (i.e., decreasing p(a1)). In general, our data suggest that to have an effect on inter-subject variability, a manipulation has to be able to affect the distribution of generality in individual subjects’ property lists.
What we have learned from the current work has methodological consequences for researchers using the PLT. Importantly, we can now understand the effect that weeding out low frequency responses from CPNs may have. Recall that this procedure is reasonable if we assume that low frequency properties reflect measurement error. In contrast, in our approach, low frequency properties reflect bona fide conceptual variability that needs to be taken into account. What weeding out achieves is to decrease k 1 much more than s 1 , thus increasing p(a1). We know now that this procedure has several other consequences. Because production frequency relates to generality in a non-linear fashion, excluding low frequency properties will change the true relation between these variables in the data, such that the relation may now appear linear or perhaps tend to disappear depending on how severe weeding out is. Furthermore, because generality and the total number of properties (k 1 ) are also related, and because distinctive/low frequency properties make an important contribution to the total number of properties (i.e., as per our discussion of the non-linear relation between s 1 and k 1 ), weeding out will portrait data as being higher in generality and less variable than they really are. Because data in CPNs are used with the goal of testing theories and controlling variables, it is apparent that weeding out will change data structure in important ways and perhaps defeat these goals.
A similar analysis applies to property list elicitation procedures. These procedures vary across studies in such a way that will probably affect the number of properties being produced. However, researchers generally fail to explain why they choose those specific procedures, or how they may or may not influence their results. Examples of different procedures abound. A request that asks for typically or generally true properties (e.g., Wu & Barsalou, 2009) seems to ask for more general properties, and therefore might produce shorter lists with fewer low frequency properties and higher average generality. In contrast, a request to provide properties that could help someone to correctly guess the concept (e.g., Rechia & Jones, 2012), might produce property lists with a lower average generality and relatively more intersubject variability. Similarly, procedures also vary in whether properties are elicited in written or spoken format (e.g., respectively, Chang, Mitchel & Just, 2011; Perri, Zannino, Caltagirone, & Carlesimo, 2012), whether participants are asked or not for a minimum number of properties (e.g., Devereux, Tyler, Geertzen & Randall, 2014), and whether they are subject to time limits (i.e., how long participants are allowed to list properties). To the extent that these alternatives promote or limit the property production process, they should have effects on collected data in the lines of what we describe above, making comparisons between studies difficult.
Another issue that our results speak to is the way data from PLT studies are interpreted. Our newly gained understanding of the PLT offers different explanations for prior results. Consider the following example. Perri et al. (2012) set out to use the PLT to test Alzheimer disease (AD) patients. An important comparison in which Perri et al. were interested was the frequency of high versus low generality properties. Their findings showed that AD patients produced significantly fewer low than high generality properties, which they attributed to a greater effect of the disease on distinctive than on high generality properties (i.e., a semantic deterioration). Furthermore, their results also showed that AD patients produced fewer overall properties than the control group. Perri et al. discussed the latter result as consequence of the former. In their analysis, AD patients produced fewer properties because of a greater impairment of distinctive over general properties. However, as our results suggest, an alternative explanation is that producing fewer properties leads to properties that are on average more general. Because AD is typically characterized by a progressive decay of working memory (see Jahn, 2013), and assuming that working memory is necessary to perform the PLT, Perri et al.’s results could really reflect greater working memory limitations, rather than a primary semantic deterioration.
Another example of how our analyses may help interpreting results is the following. The total number of properties produced by a group of subjects for a given concept (i.e., our k 1 variable), is taken to be a measure of the concept’s “semantic richness” (Pexman, Holyk, & MonFils, 2003; Pexman, Lupker, & Hino, 2002). This variable has been shown to have a facilitatory effect in different cognitive tasks (e.g., faster reaction times in lexical and semantic decision tasks for concepts with a greater total number of properties; Goh et al. 2016; Pexman, Hargreaves, Siakaluk, Bodner, & Pope, 2008; Pexman et al. 2013). Presumably, words with more properties receive stronger word activation. Consistent with the semantic richness effect, Grondin, Lupker, and McRae (Study 3, 2009) found faster reaction times for concepts with a high rather than a low number of properties (approximately 15 vs. 9). However, they also claim to have found that this effect was strongest when concepts’ k 1 properties differed only in their absolute number of shared properties while keeping the number of distinctive properties constant (shared+distinctive, 3+6=9 properties versus 9+6=15 properties), than when they differed only in their absolute number of distinctive properties while keeping the number of shared properties constant (shared+distinctive, 6+3=9 properties versus 6+9=15 properties) (see Grondin et al., 2009, Tables 5 and 6). Remarkably, the interaction was carried largely by concepts with a low total number of properties and half the number of shared relative to distinctive properties (i.e., the 3+6 condition), which showed slower reaction times than the three other conditions. Grondin et al. interpreted their results as a kind of moderation effect where the semantic richness effect is stronger when shared properties rather than distinctive properties are varied. Our current work suggests the following caveat regarding this interpretation.
