PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
It can be a pain when companies rebrand as it usually requires some coordinated updating of wording and logos on websites, handouts, and slides. Nevermind changing habits and remembering to use the new names verbally in presentations.
Why bother?
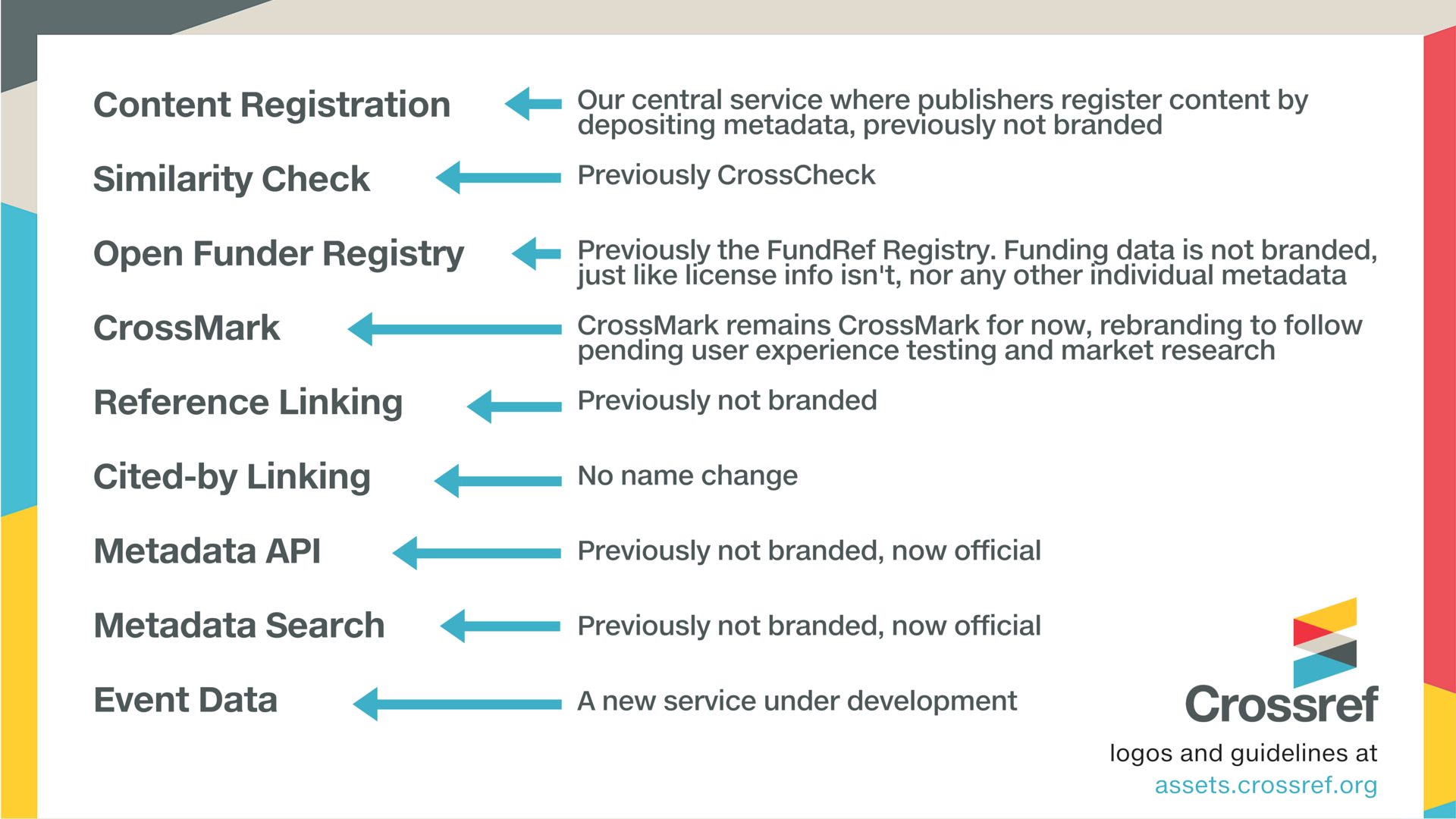
As our infrastructure and services expanded, we sometimes branded services with no reference to Crossref. As explained in our The Logo Has Landed post last November, this has led to confusion, and it was not scalable nor sustainable.
With a cohesive approach to naming and branding, the benefits of changing to (some) new names and logos should help everyone. Our aim is to stem confusion and be in a much better position to provide clear messages and useful resources so that people don’t have to try hard to understand what Crossref enables them to do.
So while it may be a bit of a pain short-term, it will be worth it!
What are the new names?
As a handy reference, here is a slide-shaped image giving an overview of our services with their new names:
Overview of brand name changes, April 2016
It’s a lowercase ‘r’ in Crossref
That’s right, you’ve spent fifteen years learning to capitalize the second R in Crossref, and now we’re asking you to lowercase it! Please say hello to and start to embrace the more natural and contemporary Crossref.
I’m hoping we can count on our community to update logos and names on your end, keeping consistent with new brand guidelines. And I hope we can make it as easy as possible to do:
This Content Delivery Network (CDN) at assets.crossref.org allows you to reference logos using a snippet of code. Please do not copy/download the logos.
We also have a new website in development which will put support and resources front and center of the user experience. More on that in the next month or two.
By using the snippets of code provided via our new CDN at assets.crossref.org, these kind of manual updates should never be a problem in the future if the logo changes again (no plans anytime soon!).
Of course, we don’t expect people to update new logos and names immediately, there is always a period of transition. Please let us know let us know if we can help you to update your sites and materials in the coming weeks.
Also, check out the launch video, which presents five key Crossref brand messages: