4 minute read.DOIs in Reddit
Skimming the headlines on Hacker News yesterday morning, I noticed something exciting. A dump of all the submissions to Reddit since 2006. “How many of those are DOIs?”, I thought. Reddit is a very broad community, but has some very interesting parts, including some great science communication. How much are DOIs used in Reddit?
(There has since been a discussion about this blog post on Hacker News)
We have a whole strategy for DOI Event Tracking, but nothing beats a quick hack or is more irresistible than a data dump.
What is a DOI?
If you know what a DOI is, skip this! The DOI system (Digital Object Identifier) is a link redirection service. When a publisher puts some content online they could just hand out the URL. But the URL can change, and within a very short space of time, link-rot happens. DOIs are designed to fight link rot. When a publisher mints a DOI to an article they just published, they can change the article’s URL and then update the DOI to point to the new place. DOIs are persistent. They are URLs. They’re also identifiers (kind of like ISBNs), and they’re used in scholarly publishing as to do citations.
Crossref is the DOI registration agency for scholarly publishing. That means mostly things like journal articles. There are other registration agencies, for example, DataCite, who do DOIs for research datasets. But at this point in time, most DOIs are Crossref’s.
What does finding DOIs in Reddit mean?
It means someone used a DOI to cite something! DOIs can be used for any kind of content, but because of the sheer volume of scientific publishing, lots of DOIs are for science. Having a DOI doesn’t say anything about quality or content. But it does indicate that the person who created the DOI probably intended it to be cited. We care because it means that every time a DOI is used a tiny bit of link-rot doesn’t have the opportunity to take hold. Every time something is discussed on Reddit and the DOI is used, it means that archaeologists using the data dump in 100 years will have identifiers to find the things being discussed, even if the web and URLs have long since crumbled to dust.
