6 minute read.DOIs and Linked Data: Some Concrete Proposals
Since last month’s threads (here, here, here and here) talking about the issues involved in making the DOI a first-class identifier for linked data applications, I’ve had the chance to actually sit down with some of the thread’s participants (Tony Hammond, Leigh Dodds, Norman Paskin) and we’ve been able sketch-out some possible scenarios for migrating the DOI into a linked data world.
I think that several of us were struck by how little actually needs to be done in order to fully address virtually all of the concerns that the linked data community has expressed about DOIs. Not only that- but in some of these scenarios we would put ourselves in a position to be able to semantically-enable over 40 million DOIs with what amounts to the flick of a switch.
Given the huge interest in linked data on the part of researchers and Crossref members- it seems like it would be a fantastic boon to both the IDF (International DOI Foundation) and Crossref if we were able to do something quickly here.
Anyway- The following are notes outlining several concrete proposals for addressing the limitations of DOIs as identifiers in linked data applications. They range in complexity/effort involved- with the simplest scenario providing minimal (yet functional) LD capabilities for just one RA’s members (Crossref’s) and the most complex providing per-RA and per-RA-member configurability on how DOIs would behave for LD applications.
We’d appreciate comments, questions, suggestions, corrections, etc.
A: Simplest Scenario
What would need to be done?
- Crossref implements a linked data service. For example, hosted at rdf.crossref.org.
- Crossref recommends that any member publisher who wants to add rudimentary linked data capabilities to their site could simply insert some simple link elements into their landing Pages. So, for instance, for the article with the DOI 10.5555/1234567 in the Journal of Psychoceramics, the publisher would put the following in the landing page for the article:
<link rel="primarytopic" href="http://doi.crossref.org/10.5555/1234567" />
<link rel="alternate" type="application/rdf+xml" href="http://rdf.crossref.org/metadata/10.5555/1234567.rdf" title="RDF/XML version of this document"/>
<link rel="alternate" type="text/html" href="http://www.journalofpsychoceramics.org/10.5555/1234567.html" title="HTML version of this document"/> <link rel="alternate" type="application/json" href="http://rdf.crossref.org/metadata/10.5555/1234567.json" title="RDF/JSON version of this document"/>
<link rel="alternate" type="text/turtle" href="http://rdf.crossref.org/metadata/10.5555/1234567.ttl" title="Turtle version of this document"/>
In the above snippet the HTML version of the document is the publisher’s existing landing page.
How it would work
- A sem-web-enabled browser would query dx.doi.org/10.5555/1234567 and get a normal 302 redirect to the publisher’s landing page.
- The sem-web-enabled browser would sniff the page for the link elements and retrieve the representations it wanted from rdf.crossref.org
- The returned document would contain an appropriate representation of the metadata that the publisher has deposited with Crossref. It would also assert that:
doi.crossref.org/10.5555/12334567 owl:sameAs dx.doi.org/10.5555/1234567 .
dx.doi.org/10.5555/12334567 owl:sameAs info:doi/10.5555/12334567</p> info:doi/10.5555/12334567 owl:sameAs doi:10.5555/1234567
Alternatively, the publisher could implement their own linked data support on their own domain using whatever appropriate method they want. So, for instance, a larger publisher could support content negotiation at their site and return different/enhanced metadata, etc.
Pros
- Doesn’t require changes at DOI/Handle levels
- Is easy for publisher to opt-in or opt-out
- Requires minimal development on the part of Crossref.
Cons
- Only applies to Crossref DOIs.
- It depends on publishers taking action. Might be a long time before publishers add the needed links to their landing pages or support content negotiation.
- DOI system is still not strictly LD compliant (e.g. it is returning 302 redirects. Naive sem-web browsers might ‘stop’ after getting a 302. Should ideally use 303s, content negotiation, etc.)
- Doesn’t work for DOIs that currently bypass landing pages and which go directly to content.
B: Simple + IDF Global Semantic Compliance
What would need to be done?
- Same as “Simplest Scenario”
- IDF globally changes dx.doi.org to return 303 redirect
How would it work?
Same as Simplest Scenario, except that, because sem-web-enabled browser had been told it was being redirected to a NIR (via the 303), it would presumably be more likely to continue.
Pros
- All DOIs conform to expectations for LD identifiers
- Easy for publisher to opt-in or opt-out
- Requires minimal development on part of Crossref
- Requires minimal work (?) on part of IDF
Cons
- Requires global change on part of IDF. Global change might conflict with requirements of other RAs.
- It depends on publishers taking action. Might be a long time before publishers add needed links to their landing pages or support content negotiation.
- Doesn’t work for DOIs that currently bypass landing pages (e.g. OECD spreadhseets, UICR datasets, etc.)
