PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Crossref strives for balance. Different people have always wanted different things from us and, since our founding, we have brought together diverse organisations to have discussions—sometimes contentious—to agree on how to help make scholarly communications better. Being inclusive can mean slow progress, but we’ve been able to advance by being flexible, fair, and forward-thinking.
We have been helped by the fact that Crossref’s founding organisations defined a clear purpose in our original certificate of incorporation, which reads:
“To promote the development and cooperative use of new and innovative technologies to speed and facilitate scientific and other scholarly research.”
As Crossref prepares to turn 20 in January 2020, it’s an opportunity to reflect on achievements and highlights from 2018-19 and also ponder the preceding decades. Change is a constant at Crossref but the organisation has never strayed from its initial defined purpose. Our services and value now extend well beyond persistent identifiers and reference linking, and our connected open infrastructure benefits our 11,000+ membership as well as all those involved in scholarly research. This expansion is exactly what was envisioned to meet the goal of “speeding and facilitating” research.
This year’s annual report is different from previous years’; it has been expanded into a ‘fact file’ so that we can invite comments on the path ahead, based on transparent access to data about our membership, activities, and finances. As we were pulling together the charts and tables for this annual report we noticed stark differences in where Crossref is today compared to years past.
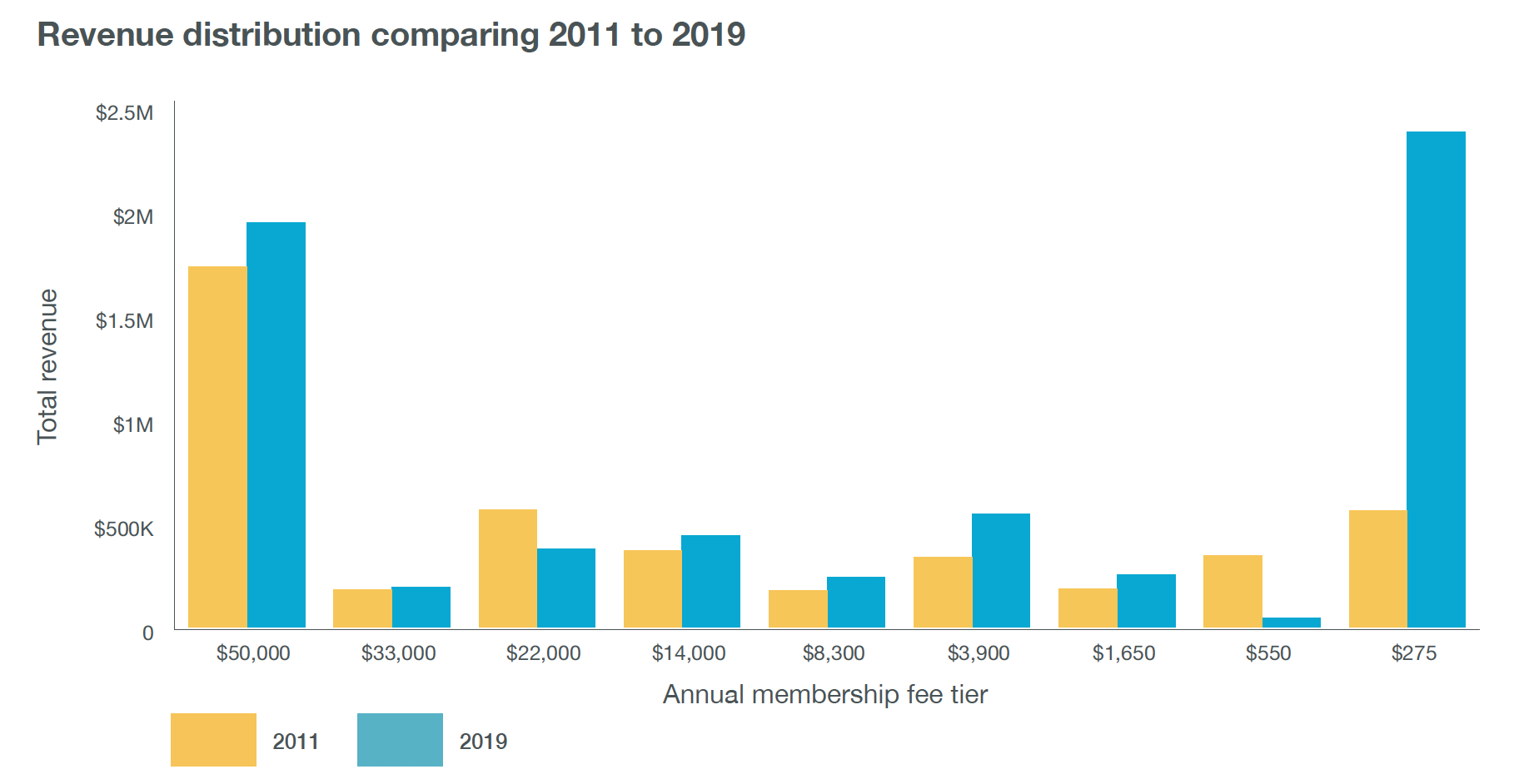
The rate of membership growth has accelerated and we now have over 180 new members joining every month, leading to one of the most striking changes we found. The lowest three membership tiers now account for 46% of revenue (up from 25% in 2011) while the highest three tiers account for 36% (down from 56% in 2011).
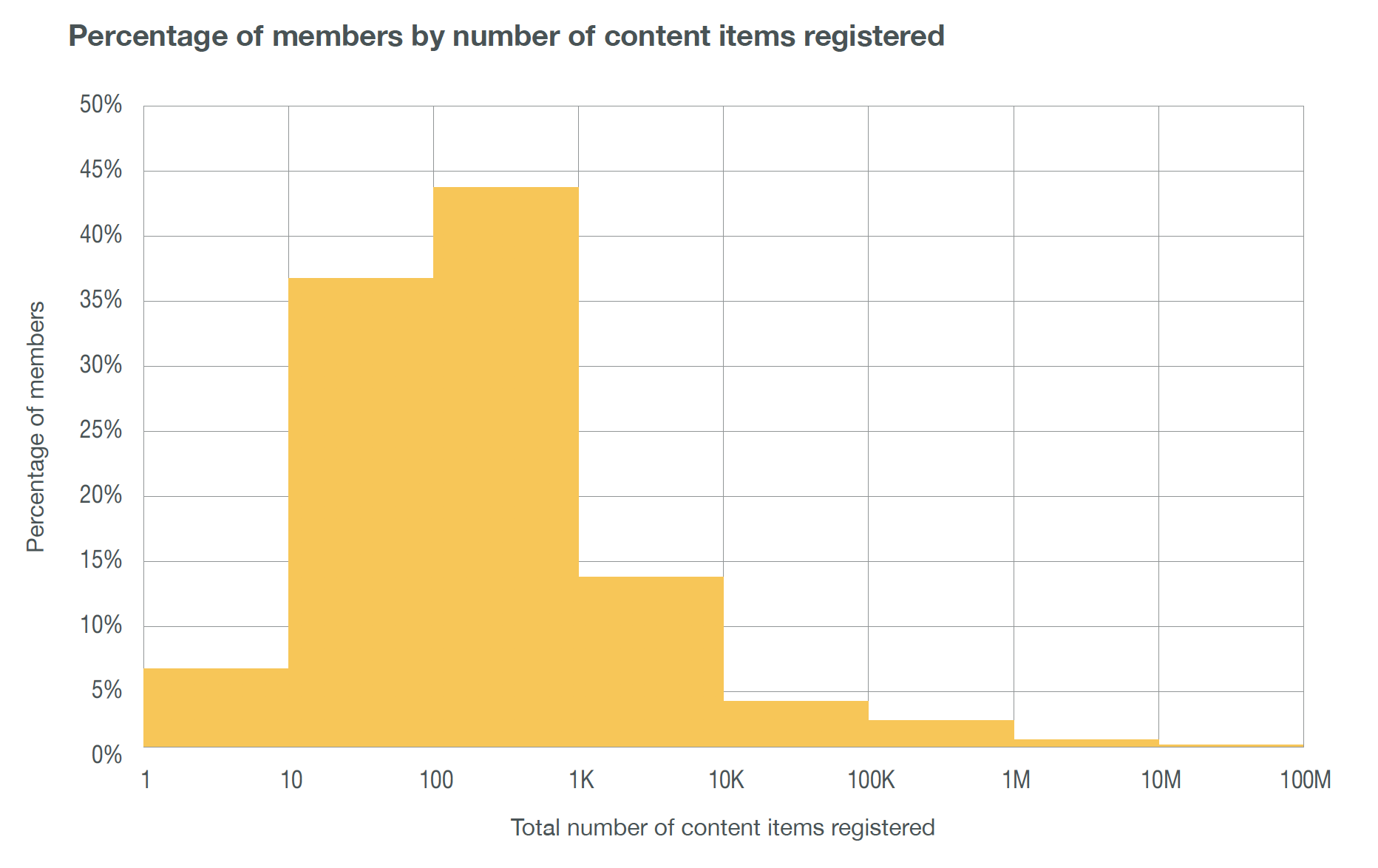
Today, the typical Crossref member has just a few hundred registered content items. One way we have been able to accommodate this growth efficiently is by collaborating with sponsors in different countries. Very small members can join via a local sponsor that is able to provide technical, financial, language, and administrative support. We now have more members joining via sponsors, who otherwise would largely not be able to join at all. While you’d need to be a millionaire by US standards to join directly from Indonesia in our lowest fee tier (calculated using Purchasing Power Parity), the sponsor program—supported often by government investment in science and education—has enabled Indonesian organisations to join Crossref in large numbers, supporting their aim to become one of the fastest-growing nations in open research, and to help that research be discovered.