Or, more likely, in five year’s time when a few URLs will have shuffled around.
The results
DOIs have been used on Reddit since 2008 (the logs start in 2006). After a rocky start, we see hundreds being used per year.
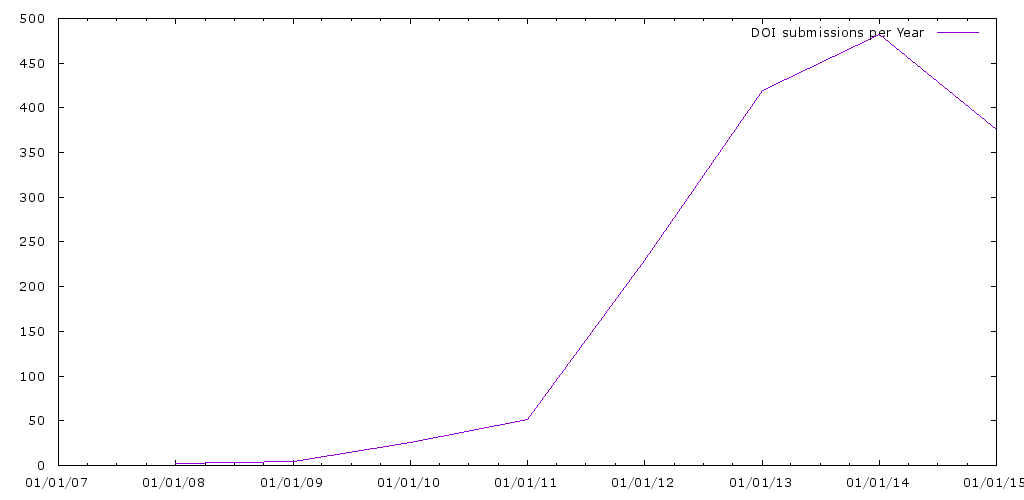
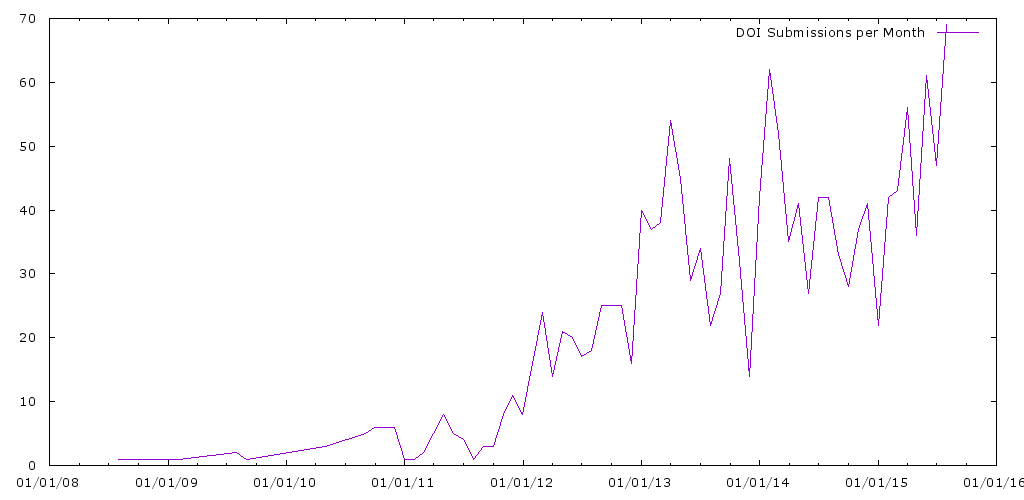
That’s dozens per month.
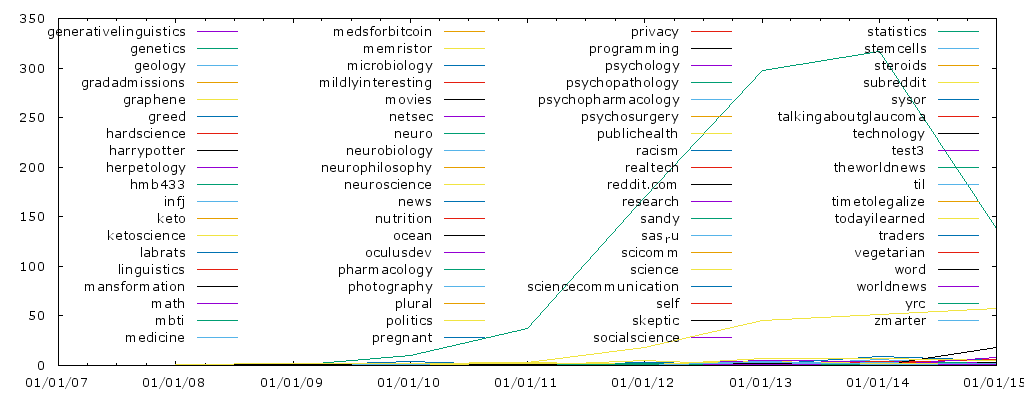
The best subreddit to find DOIs is /r/Scholar, followed by /r/science. And then a lot of others with one or two per year.
Opportunities
It’s great to see DOIs being used in Reddit. But let’s be honest, it’s not a massive amount.
We have a list of domains that our DOIs point to. They mostly belong to publishers, so every time we see a link to a domain on the list, there’s a chance (not a certainty) that the link could have been made using a DOI. We found a large number of these, orders of magnitude more than DOIs. We’re still crunching the data.
The data
The data is quite large. It’s a 40 Gigabyte download compressed, which comes to about 170 GB that uncompressed. It contains the submissions to reddit between 2006 and 2015, not the comments, so each data point represents a thread of conversation about a DOI.
Reproducibility (updated)
You can find the source code and reproduce the figures at http://github.com/crossref/reddit-dump-experiment. We use Apache Spark for this kind of thing.
The data and methodology are very experimental. You can download all results here:
https://s3-eu-west-1.amazonaws.com/crossref-labs-data/2015-10-06/reddit-dump-experiment.zip
It includes all data for charts in this post, as well as the full list of DOIs, the full list of URLs that could possibly have DOIs, and the full JSON input line for each of these.
More info
Read about our DOI Event Tracking strategy, including our live stream of Wikipedia citations.




