PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
The following two DOIs point to the same article- the first DOI points to the final author version, and the second DOI points to the final published version:
This DOI appears to have been published, but was not registered until well after it was published. There were 254 unsuccessful attempts to resolve it in September 2012 alone:
The owner of prefix, ‘10.4223,’ who is responsible for the above DOI had 378,790 attempted resolutions in September 2012 of which there were 377,001 failures. The top 10 DOI failures for this prefix each garnered over 200 attempted resolutions. As of November 2012 the prefix had only registered 349 DOIs.
Of the above 16 example DOIs 11 cannot be used for CrossCheck or Crossmark. 3 cannot be used with content negotiation. To search metadata for the above examples, you need to visit four sites:
The 14 examples come from just 4 of the 8 existing DOI registration agencies (RAs) It is virtually impossible for somebody without specialized knowledge to tell which DOIs are Crossref DOIs and which ones are not.
Background
So DOIs unambiguously and persistently identify published, trustworthy, citable online scholarly literature. Right? Wrong.
The examples above are useful because they help elucidate some misconceptions about the DOI itself, the nature of the DOI registration agencies and, in particular issues being raised by new RAs and new DOI allocation models.
DOIs are just identifiers
Crossref’s dominance as the primary DOI registration agency makes it easy to assume Crossref’s particular application of the DOI as a scholarly citation identifier is somehow intrinsic to the DOI. The truth is, the DOI has nothing specifically to do with citation or scholarly publishing. It is simply an identifier that can be used for virtually any application. DOIs could be used as serial numbers on car parts, as supply-chain management identifiers for videos and music or as cataloguing numbers for museum artifacts. The first two identifiers listed in the examples (a & b) illustrate this. They both belong to MovieLabs and are part of the EIDR (Entertainment Identifier Registry) effort to create a unique identifier for television and movie assets. At the moment, the DOIs that MoveLabs are assigning are B2B-focused and users are unlikely to see them in the wild. But we should recall that Crossref’s application of DOIs was also initially considered a B2B identifier- but it has since become widely recognized and depended on by researchers, librarians and third parties. The visibility of EIDR DOIs could change rapidly as they become more popular.
Multiple DOIs can be assigned to the same object
There is no International DOI Foundation (IDF) prohibition against assigning multiple DOIs to the same object. At most the IDF suggests that RAs might coordinate to avoid duplicate assignments, but it provides no guidelines on how such cross-RA checks would work.
Crossref, in its particular application of the DOI, attempts to ensure that we don’t assign two different copies of the same article with different DOIs, but that is designed in order to avoid having publishers mistakenly making duplicate submissions. Even then, there are subtle exceptions to this rule- the same article, if legitimately published in two different issues (e.g. a regular issue and a thematic issue) will be assigned different DOIs. This is because, though the actual article content might be identical, the context in which it is cited is also important to record and distinguish. Finally, of course, we assign multiple DOIs to the same “object” when we assign book-level and chapter level DOIs. Or when we assign DOIs to components or reference work entries.
The likelihood of multiple DOIs being assigned to the same object increases as we have multiple RAs. In the future we might legitimately have a monograph that has different Bowker DOIs for different e-book platforms (Kindle, iPad, Kobo.) yet all three might share the same Crossref DOI for citation purposes.
Again, the examples show this already happening. The examples f & g are assigned by DataCite (via FigShare) and Crossref respectively. The first identifies the author version and was presumably assigned by said author. The second identifies the publisher version and was assigned by the publisher.
Although Crossref, as a publisher-focused RA, might have historically proscribed the assignment of Crossref DOIs to archive or author versions, there has never been and could never be any such restrictions on other DOI RAs. These are legitimate applications of two citation identifiers to two versions of the same article.
However, the next set of examples, h, i, j and k show what appears to be a slightly different problem. In these cases articles that appear to be in all aspects identical have been assigned two separate DOIs by different RAs. In one respect this is a logistical or technical problem- although Crossref can check for such potential duplicate assignments within its own system, there is no way for us to do this across different RAs. But this is also a marketing and education problem- how do RAs with similar constituencies (publishers, researchers, librarians) and application of the DOI (scholarly citation) educate and inform their members about best practice in applying DOIs in that particular RAs context?
DOI registration agencies are not focused on record types, they are focused on constituencies and applications
The examples f through k also illustrate another area of fuzzy thinking about RAs- that they are somehow built around particular record types. We routinely hear people mistakenly explain that difference between Crossref and DataCite is that “Crossref assigns DOIs to journal articles” and that “DataCite assigns DOIs to data.” Sometimes this is supplemented with “and Bowker assigns DOIs to books.” This is nonsense. Crossref assigns DOIs to data (example o) as well as conference proceedings, programs, images, tables, books, chapters, reference entries, etc. And DataCite covers a similar breadth of record types including articles (examples c, h, f, l, m ). The difference between Crossref, DataCite and Bowker is their constituencies and applications- not the record types they apply DOIs to. Crossref’s constituency is publishers. DataCite’s constituency is data repositories, archives and national libraries. But even though Crossref and DataCite have different constituencies, they share a similar application of the DOI- that is the use of DOI as citation identifiers. This is in contrast to MovieLabs whose application of the DOI is supply chain management.
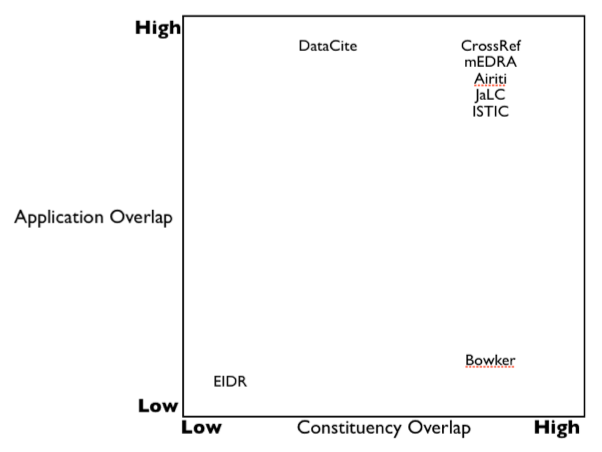
DOI registration agency constituencies and applications can overlap or be entirely separate
Although Crossref’s constituency is “publishers”, we are catholic in our definition of “publisher” and have several members who run repositories that also “publish” content such as working papers and other grey literature (e.g. Woods Hole Oceanographic Institution, University of Michigan Library, University of Illinois Library). DataCite’s constituency is data repositories, archives and national libraries, but this doesn’t stop DataCite (through CDL/FigShare) from working with the publisher, PLoS, on their “Reproducibility Initiative” which requires the archiving of article-related datasets. PloS has announced that they will host all supplemental data sets on FigShare but will assign DOIs to those items through Crossref.
Crossref’s constituency of publishers overlaps heavily with Airiti, JaLC, mEDRA, ISTIC and Bowker. In the case of all but Bowker we also overlap in our application of the DOI in the service of citation identification. Bowker, though it shares Crossref’s constituency, uses DOIs for supply chain management applications.
Meanwhile, EIDR is an outlier, its constituency does not overlap with Crossref’s and its application of the DOI is different as well.
The relationship between RA constituency overlap (e.g. scholarly publishers vs television/movie studios) and application overlap (e.g. citation identification vs. supply chain management) can be visualized as such:
The differences (subtle or large) between the various RAs are not evident to anybody without a fairly sophisticated understanding of the identifier space and the constituencies represented by the various RAs. To the ordinary person these are all just DOIs, which in turn are described as simply being “persistent interoperable identifiers.”
Which of course begs the question, what do we mean by “persistent” and “interoperable?”
DOIs only are as persistent as the registration agency’s application warrants.
The word “persistent” does not mean “permanent.” Andrew Treloar is known to point out that the primary sense of the word “persistent” in the New Oxford American Dictionary is:
Continuing firmly or obstinately in a course of action in spite of difficulty or opposition
Yet presumably the IDF once chose to use the word “persistent” instead of “perpetual” or “permanent” for other reasons. “Persistence” implies longevity, without committing to “forever.”
It may sound prissy, but it seems reasonable to expect that the useful life-expectancy for the identifier used for managing inventory of the the movie “Young Sex Crazed Nurses” might be different than the life expectancy for the identifier used to cite Henry Oldenburg’s “Epistle Dedicatory” in the first issue of the Philosophical Transactions. In other words, some RAs have a mandate to be more “obstinate” than others and so their definitions of “persistence” may vary. Different RAs have different service level agreements.
The problem is that ordinary users of the “persistent” DOI have no way of distinguishing between those DOIs that are expected to have a useful life of 5 years and those DOIs that are expected to have a useful lifespan of 300+ years. Unfortunately, if one of the more than 6 million non-Crossref DOIs breaks today, it will likely be blamed on Crossref.
Similarly, if a DOI doesn’t work with an existing Crossref service, like CrossCheck, Crossmark or Crossref Metadata Search, it will also be laid at the foot of Crossref. This scenario is likely to become even more complex as different RAs provide different specialized services for their constituencies.
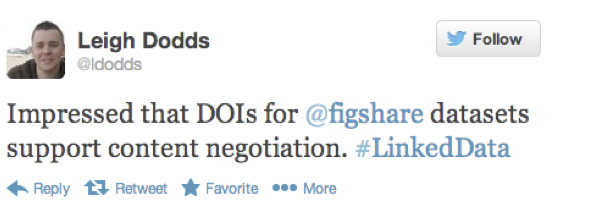
Ironically, the converse doesn’t always apply. Crossref oftentimes does not get credit for services that we instigated at the IDF level. For instance, FigShare has been widely praised for implementing content negotiation for DOIs even though this initiative had nothing to do with FigShare, instead it was implemented by DataCite with the prodding and active help of Crossref (DataCite even used Crossref’s code for a while). To be clear, we don’t begrudge praise for FigShare. We think FigShare is very cool- this just serves as an example of the confusion that is already occurring.
DOIs are only “interoperable” at a least common denominator level of functionality
There is no question that use of Crossref DOIs has enabled the interoperability of citations across scholarly publisher sites. The extra level of indirection built into the DOI means that publishers do not have to worry about negotiating multiple bilateral linking agreements and proprietary APIs. Furthermore, at the mundane technical level of following HTTP links, publishers also don’t have to worry about whether the DOI was registered with mEDRA, DataCite or Crossref as long as the DOI in question was applied with citation linking in mind.
However, what happens if somebody wants to use metadata to search for a particular DOI? What happens if they expect that DOI to work with content negotiation or to enable a CrossCheck analysis or show a Crossmark dialog or carry FundRef data? At this level, the purported interoperability of the DOI system falls apart. A publisher issuing DataCite DOIs cannot use CrossCheck. A user with a mEDRA DOI cannot use it with content negotiation. Somebody searching Crossref Metadata Search or using Crossref’s OpenURL API will not find DataCite records. Somebody depositing metadata in an RA other than Crossref or DataCite will not be able to deposit ORCIDs.
There are no easy or cheap technical solutions to fix this level of incompatibility baring the creation of a superset of all RA functionality at the IDF level. But even if we had a technical solution to this problem- it isn’t clear that such a high-level of interoperability is warranted across all RAs. The degree of interoperability that is desirable between RAs is only in proportion to the degree that they serve overlapping constituencies (e.g. publishers) or use the DOI for overlapping applications (e.g. citation)
DOI Interoperability matters more for some registration agencies than others
This raises the question of what it even means to be “interoperable” between different RAs that share virtually no overlap in constituencies or applications. In what meaningful sense do you make a DOI used for inventory control “interoperable” with a DOI used for identifying citable scholarly works? Do we want to be able to check “Young Sex Crazed Nurses” for plagiarism? Or let somebody know when the South Park movie has been retracted or updated? Do we need to alert somebody when their inventory of citations falls below a certain threshold? Or let them know how many copies of a PDF are left in the warehouse?
The opposite, but equally vexing issue arrises for RAs that actually share constituencies and/or applications. Crossref, DataCIte and mEDRA have all built separate metadata search capabilities, separate deposit APIs, separate OpenURL APIs, and separate stats packages- all geared at handling scholarly citation linking.
Finally, it seems a shame that a third party, like ORCID, who wants to enable researchers to add any DOI and its associated metadata to their ORCID profile, will end up having to interface with 4-5 different RAs.
Summary and closing thoughts
Crossref was founded by publishers who were prescient in understanding that, as scholarly content moved online, there was the potential to add great value to publications by directly linking citations to the documents cited. However, publishers also realized that many of the architectural attributes that made the WWW so successful (decentralization, simple protocols for markup, linking and display, etc.), also made the web a fragile platform for persistent citation.
The Crossref solution to this dilemma was to introduce the use of the DOI identifier as a level of citation indirection in order to layer a persist-able citation infrastructure onto the web. The success of this mechanism has been evident at a number of levels. A first-order effect of the system is that it has allowed publishers to create reliable and persistent links between copies of publisher content. Indeed uptake of the Crossref system by scholarly and professional publishers has been rapid and almost all serious scholarly publishers are now Crossref members.
The second order effects of the Crossref system have also been remarkable. Firstly, just as researchers have long expected that any serious paper-based publication would include citations, now researchers expect that serious online scholarly publications will also support robust online citation linking. Secondly, some have adopted a cargo-cult practice of seeing the mere presence of a DOI on a publication as a putative sign of “citability” or “authority.” Thirdly, interest in use of the DOI as a linking mechanism has started to filter out to researchers themselves, thus potentially extending the use of Crossref DOIs beyond being primarily a B2B citation convention.
The irony is that although the DOI system was almost single-handedly popularized and promoted by Crossref, the DOI brand is better known than Crossref itself. We now find that new RAs like EIDR, DataCite and new services like FigShare are building on the DOI brand and taking it in new directions. As such the first and second order benefits of Crossref’s pioneering work with DOIs are likely to be effected by the increasing activity of the new DOI RAs as well as the introduction of new models for assigning and maintaining DOIs.
How can you trust that a DOI is persistent if different RAs have different conceptions of persistence? How can you expect the presence of a DOI to indicate “authority” or “scholarliness” if DOIs are being assigned to porn movies? How can you expect a DOI to point to the “published” version of an article when authors can upload and assign DOIs to their own copies of articles?
It is precisely because we think that some of the qualities traditionally (and wrongly) accorded to DOIs (e.g. scholarly, published, stewarded, citable, persistent) are going to be diluted in the long term that we have focused so much of our recent attention on new initiatives that have a more direct and unambiguous connection to assessing the trustworthiness of Crossref member’s content. CrossCheck and the CrossCheck logos are designed to highlight the role that publishers play in detecting and preventing academic fraud. The Crossmark identification service will serve as a signal to researchers that publishers are committed to maintaining their scholarly content as well as giving scholars the information they need to verify that they are using the most recent and reliable versions of a document. FundRef is designed to make the funding sources for research and articles transparent and easily accessible. And finally we have been both adjusting Crossref’s branding and display guidelines as well as working with the IDF to refine its branding and display guidelines so as to help clearly differentiate different DOI applications and constituencies.
Whilst it might be worrying to some that DOIs are being applied in ways that Crossref has not expected and may not have historically endorsed, we should celebrate that the broader scholarly community is finally recognizing the importance of persist-able citation identifiers.
These developments also serve to reinforce a strong trend that we have encountered in several guises before. That is, the complete scholarly citation record is made up of more than citations to the formally published literature. Our work on ORCID underscored that researchers, funding agencies, institutions and publishers are interested in developing a more holistic view of the manifold contributions that are integral to research. The “C” in ORCID stands for “contributor” and ORCID profiles are designed to ultimately allow researchers to record “products” which include not only formal publications, but also data sets, patents, software, web pages and other research outputs. Similarly, Crossref’s analysis of the Cited-by references revealed that one in fifteen references in the scholarly literature published in 2012 included a plain, ordinary HTTP URI- clear evidence that researchers need to be able to cite informally published content on the web. If the trend in Cited-by data continues, then in two to three years one in ten citations will be of informally published literature.
The developments that we are seeing are a response to the need that users have to persistently identify and cite the full gamut of record types that make up the scholarly literature. If we can not persistently site these record types, the scholarly citation record will grow increasingly porous and structurally unsound. We can either stand back and let these gaps be filled by other players under their terms and deal reactively with the confusion that is likely to ensue- or we can start working in these areas too and help to make sure that what gets developed interacts with the existing online scholarly citation record in a responsible way.