PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Digital preservation is crucial to the “persistence” of persistent identifiers. Without a reliable archival solution, if a Crossref member ceases operations or there is a technical disaster, the identifier will no longer resolve. This is why the Crossref member terms insist that publishers make best efforts to ensure deposit in a reputable archive service. This means that, if there is a system failure, the DOI will continue to resolve and the content will remain accessible. This is how we protect the integrity of the scholarly record.
I will write another post, soon, on the reality of preservation of items with a Crossref DOI, but recent work in the Labs team has determined that we have a situation of drastic under-preservation of much scholarly material that has been assigned a persistent identifier. In particular, content from our smaller Crossref members, with limited financial resources, is often precariously preserved. Further, DOI URLs are not always updated, even when, for instance, the underlying domain has been registered by a different third party. This results in DOIs pointing to new, hijacked, and elapsed content that does not reflect the metadata that we hold.
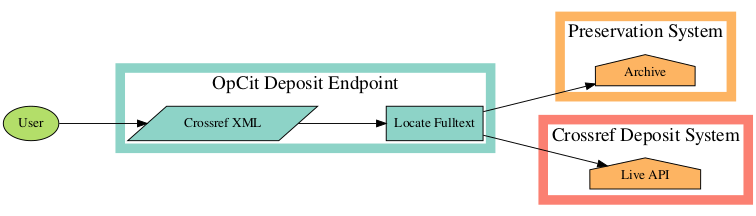
We (Geoffrey) have (has) long-harboured ambitions to build a system that would allow for automatic deposit into an archive and then to present access options to the resolving user. This would ensure that all Crossref content had at least one archival solution backing it and greatly contribute to the improved persistent resolvability of our DOIs. We refer to this, internally, as “Project Op Cit”. And we’re now in a position to begin building it.
However, we need to get this right from the design phase out. We need input from librarians working in the digital preservation space. We need input from members on whether they would use such a service. We are not digital preservation experts and we are acutely aware that we need the expertise of those who are, particularly where we’ve had to take some shortcuts. For instance: we are aware that the Internet Archive is perhaps not the first choice of many digital preservation librarians and specialists, who opt for specific scholarly-communications solutions. However, it is easy, open, and free. Hence, we propose for the prototype to use IA, on the assumption that this will be a proof-of-concept only, which we will expand to other archives if there is demand and once it works.
So: please do read the below and add your comments and questions to this thread in the community forum (link below), or send me queries/concerns by email. It would be excellent if we could receive comments by mid-August 2023. If you would rather comment on a Google doc, that’s also possible.
If enough people are interested, we could also host a community call to discuss this design and its prototyping. Do please, when emailing, let me know if this is of interest.
Project Op Cit (Self-Healing DOIs)
Request for Comment
This document sets out the problem statement, a proposed prototype solution, and a transition path to production if successful.
Proposed Prototype Solution
For members who opt-in to the service, We have a special class of DOI (only for open-access content) where, when the DOI is registered:
We immediately make an archive of the item with any archiving services that care to participate in the project (minimally, the Internet Archive, which is the easiest for us to begin with, but a modular/pluggable archival system). The Internet Archive Python Library should let us submit to them. We could pursue other arrangements with CLOCKSS, LOCKSS, and Portico.
We update the XML to reflect the archives to which it has been submitted.
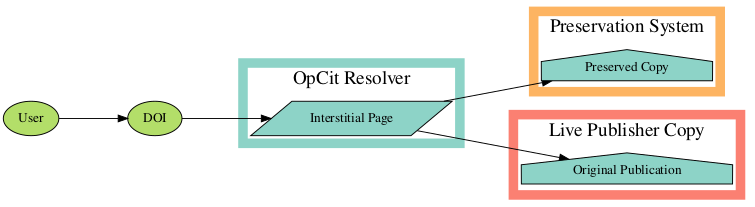
The DOI landing page is redirected to an interstitial page that we control. This page gives the user access options.
We develop processes to determine whether the original URL “works”. The heuristics that define whether a resource has changed substantially or works need long-term consideration and real-world testing. Using the interstitial page approach will allow us to refine this, with a long-term goal of eradicating it.
Figure 1: The Deposit Process
Figure 2: The Resolution Process
Potential Challenges
Content drift. It would be extremely difficult to detect content change vs. (eg) page structure change, except in the case of binary fulltext. However, we can poll for the DOI at an HTML endpoint and detect when binary fulltext items, such as a PDF, change.
Latency on resolver if lookup is real-time. For this reason, we need a periodic crawler so that resolvers do not wait for real-time detection on access.
If using Internet Archive, the domain owner (at the present moment) can request the removal of content. We would need the capacity to “lock” records that are being used as Op Cit redirection archival copies. This requires a further conversation with the Internet Archive.
Prototype Components/Architecture
Registration Proxy and Database (“Fleming”)
The registration proxy implements a pass-through to the deposit API and hosts a relational database of self-healing DOIs (Postgres). It will be hosted at api.labs.crossref.org/deposit/opcit and clients will have to use this endpoint to deposit. Simultaneously, the proxy will:
Determine the license status of the incoming item.
If the license is open and fulltext is provided, deposit a copy in selected digital preservation archives. Store proof of licensing attestation.
In the case of binary files (fulltext PDF), store a hash of the content.
Store the DOI, binary hash, and all URLs in a relational database under “pending” state.
Pass through the request to Crossref’s content registration system.
Monitor the result of this request and remove stored data if registration fails.
Re-registration through Fleming will update existing entries and re-fix their data against content drift at this time.
Spider (“Shelob”)
A series of components that:
Check that “pending” DOIs have been successfully registered. Remove those that have not and move those that have to “active” state.
Dereference “active” DOIs and ensure that we have the most current URL in case updates have gone directly to the live resolver.
Periodically crawl URLs in the self-healing database.
On HTTP 301 code, update database entry to point to new permanent URL.
On HTTP 302 code, follow the temporary redirect expecting the original content.
On HTTP 4xx codes, mark the entry as dead.
On HTTP 200 code of HTML landing page, parse the page for the presence of the DOI. If the DOI is not present, mark the entry as dead.
Resolver Proxy (“Hippocrates”)
Display an interstitial landing page with archival versions and an explanation.
At some future point, for active entries, resolve to the stored URL (faster but could be de-synced) or pass the request to the live resolver (requires an extra hop but will always be in-sync with deposit).
Observability and statistics
Metrics we will collect:
Count of DOIs using Op Cit
Count of visitors arriving on Op Cit landing pages
Usage count of each outgoing link/access option
A daily report will present:
Newly “failed” entries that we believe have died
These will be checked extensively, particularly at first, to ascertain whether our failure heuristics are valid
Entries that have recovered
Errors will be logged and monitored via Grafana.
Documentation and Automated Tests
Core assumptions and new behaviours of the platform will be documented as part of the prototype.
Automated tests will be written, especially for the spider (“Shelob”), which must handle a diverse variety of real-world situations.
Prototype Architecture Requirements
Postgres RDS for resolution/self-healing DOI data (AWS).
FastAPI hosting for passthrough proxy (fly.io).
EC2 hosting for the spider (AWS).
FastAPI hosting for resolver proxy (fly.io).
Transition to Production
If this prototype garners popular appeal, a transition to production would need to keep some prototype components and rewrite others.
“Fleming” would need to be rewritten as a deposit module / integrated with Manifold’s (the next-generation system at Crossref) deposit. If this would create too much overhead, it need not be a blocking process in the deposit.
“Shelob” would continue to need to run continuously and to scale with the adoption of self-healing DOIs unless one of the other options were used.
Prototype architecture will be written so that spidering can be distributed between several servers, if required.
“Hippocrates” would need to be integrated into the live link resolver. Depending on how a field for a self-healing DOI is embedded in Manifold, this may not need any additional database hits.
Back Content
We also have a database of back content stored by the Internet Archive, mapped to DOIs where they have been able to do so. This data source could be used to enable self-healing DOIs on all content in this archive.