Throughout our analyses, we used property generality as a continuous dimension, in contrast to arbitrarily distinguishing between shared and distinctive properties. Because Grondin et al. dichotomized this dimension and separately varied the absolute number of shared or distinctive properties, average property generality may have been a confounding factor. In fact, assuming that individual properties are shared or are distinctive to approximately the same degree across conditions (which is a necessary condition for their design to be correct), then average generality will be a linear function of shared over total number of properties (the higher this proportion, the more general in average properties are). For the four conditions discussed above, this gives, respectively, 3/9=.33; 9/15=.6; 6/9=.67; 6/15=.4. Obviously, the estimated average property generality was not constant across conditions. Furthermore, though estimated average property generality appears to be constant across the number of properties manipulation (respectively, (.33+.67)/2=.5; (.6+.4)/2=.5), it might not have been so across the shared versus distinctive manipulation (respectively, (.33+.6)/2=.47; (.67+.4)/2=.54). This would explain why Grondin et al., somewhat puzzlingly, obtained faster reaction times when distinctive properties were manipulated (i.e., consistently with our results, higher generality produces a processing advantage). Interestingly, the condition with the lowest estimated average property generality (i.e., the 3+6=9 condition) is the one that produced the slowest reaction times, which may suffice to explain the purported interaction.
Conclusion
Throughout the current work, we have analyzed the PLT and its relation to intersubject variability. Our results have shown the PLT’s complexities. Rather than reiterating them, we want to close by noting that intersubject variability seems to be an unavoidable feature of conceptual content. Instead of treating variability as problematic measurement error, we offer a way to describe it and to characterize factors that could systematically affect it. Our results suggest that a researcher using the PLT should carefully consider the effects that limiting the number of properties will have on their data (either because of elicitation procedures or because of weeding out); that they should also consider that variables of interest (such as property generality and list length) are not independent but relate in complex and often non-linear ways; and that they should not arbitrarily dichotomize variables such as those discussed in the current work. By pursuing our strategy, we hope not only to have gained a greater understanding of the PLT, but also to contribute to a better comprehension of CPNs and the nature of the uncovered conceptual structures.
References
Ashby, F. G., & Alfonso-Reese, L. A. (1995). Categorization as probability density estimation. Journal of Mathematical Psychology, 39(2), 216–233.
Barsalou, L. W. (1987). The instability of graded structure: Implications for the nature of concepts. In U. Neisser (Ed.), Concepts and conceptual development: Ecological and intellectual factors in categorization (pp. 101–140). Cambridge: Cambridge University Press.
Barsalou, L. W. (1993). Flexibility, structure, and linguistic vagary in concepts: Manifestations of a compositional system of perceptual symbols. In A. C. Collins, S. E. Gathercole, & M. A. Conway (Eds.), Theories of memory (pp. 29–101). London: Lawrence Erlbaum Associates.
Brysbaert, M., & New, B. (2009). Moving beyond Kucera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods, 41(4), 977–990.
Canessa, E., & Chaigneau, S. E. (2016). When are concepts comparable across minds? Quality & Quantity, 50(3), 1367–1384. doi:10.1007/s11135-015-0210-4
Chaigneau, S. E., Canessa, E., & Gaete, J. (2012). Conceptual agreement theory. New Ideas in Psychology, 30(2), 179–189.
Chang, K. K., Mitchell, T., & Just, M. A. (2011). Quantitative modeling of the neural representation of objects: How semantic feature norms can account for fMRI activation. NeuroImage, 56, 716–727.
