5 minute read.Changes to resolution reports
This blog is long overdue. My apologies for the delay. I promised you an update in February as a follow up to the resolution reports blog originally published in December by my colleague Jon Stark and me. Clearly we (I) missed that February projection, but I’m here today to provide said update. We received many great suggestions from our members as a result of the call for comments. For those of you who took time to write: thank you! We took extra time to review and evaluate all of your comments and recommendations. We have reached a decision about the major proposed change - removal of all filters from monthly resolution reports - as well as a couple of suggested improvements from that feedback.
Quick recap of our original blog
Jon wrote the original version of the resolution report in late 2009 in an effort to provide you, our members, with information about the usage of registered Crossref DOIs. At that time, Jon and others at Crossref thought it important to segment human-driven traffic from resolutions by machines (bots). Thus, we decided to filter out well-known machine activity in an attempt to only present you with resolutions by individual humans.
In the last ten-plus years things changed. We live in a time where most of our work requires both human and machine interaction. Therefore, we have hypothesized that some, or most, of those resolutions from machines today represent legitimate activity and should be reported to you each month. Since we don’t have a reliable method to segment those resolutions, and don’t think we should be making judgments about which resolutions should and should not be included in the reports, we proposed removing all filters and presenting you with all the numbers.
What we heard from you
In addition to soliciting comments in the blog, I also reached out to all of our members who had written into our support desk in the last year about anything related to resolution reports. We received dozens of responses from the blog and my outreach via email. The most common response was from members expressing their appreciation for and highlighting the utility of the reports. Most everyone told us how they were using the reports - from monitoring failure rates to mitigate issues to identifying trends over time. And a great number of respondents expressed concern that removing the filters might alter how or what we present to you in the reports (more on that soon). And, finally, several of you shared suggestions for improvement.
Where we go from here
Our existing filters have been removing between 100 and 150 million resolutions from the monthly numbers we report to all members, collectively. Based on those figures, when we remove the filters all resolutions numbers will increase by about 25%. Those increased resolutions will vary from member to member because the numbers are based on actual bots crawling specific content, so some members may see more of an increase than others. We are mindful of how our members might adjust to that new baseline, since these changes will mean a noticeable (and, significant) increase in resolution totals for the majority of our members.
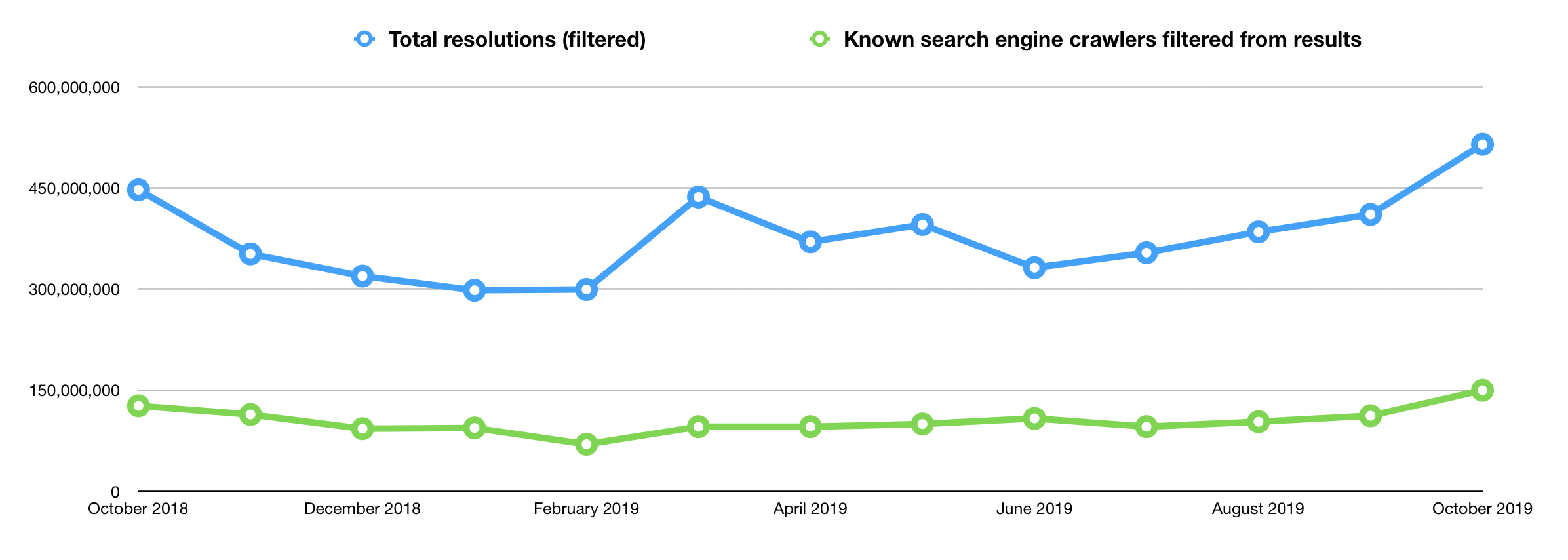
Outside of the suggested tweaks from members below and that 25% increase I mentioned (due to the retirement of the filters), the reports will remain unchanged. You’ll continue to receive successful resolutions, the report of top 10 DOIs, and the csv file containing failed resolutions. Our most important consideration throughout this process is that these reports continue to serve you.
The changes
We liked some of your suggestions, so we’re set to adopt a few of the more straightforward improvements. Those that are more complicated we’re considering for the Member Center (working title, subject to change) project, where we will start to bring together all business and technical information for our members, service providers and metadata users.
- As I said, we’re removing the filters. Starting in June, we’ll present all of the resolutions to you. No filters. On average, monthly resolution numbers will therefore increase by about 25%.
- We currently link to the failed DOI.csv near the bottom of the resolution report. For many members with large volumes of content, the resolution report can take some time to load and sift through, so we’re moving the link to the failed DOI.csv file up the page (Note: we know they are other changes we can make to the report itself that will make it easier to work with for members with large volumes of data; we’re exploring those improvements).
- We learned during this process that some members were not receiving resolution reports when they only had failed resolutions. One of the aims of the reports is to help members identify content registration problems, so this was a bug we are keen to repair. We are fixing it. Once it is fixed, all members who have at least one resolution - successful or failed - during the previous month will receive the report.
What we can’t change
Many members who responded to the call and who also enquire throughout the year (outside of this call) express interest in receiving more information from the resolution reports. You want resolution numbers for all your DOIs. You want referral information about where the resolutions are coming from (e.g., IP addresses) and breakdowns by machine/human. You want more information about how and why the failure rate is growing over time. We understand.
In the past, we did try to process more information for IP addresses and user agents but it turns out that generating that volume of extra data and processing monthly is simply impractical. The other issue is one of privacy. IP addresses are considered personally identifiable information (PII), or data that could potentially be used to identify particular people. We are committed to maintaining the privacy of our members and users and therefore cannot provide this level of granularity in our reports.
Next up
Look for these changes starting in June. If you read this far, you may not need it, but we’ll also include a reminder atop the report itself about the increase in resolution totals as a result of our changes.
Further reading
- Dec 17, 2019 – Resolution reports: a look inside and ahead
- Jan 25, 2024 – Solving your technical support questions in a snap!
- Jun 30, 2026 – Building, refining, and connecting: summary of our May 2026 community update
- Mar 30, 2026 – DOI resolution and deposit outage on 17 March 2026
- Feb 3, 2026 – Innovation in scientific publishing and its implications for Crossref DOI registration practices - MetaROR’s approach
- Nov 6, 2025 – The sunset is on the horizon for Metadata Manager. What's next?
- Sep 25, 2025 – Innovation in scientific publishing and its implications for Crossref DOI registration practices - Request for input
- Jun 24, 2025 – Scholarly blogs and their place in the research nexus