Crossref has repeatedly stayed ahead of developments in the community
In 2007, when the Similarity Check working group discussions and pilot started, there was disagreement on the board about whether Crossref should provide such a service and whether it was a strategic priority for members. By the end of the pilot, when the decision came to launch a production service, it was seen as essential and a top priority. This conclusion has been borne out in recent research into the value of Crossref; Similarity Check is one of the services of most importance to members.
Adding preprints as a record type was controversial at the time. The board discussed the topic of “duplicative works” for about two years with strong opinions on all sides. The working group delivered a good set of policies and technical specifications and in the July 2015 board meeting there was a majority—but not 100%—agreement on the motion to approve. We implemented preprints as a record type just in time to accommodate the snowballing of preprint servers emerging from existing and new members.
Another example of a former—and current—area of contention is the approach to metadata. When Crossref first launched, there were lengthy discussions about what metadata we should collect. The initial focus was on the minimal set of metadata to enable reference matching in support of reference linking. In the beginning, neither article titles, lists of authors, references, nor abstracts were included in the minimal metadata set. We supported them as optional but most members opted out. However, the huge set of metadata that Crossref collects and disseminates now is seen as essential, providing a lot of value for members in terms of discoverability.
Today, Crossref enables metadata retrieval on a large scale—an average of more than 600 million queries per month—through a variety of interfaces, most notably the REST API (Public, Polite, and Plus versions). The metadata is used by thousands of organisations and services—both commercial and not-for-profit—increasing the discoverability of member content. In fact, members of all stripes have long initiated projects to expand the metadata Crossref is able to collect and disseminate: from facilitating text mining (through license and full-text URLs); to enabling better connections with and evidence of contributions (through Funder IDs, ORCID iDs, and soon CRediT roles and ROR IDs).
These are all examples of where Crossref has successfully “promoted the cooperative use of new and innovative technologies” and where we are meeting our mission to make scholarly communications a little bit better. As ever, we need to thank our brilliant staff for their unfailing resilience, balance, and diligence, in these times of dynamic change.
Considering the value and future of Crossref
Research is global, and supporting a diverse global community is a challenge. This year, we conducted our first wide-ranging investigation into what people value from Crossref. This involved telephone interviews with over 40 community members as well as an online survey of 600+ respondents.
The results of the value research are referenced throughout the annual report/fact file and are available online publicly. We will be discussing the insights in various forums and posing some questions, such as:
How should Crossref balance the different dynamics in the community?
Are the right members involved in key decisions?
Are the sustainability model we have and the fees we charge fair?
Which initiatives should be top or bottom priorities?
“The Crossref of 2040 could be an even more robust, inclusive, and innovative consortium to create and sustain core infrastructures for sharing, preserving, and evaluating research information.”
But only if Crossref is not:
“held back, and its remit circumscribed, by legacy priorities and forces within the industry that may perceive open data and infrastructure as a threat to their own evolving business interests.”
We welcome this public commentary and encourage others in the community to respond and report what value Crossref offers as community-owned infrastructure, and how they’d like to see the organisation evolve.
More than ever, we need to have this discussion with a broad and representative group. So please, read the value research report and the annual report/fact file, and get ready to voice your opinions!