Converse, P. E. (1964). The nature of belief systems in mass publics. In D. E. Apter (Ed.), Ideology and discontent (pp. 206–261). New York: The Free Press.
Cree, G. S., & McRae, K. (2003). Analyzing the factors underlying the structure and computation of the meaning of chipmunk, cherry, chisel, cheese, and cello (and many other such concrete nouns). Journal of Experimental Psychology: General, 132, 163–201.
Devereux, B. J., Tyler, L. K., Geertzen, J., & Randall, B. (2014). The Centre for Speech, Language and the Brain (CSLB) concept property norms. Behavior Research Methods, 46(4), 1119–1127. doi:10.3758/s13428-013-0420-4
Frege, G. (1893). On sense and reference. In P. Geach & M. Black (Eds.), Translations from the philosophical writings of Gottlob Frege (pp. 56–78). Oxford: Blackwell.
Gabora, L., Rosch, E., & Aerts, D. (2008). Toward an ecological theory of concepts. Ecological Psychology, 20(1), 84–116.
Glock, H. J. (2009). Concepts: Where subjectivism goes wrong. Philosophy, 84(1), 5–29.
Goh, W. D., Yap, M. J., Lau, M. C., Ng, M. M. R., & Tan, L.-C. (2016). Semantic richness effects in spoken word recognition: A lexical decision and semantic categorization megastudy. Frontiers in Psychology, 7, 976.
Griffiths, T. L., Sanborn, A. N., Canini, K. R., Navarro, D. J., & Tenenbaum, J. B. (2011). Nonparametric Bayesian models of categorization. In E. M. Pothos & A. J. Wills (Eds.), Formal approaches in categorization (pp. 173–198). Cambridge: Cambridge University Press.
Grondin, R., Lupker, S. J., & McRae, K. (2009). Shared features dominate semantic richness effects for concrete concepts. Journal of Memory and Language, 60(1), 1–19. doi:10.1016/j.jml.2008.09.001
Hampton, J. A. (1979). Polymorphous concepts in semantic memory. Journal of Verbal Learning and Verbal Behavior, 18, 441–461.
Hair, J., Anderson, R., Tatham, R., & Black, W. (1992). Multivariate data analysis (3rd ed.). New York: Macmillan Publishing Company.
Jahn, H. (2013). Memory loss in Alzheimer’s disease. Dialogues in Clinical Neuroscience, 15(4), 445–454.
Kleinbaum, D. G., Kupper, L. L., & Muller, K. E. (1988). Applied regression analysis and other multivariable methods (2nd ed.). Boston: PWS-Kent Publishing Company.
McNorgan, C., Kotack, R. A., Meehan, D. C., & McRae, K. (2007). Feature–feature causal relations and statistical co-occurrences in object concepts. Memory & Cognition, 35(3), 418–431.
McRae, K., Cree, G. S., Seidenberg, M. S., & McNorgan, C. (2005). Semantic feature production norms for a large set of living and nonliving things. Behavior Research Methods, 37(4), 547–559.
McRae, K., Cree, G. S., Westmacott, R., & de Sa, V. R. (1999). Further evidence for feature correlations in semantic memory. Canadian Journal of Experimental Psychology, 53, 360–373.
Murphy, G. L. (2002). The big book of concepts. Cambridge: MIT Press.
Perri, R., Zannino, G., Caltagirone, C., & Carlesimo, G. A. (2012). Alzheimer's disease and semantic deficits: A feature-listing study. Neuropsychology, 26(5), 652–663. doi:10.1037/a0029302
Pexman, P. M., Hargreaves, I. S., Siakaluk, P. D., Bodner, G. E., & Pope, J. (2008). There are many ways to be rich: Effects of three measures of semantic richness on visual word recognition. Psychonomic Bulletin Review, 15, 161–167. doi:10.3758/PBR.15.1.161
Pexman, P. M., Holyk, G. G., & MonFils, M. H. (2003). Number-of-features effects and semantic processing. Memory & Cognition, 31, 842–855.
Pexman, P. M., Lupker, S. J., & Hino, Y. (2002). The impact of feed-back semantics in visual word recognition: Number-of-features effects in lexical decision and naming tasks. Psychonomic Bulletin & Review, 9, 542–549.
Pexman, P. M., Siakaluk, P. D., & Yap, M. J. (2013). Introduction to the research topic meaning in mind: Semantic richness effects in language processing. Frontiers in Human Neuroscience, 7, 723. doi:10.3389/fnhum.2013.00723
Pothos, E. M., & Wills, A. J. (Eds.). (2011). Formal approaches in categorization. Cambridge: Cambridge University Press.
Prinz, J. J. (2005). The return of concept empiricism. In H. Cohen & C. Leferbvre (Eds.), Categorization and cognitive science (pp. 679–694). Amsterdam: Elsevier.
Recchia, G., & Jones, M. N. (2012). The semantic richness of abstract concepts. Frontiers in Human Neuroscience, 6, 315.
Rosch, E. (1973). On the internal structure of perceptual and semantic categories. In T. E. Moore (Ed.), Cognitive Development and the acquisition of Language (pp. 111–144). New York: Academic Press.
Rosch, E., & Mervis, C. B. (1975). Family resemblances: Studies in the internal structure of categories. Cognitive Psychology, 7, 573–605.
Rosch, E., Simpson, C., & Miller, R. S. (1976). Structural bases of typicality effects. Journal of Experimental Psychology: Human Perception and Performance, 2(4), 491–502.
Russell, B. (1997). The problems of philosophy. Oxford: Oxford University Press.
Santos, A., Chaigneau, S. E., Simmons, W. K., & Barsalou, L. W. (2011). Property generation reflects word association and situated simulation. Language and Cognition, 3(1), 83–119.
Schyns, P. G., Goldstone, R. L., & Thibaut, J. P. (1998). The development of features in object concepts. Brain and Behavioral Sciences, 21, 1–17.
Steiger, J. H. (1980). Tests for comparing elements of a correlation matrix. Psychological Bulletin, 87, 245–251.
Tversky, A. (1977). Features of similarity. Psychological Review, 84(4), 327–352.
Van Heuven, W. J. B., Mandera, P., Keuleers, E., & Brysbaert, M. (2014). Subtlex-UK: A new and improved word frequency database for British English. Quarterly Journal of Experimental Psychology, 67(6), 1176–1190. doi:10.1080/17470218.2013.850521
Vigliocco, G., Vinson, D. P., Lewis, W., & Garrett, M. F. (2004). Representing the meanings of object and action words: The featural and unitary semantic space hypothesis. Cognitive Psychology, 48, 422–488.
Wu, L. L., & Barsalou, L. W. (2009). Perceptual simulation in conceptual combination: Evidence from property generation. Acta Psychologica, 132, 173–189.
Acknowledgements
We thank Gorka Navarrete and two anonymous reviewers for their useful comments on earlier versions of this manuscript. This research was carried out with funds provided by grant 1150074 from the Fondo Nacional de Desarrollo Científico y Tecnológico (FONDECYT) of the Chilean government to the first and second authors.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Example of calculation of p(a1) when properties are non-equiprobable
Note that in order to use Eq. (1) we must previously calculate the probabilities of obtaining each of the different possible samples drawn from the concept (i.e. the p i and p j ). Although this is simple to do, that calculation involves many summations and multiplications, making it cumbersome to do by hand. To show it here for the example corresponding to the concept depicted in Fig. 1 for the non-equiprobable case, we will only calculate the probabilities of some of the samples. Recall that the possible samples of size two for the concept {a,b,c} are (ab), (ac) and (bc). Thus:
In (A1) and (A2), remember that the order in which properties a and b are sampled is irrelevant, thus the two permutations of properties (ab) and (ba) are equivalent. Thus, to calculate the probability of combination (ab), we calculate the probability of permutation (ab) (p(ab)) and of permutation (ba) (p(ba)), and given that they are mutually exclusive, we can add them. Also, assume the following frequencies for each property: f(a) = 2, f(b) = 3, f(c) = 5, and hence, p(a) = 2/(2 + 3 + 5) = 2/10 = 1/5 and for p(b) = 3/10 and p(c) = 5/10 = 1/2. In the case of combination p(ab), and putting the corresponding values of p(a), p(b) and p(c) in (A2), we obtain:
Using expressions similar to (A2), the value for p(ac) is 91/280 = 13/40 and for p(bc) = 144/280 = 18/35. Recalling that the number of common properties for all independent samples drawn from the concept is {2,1,1,1,2,1,1,1,2} and applying Eq. (1), we obtain:
Note that p(a1) for non-equiprobable properties (0.69797) is bigger than the one for equiprobable ones (0.66667, see computation in section Theory) as expected.
Appendix B: Demonstration that p(a1) for equiprobable properties is a lower bound on p(a1) for non-equiprobable properties
Let us consider one set:
In this case, the cardinalities of C1 is k 1 . Let’s also denote the size of a sample extracted from C1 as s 1 . Then, the number of such possible independent samples will be: n 1 : total number of possible samples of size s 1 obtained from C1 = \( {n}_1=\left(\begin{array}{c}\hfill {k}_1\hfill \\ {}\hfill {s}_1\hfill \end{array}\right). \)
If each independent sample is an event of a random variable, we can define the set of all possible events as:
So, we have the following probability:
where p i is the probability of obtaining sample S 1 i and p j is the probability of obtaining sample S 1 j .
The probability in Eq. (B3) may be seen as a quadratic form by defining the following matrices:
To calculate a lower bound on p(a1), we must minimize expression (B6). This minimization problem expressed in matrix notation is:
The properties of A are:
-
1.
Symmetric, i.e., A t = A.
-
2.
a ii = s 1 ∀i.
-
3.
s 1 = a ii > a ij ≥ 0 ∀i,j
-
4.
A1 = α 1 or 1 t A = α 1 t, where α is the sum of a row S( L ). S( L ) is a matrix that contains the sum of r common properties between independent samples S i 1 and S j 1 multiplied by the number of samples that contain those r common properties. S( L ) is important for other demonstrations but here we can just take the sum of its rows as a constant α.
The first property indicates that all the eigen-values of A are real numbers and the last property shows that all the rows, and by symmetry, all the columns of A sum the same value. This same property indicates that α is an eigen-value of A and the vector 1 is its respective eigen-vector.
Before solving (B7), we must note that \( \frac{2}{s_1} \) is a constant, and thus will not be considered in solving the problem. Additionally, considering an objective function \( f\left(\boldsymbol{p}\right)=\frac{1}{2}{\boldsymbol{p}}^{\boldsymbol{t}}\boldsymbol{A}\boldsymbol{p} \) and that the solution set where we are working is \( D=\left\{ p\in {\mathrm{\Re}}^{n_1}:{\boldsymbol{p}}^t1=1,\ p\ge 0\right\} \), it is easy to see that the problem has solution, given that the objective function is continuous and D is a closed and bounded set, reaching the minimum value either in the interior of D, when p > 0, or at the frontier of D, when a component of p = 0. Weierstrass theorem guarantees the existence of the minimizer in D.
To solve problem (B7), let us consider the lagrangian:
Note that the restrictions of the type p i ≥ 0 or p i ≤ 0, are not included in the lagrangian, but the so-called complementary conditions, which are μ i p i = 0. Thus, the problem to be solved, KKT (Karush-Kuhn-Tucker) conditions is:
Remembering matrix derivatives, we have:
To solve the lagrangian, let’s first consider that μ i = 0, that is, we will for now suppose that the restrictions that p must be positive are inactive. Then,
Replacing the value of λ* in Ap + λ1 = 0 and using the fact that A1 = α1, we have:
If det(A) ≠ 0, then p* is unique and equal to:
If det(A) = 0, there exist infinite solutions and one of them is the one already found in (B11). The rest of the solutions are of the form:
The constant b ∈ ℜ, is any that gives q* ≥ 0. The vector v, is a linear combination of the eigen-vectors of matrix A associated with the zero eigen-values. Given that p* and q* will allways be positive, we can state that the restriction that p must be positive is met. Notably, see that the solution in (B11) means that all samples drawn from C1 have the same probability (1/n 1 ) and, thus all the properties of C1 are equiprobable. Hence, a lower bound on p(a1) occurs when all properties of C1 are equiprobable.
Rights and permissions
About this article

Cite this article
Chaigneau, S.E., Canessa, E., Barra, C. et al. The role of variability in the property listing task. Behav Res 50, 972–988 (2018). https://doi.org/10.3758/s13428-017-0920-8
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-017-0920-8