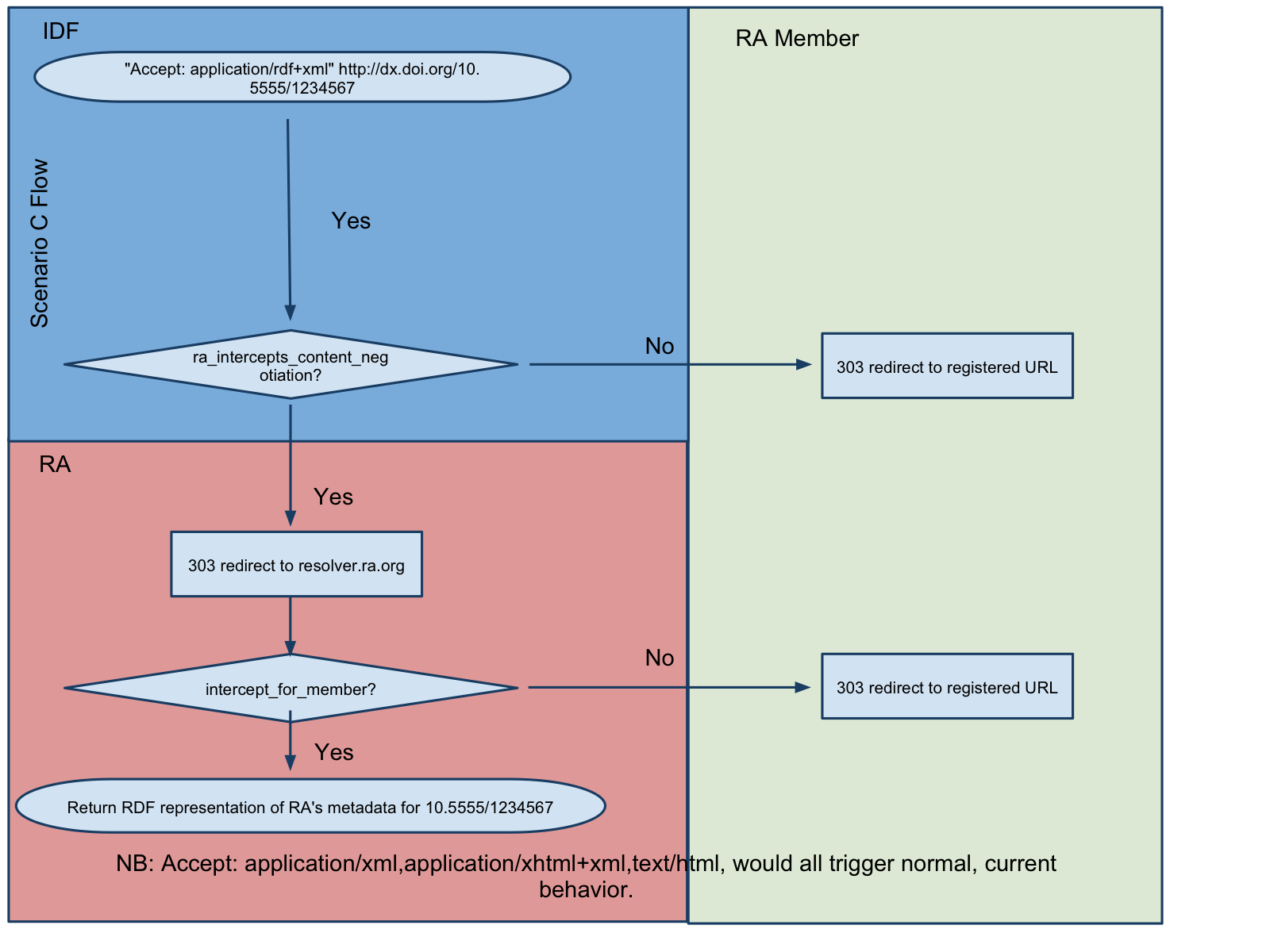
C: Simple + IDF Global Semantic Compliance + RA CN Intercept
What would need to be done?
Same as “B: Simple + IDF Global Semantic Compliance” Scenario
IDF changes dx.doi.org to redirect content-negotiated dx.doi.org queries to RA-controlled resolver depending on the preferences of the RA.
RA implements DOI resolver (e.g. dx.crossref.org) that supports content negotiation. RA allows its members to specify to the RA that they want either: <ol type=a>
RA to forward all requests to the member’s site.
RA to “intercept” content-negotiations for non-HTML representations and direct them appropriately (e.g. return appropriate representation from rdf.crossref.org)
How would it work?
Pros
- All DOIs conform to expectations for LD identifiers
- Allows RA to potentially LD-enable its members very quickly.
- Easy for ra-members to opt-in or opt-out
- Requires minimal development on part of Crossref
- Would even work for DOIs that bypass landing pages
Cons
- Requires global change on part of IDF. Global change might conflict with requirements of other RAs.
- Requires change to add decision logic implementation on part of IDF.
