PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
In the scholarly communications environment, the evolution of a journal article can be traced by the relationships it has with its preprints. Those preprint–journal article relationships are an important component of the research nexus. Some of those relationships are provided by Crossref members (including publishers, universities, research groups, funders, etc.) when they deposit metadata with Crossref, but we know that a significant number of them are missing. To fill this gap, we developed a new automated strategy for discovering relationships between preprints and journal articles and applied it to all the preprints in the Crossref database. We made the resulting dataset, containing both publisher-asserted and automatically discovered relationships, publicly available for anyone to analyse.
TL;DR
We have developed a new, heuristic-based strategy for matching journal articles to their preprints. It achieved the following results on the evaluation dataset: precision 0.99, recall 0.95, F0.5 0.98. The code is available here.
We applied the strategy to all the preprints in the Crossref database. It discovered 627K preprint–journal article relationships.
We gathered all preprint–journal article relationships deposited by Crossref members, merged them with those discovered by the new strategy, and made everything available as a dataset. There are 642K relationships in the dataset, including:
296K provided by the publisher and discovered by the strategy,
331K new relationships discovered by the strategy only,
15K provided by the publisher only.
In the future, we plan to replace our current matching strategy with the new one and make all discovered relationships available through the Crossref REST API.
Introduction
Relationships between preprints and journal articles link different versions of research outputs and allow one to follow the evolution of a publication over time. The Crossref deposit schema allows Crossref members to provide these relationships for new publications, either as a has-preprint relationship deposited with a journal article, or an is-preprint-of relationship deposited with a preprint.
To assist members who deposit preprints, we also try to connect deposited journal articles with preprints. The current method looks for an exact match between the title and first authors. We send possible matches as suggestions to the preprint server, which decides whether to update the metadata with the relationship.
At the time of writing, 137,837 journal articles in the Crossref database have a has-preprint relationship1, and 562,225 works of type posted-content (preprints belong to this type) have an is-preprint-of relationship2.
We suspected that many preprint–journal article relationships are missing, as some members inevitably fail to deposit them, even after suggestions from the current matching strategy. Another factor is that the current strategy is fairly conservative, and probably misses a significant number of relationships. For these reasons, we decided to investigate whether we could improve on the current process. Doing so would allow us to infer missing relationships on a large scale, similar to how we automatically match bibliographic references to DOIs.
This preprint matching task can be defined in two directions:
We start with a journal article and we want to find all its preprints.
We start with a preprint and we want to find a subsequently published journal article.
On the one hand, matching from journal articles to preprints would allow us to enrich the database continually with new relationships, either periodically or every time new content is added. Since journal articles tend to appear in the database later than their preprints, it makes sense for a new journal article to trigger the matching and not the other way round. This way we can expect the potential matches to be already in the database at the time of matching.
On the other hand, matching from preprints to journal articles can be useful in a situation where we want to add relationships in an existing database retrospectively. In our case, the database contains many more journal articles than preprints, so for performance reasons it is better to start with preprints.
In both cases we are dealing with structured matching, meaning that we match a metadata record of a work (preprint or journal article), rather than unstructured text.
As a result of matching a single preprint or a single journal article, we should expect zero or more matched journal articles/preprints. Multiple matches occur when:
there are multiple versions of the matched preprint and/or
matched works have duplicates.
The image shows the result of matching a journal article to two versions of a preprint:
Matching strategy
Our matching strategy uses the following workflow:
Gathering a short list of candidates using the Crossref REST API.
Scoring the similarity between the input item and each candidate.
A final decision about which candidates, if any, should be returned as matches.
Gathering candidates is done using the Crossref REST API’s query.bibliographic parameter. The query is a concatenation of the title and authors’ last names of the input item. We filter the candidates based on their type, to leave only preprints or only journal articles, depending on the direction of the matching. In the future, instead of getting the candidates from the REST API, we will be using a dedicated search engine, optimised for preprint matching.
