4 minute read.Using the Crossref Metadata API. Part 1 (with Authorea)
Did you know that we have a shiny, not so new, API kicking around? If you missed Geoffrey’s post in 2014 (or don’t want a Cyndi Lauper song stuck in your head all day), the short explanation is that the Crossref Metadata API exposes the information that publishers provide Crossref when they register their content with us. And it’s not just the bibliographic metadata either-funding and licensing information, full-text links (useful for text-mining), ORCID iDs and update information (via Crossmark)-are all available, if included in the publishers’ metadata.
Interested? This is the kickoff a series of case studies on the innovative and interesting things people are doing with the Metadata API. Welcome to Part 1.
What can you do with the Metadata API?
Build search interfaces. We’ve built some ourselves. Check out Crossref Metadata Search to search the metadata of over 80 million journal articles, books, standards, datasets & more. Or Crossref Funder Search to search nearly 15,000 funders and the 982,162 records we have that contain funding data.Provide cross-publisher support for text and data mining applications.Get really interesting top-level reports on the metadata Crossref holds - or look at subsets of the information you’re interested in.Third parties are free to build their own products and tools that build off of the Metadata API (below are some of the many examples that we will highlight in this series).Importantly, there’s no sign-up required to use the Metadata API - the data are facts from members, therefore not subject to copyright and free to use for whatever purpose anyone chooses.
To help, Scott Chamberlain of rOpenSci has built a set of robust libraries for accessing the Metadata API. These libraries are now available in the R, Python and Ruby languages. Scott’s blog post has some great information on those. For those using the libraries, there have been a few updates since Scott’s post - to serrano, and support for field queries has been added to habanero (coming to serrano and rCrossref soon). Any feedback/bug reports can be submitted via the GitHub repos serrano or habanero. There’s also a javascript library, authored by Robin Berjon.
Who’s using the Crossref Metadata API?
We get around 30 million requests a month. We’d like to share a few case studies to showcase what they’re doing and how they’re using it. Look out for a series of posts over the next few months where we’ll open the floor to those using the API and let them explain how and why.
We’ll let Authorea kick things off…
Alberto Pepe, co-founder of Authorea explains:
Authorea is a word processor for researchers and scholars. It is a collaboration platform to write, share and openly research in real-time: write manuscripts and include rich media, such as data sets, software, source code and videos. The media-rich, data-driven capabilities of Authorea make it the perfect platform to create and disseminate a new generation of research articles, which are natively web-based, open, and reproducible. Authorea is free to use.
How is the Crossref Metadata API used within Authorea?
Authorea is specifically made for scholarly documents such as research articles, conference papers, grey literature, class notes, student papers, and problem sets. What makes scholarly documents so peculiar are their citations and references, mathematical notation, tables, and data. For citations and references, we built a citation tool which allows authors to search and cite scholarly papers with ease, without having to leave the editor. While in the middle of writing a sentence, authors can click the “cite” button and a citation tool opens up:
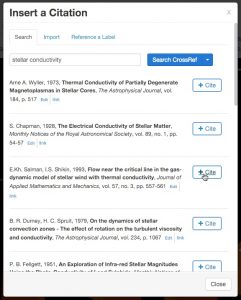
We currently use two engines for searching scholarly literature via their APIs: Crossref and Pubmed. Our authors love being able to search (by author name, paper title, topic, etc) and add references to their papers on the fly, in one click.
What are the future plans for Authorea?
Among the many plans we have for the future, there is one which is also tied to Crossref: we are going to let authors assign DOIs to Authorea articles such as blog posts, preprints, “data papers”, “software papers” and other kinds of grey literature which does not fit in the traditional scholarly journals.
What else would you like to see in our metadata?
Well, since you ask: we would love to see unique BibTex IDs being served by the Metadata API (right now, you create the ID automatically using author name and year). Also, in some cases, some important metadata fields are missing (even author or title). I think it is actually more important to fix existing metadata rather than add new fields!
Keen to share what you’re doing with the Crossref Metadata API? Contact feedback@crossref.org and share your story.