- Requires development of RA resolvers that implement per-member resolution logic (note- this would probably actually be done at DOI level)
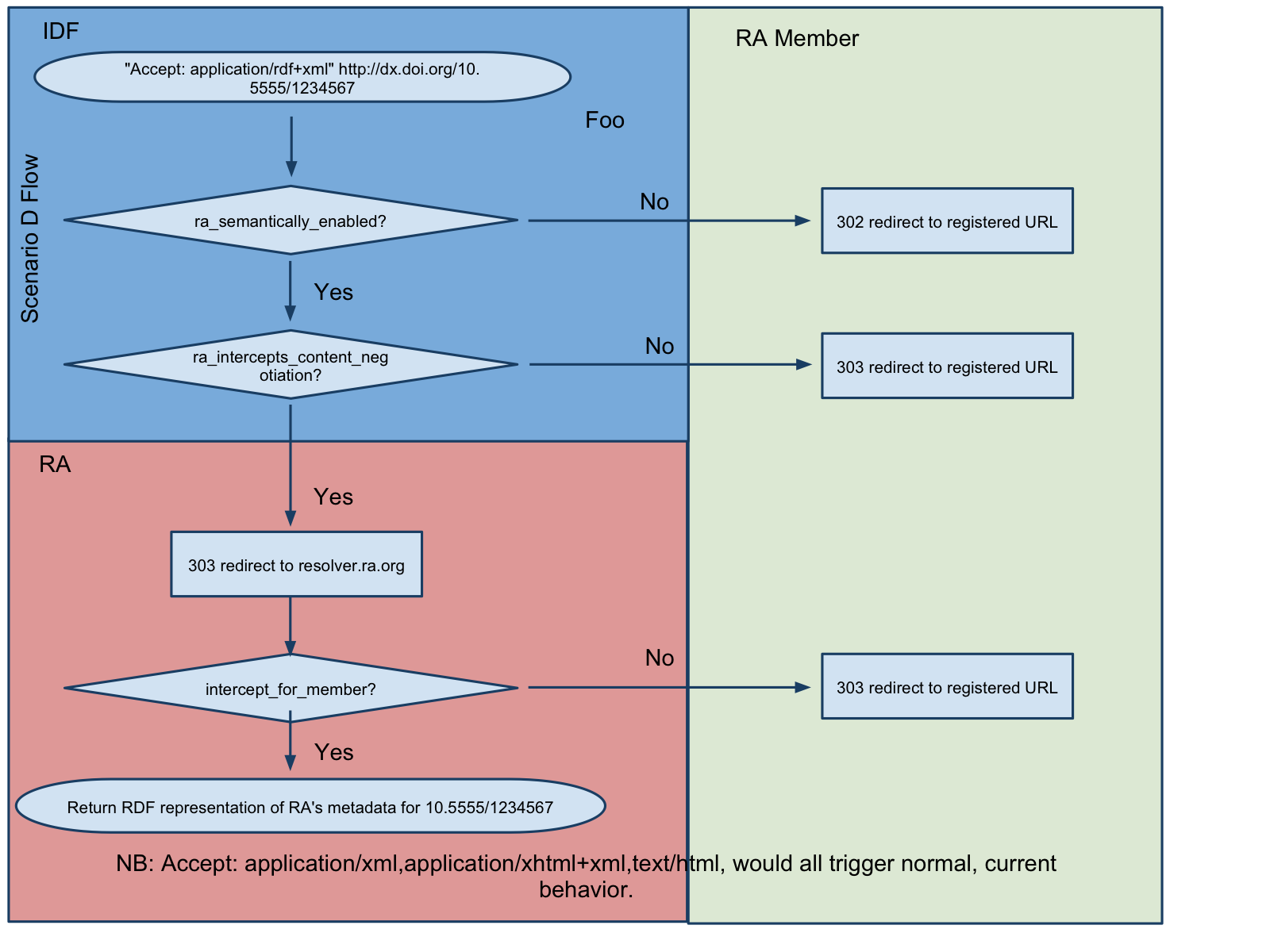
D: Simple + IDF Selective Semantic Compliance + RA CN Intercept
What would need to be done?
Same as Simplest Scenario
IDF changes dx.doi.org to return either 302 or 303 redirect depending on the preferences of the RA.
IDF changes dx.doi.org to redirect content-negotiated dx.doi.org queries to RA-controlled resolver depending on the preferences of the RA.
RA implements DOI resolver (e.g. dx.crossref.org) that supports content negotiation. RA allows its members to specify to the RA that they want either:
RA to forward all requests to the member’s site.
RA to “intercept” content-negotiations for non-HTML representations and direct them appropriately (e.g. return appropriate representation from rdf.crossref.org)
How would it work?
Pros
- Allows RA to potentially LD-enable its members very quickly.
- Easy for ra-members to opt-in or opt-out
- Requires minimal development on part of Crossref
- Would even work for DOIs that bypass landing pages
Cons
- Only some DOIs conform to expectations for LD identifiers
- Requires change to add decision logic implementation on part of IDF.
- Requires development of RA resolvers that implement per-member resolution logic (note- this would probably actually be done at DOI level)