Scoring candidates is heuristic-based. Similarities between titles, authors, and years are scored independently, and the final score is their average. Titles are compared in a fuzzy way using the rapidfuzz library. Authors are compared pairwise using the ORCID ID, or first/last names if ORCID ID is not available. The similarity score between issued years is 1 if the article was published no earlier than one year before the preprint and no later than three years after the preprint, or 0 otherwise.
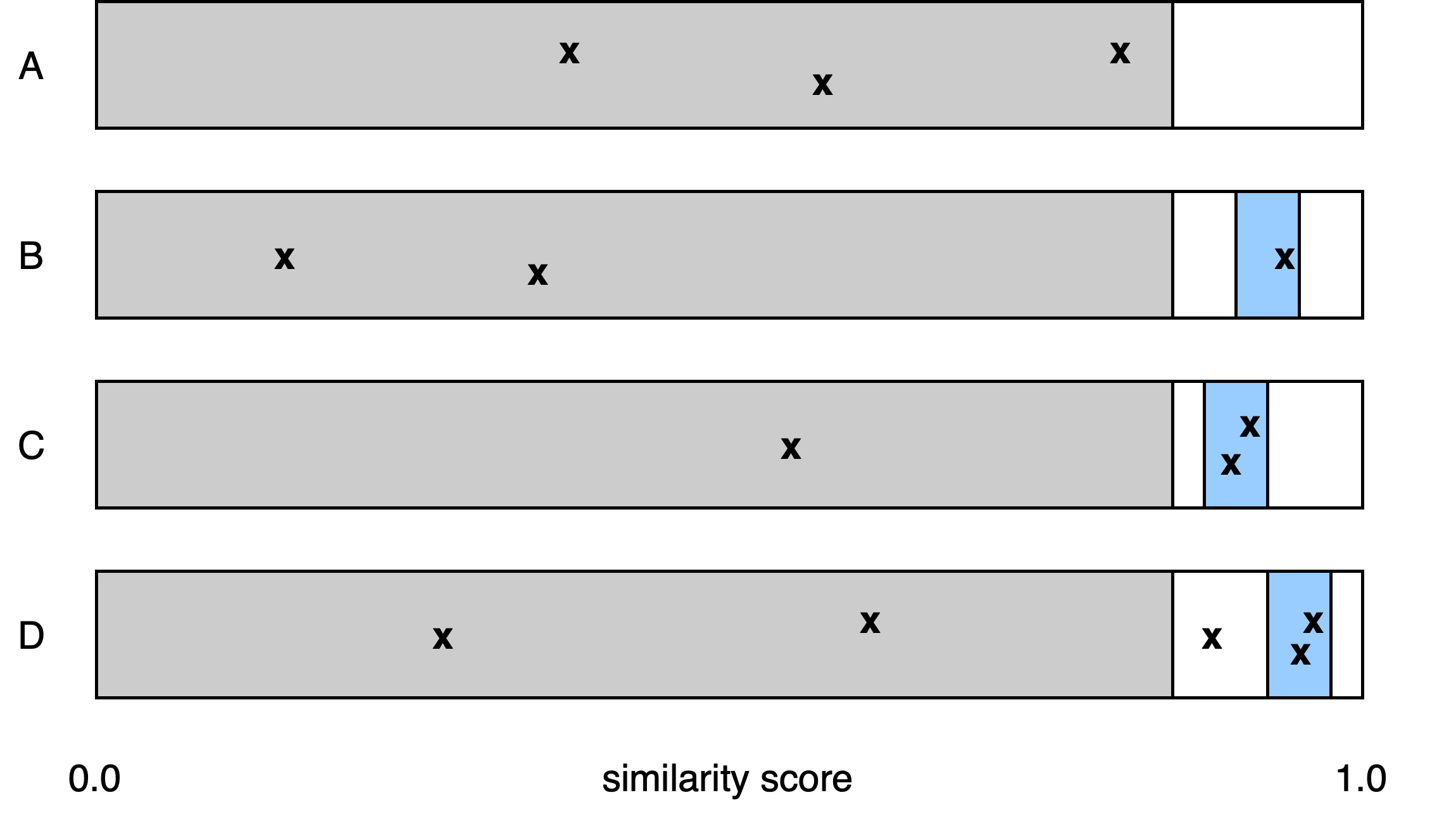
The final decision is made based on two parameters: minimum score and maximum score difference, both chosen based on a validation dataset. The following diagram depicts the results of applying these two parameters in all possible scenarios. First, any candidate scoring below the minimum score is rejected (grey area in the diagram). Second, the scores of the remaining candidates are compared with the score of the top candidate. If the score of a candidate is close enough to the score of the top candidate, it is returned as a match (blue area).
This process can result in the following scenarios:
Scenario A: there is no candidate above the minimum score. This means nothing matches sufficiently, so nothing is returned.
Scenario B: there is only one candidate above the minimum score. This means it is the best match and we don’t have much of a choice, so it is returned.
Scenario C: there are multiple candidates above the minimum score, and they all have similar scores. This means they all are similarly good matches, so all are returned.
Scenario D: there are multiple candidates above the minimum score, but their scores differ a lot. In this case, we don’t want to return all of them, but only those that are close to the top match. Intuitively, we don’t want to return less-than-great matches if we have really great ones. This is when the maximum score difference comes into play: we return the candidates with the “score distance” to the top candidate lower than the maximum score difference.
We evaluated this strategy on a test set sampled from the Crossref metadata records. The test set contains 3,000 pairs (journal article, set of corresponding preprints). Half of the journal articles have known preprints and the other half don’t. The test set can be accessed here.
We used precision, recall, and F0.5 as evaluation metrics:
Precision measures the fraction of the matched relationships that are correct.
Recall measures the fraction of the true relationships that were matched.
F0.5 combines precision and recall in a way that favours precision.
The strategy achieved the following results: precision 0.9921, recall 0.9474, F0.5 0.9828. The average processing time was 0.96s.
We have investigated other approaches to making decisions about which candidates to return as matches (step 3 above), including using machine learning. At present none have outperformed the heuristic approach described above. The heuristic method is also preferred because of its fast performance.
Preprint–journal article relationship dataset
We applied the strategy to the entire Crossref database:
We selected all preprints published until the end of August 2023. This included only works with type posted-content and subtype preprint, as reported by the REST API. There were 1,050,247 of them.
We ran the matching strategy (preprint -> journal article) on them. This resulted in 627,011 preprint–journal article relationships.
The resulting relationships were combined with the relationships deposited by the Crossref members. We included relationships of types has-preprint or is-preprint-of, where both sides of the relationship exist in our database, were published until the end of August 2023, and are of proper types and subtypes (type=journal-article for the journal article and type=posted-content, subtype=preprint for the preprint).
The resulting dataset is a single CSV file with the following fields:
preprint DOI (string)
journal article DOI (string)
whether the publisher of the journal article deposited this relationship (boolean)
whether the publisher of the preprint deposited this relationship (boolean)
the confidence score returned by the strategy (float, empty if the strategy did not discover this relationship)
The dataset contains:
641,950 relationships in total, including 580,532 preprints and 565,129 journal articles,
14,939 of them were deposited by the Crossref members, but not discovered by the strategy,
330,826 of them were discovered by the strategy, but not provided by any Crossref member,
296,185 of them were both deposited by a Crossref member and discovered by the strategy.
Overall, based on the number of existing and newly discovered preprint–journal article relationships, it seems that employing automated matching strategies would approximately double the number of these relationships in the Crossref database. In the future, we would like to match new journal articles on an ongoing basis. We also plan to make all discovered relationships available through the REST API.
In the meantime, we will be publishing the discovered relationships in the form of datasets, and we invite anyone interested to further analyse this data. And if you find out something interesting about preprints and their relationships, do let us know!