Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
Detective Matcher stopped abruptly behind the corner of a short building, praying that his loud heartbeat doesn’t give up his presence. This missing DOI case was unlike any other before, keeping him awake for many seconds already. It took a great effort and a good amount of help from his clever assistant Fuzzy Comparison to make sense of the sparse clues provided by Miss Unstructured Reference, an elegant young lady with a shy smile, who begged him to take up this case at any cost.
The final confrontation was about to happen, the detective could feel it, and his intuition rarely misled him in the past. He was observing DOI 10.2307/257306, which matched Miss Reference’s description very well. So far, there was no indication that DOI had any idea he was being observed. He was leaning on a wall across the street in a seemingly nonchalant way, just about to put out his cigarette. Empty dark streets and slowly falling snow together created an excellent opportunity to capture the fugitive.
Suddenly, Matcher heard a faint rustling sound. Out of nowhere, another shady figure, looking very much like 10.5465/amr.1982.4285592, appeared in front of the detective, crossed the street and started running away. Matcher couldn’t believe his eyes. These two DOIs had identical authors, year and title. They were even wearing identical volume and issue! He quickly noticed minor differences: slight alteration in the journal title and lack of the second page number in one of the DOIs, but this was likely just a random mutation. How could have he missed the other DOI? And more importantly, which of them was the one worried Miss Reference simply couldn’t live without?
TL;DR
Crossref metadata contains duplicates, i.e. items with different DOIs and identical (or almost identical) bibliographic metadata. This often happens when there is more than one DOI pointing to the same object. In some cases, but not all of them, one of the DOIs is explicitly marked as an alias of the other DOI.
In this blog post, I analyze those duplicates, that are not marked with an alias relation. The analysis shows that the problem exists, but is not big.
Among 524,496 DOIs tested in the analysis, 4,240 (0.8%) were flagged as having non-aliased duplicates. I divided those duplicates into two categories:
Self-duplicate is a duplicate deposited by the same member as the other DOI, there were 3,603 (85%) of them.
Other-duplicate is a duplicate deposited by a different member than the other DOI’s depositor, there were only 637 (15%) of them.
I used three member-level metrics to estimate the volume of duplicates deposited by a given member:
Self-duplicate index is the fraction of self-duplicates in member’s DOIs: on average 0.67%.
Other-duplicate index is the fraction of other-duplicates in a member’s DOIs: on average 0.13%.
Global other-duplicate index is the fraction of globally detected other-duplicates involving a given member: on average 0.34%.
Introduction
In an ideal world, the relationship between research outputs and DOIs is one-to-one: every research output has exactly one DOI assigned and each DOI points to exactly one research output.
As we all know too well, we do not live in a perfect world, and this one-to-one relationship is also sometimes violated. One way to violate it is to assign more than one DOI to the same object. This can cause problems.
First of all, if there are two DOIs referring to the same object, eventually they both might end up in different systems and datasets. As a result, merging data between data sources becomes an issue, because we no longer can rely on comparing the DOI strings only.
Reference matching algorithms will also be confused when they encounter more than one DOI matching the input reference. They might end up assigning one DOI from the matching ones at random, or not assigning any DOI at all.
And finally, more than one DOI assigned to one object is hugely problematic for document-level metrics such as citation counts, and eventually affects h-indexes and impact factors. In practice, metrics are typically calculated per DOI, so when there are two DOIs pointing to one document, the citation count might be split between them, effectively lowering the count, and making every academic author’s biggest nightmare come true.
It seems we shouldn’t simply cover our eyes and pretend this problem does not exist. So what are we doing at Crossref to make the situation better?
It is possible for our members to explicitly mark a DOI as an alias of another DOI, if it was deposited by mistake. This does not remove the problem, but at least allows metadata consumers to access and use this information.
Whenever a DOI is registered or updated in Crossref, we automatically compare its metadata to the metadata of existing DOIs. If the metadata is too similar to the metadata of another DOI, this information is sent to the member and they have a chance to modify the metadata as they see fit.
Despite these efforts, we still see duplicates that are not explained by anything in the metadata. In this blog post, I will try to understand this problem better and assess how big it is. I also define three member-level metrics that can show how much a given member contributes to duplicates in the system and can flag members with unusually high fractions of duplicates.
Gathering the data
The data for this analysis was collected in the following way:
Only journal articles were considered in the analysis.
Only members with at least 5,000 journal article DOIs were considered in the analysis.
For each member, a random sample of 1,000 journal article DOIs was selected.
DOIs with no title, title shorter than 20 characters or shorter than 3 words were removed from each sample. This was done because items with short titles typically result in incorrectly flagged duplicates (false positives).
For each remaining DOI in the sample, a simple string representation was generated. This representation is a concatenation of the following fields: authors, title, container-title, volume, issue, page, published date.
This string representation was used as query.bibliographic in Crossref’s REST API and the resulting item list was examined.
If the original DOI came back as the first or the second hit, the relevance score difference between the first two hits is less than 1, they are both journal articles, and there is no relation (alias or otherwise) between them, the other one of the two is considered a duplicate of the original DOI. The score difference threshold was chosen through a manual examination of a number of cases. Most detected duplicates came back scored identically.
Overall results
In total, I tested 590 members and 524,496 DOIs. Among them, 4,240 DOIs (0.8%) were flagged as duplicates of other DOIs. This shows the problem exists, but is not huge.
I also analyzed separately two categories of duplicates:
self-duplicates are two DOIs with (almost) identical metadata, deposited by the same member,
other-duplicates are two DOIs with (almost) identical metadata, deposited by two different members.
Self-duplicates are more common: 3,603 (85%) of all detected duplicates are self-duplicates, and only 637 (15%) are other-duplicates. This is also good news: self-duplicates involve one member only, so they are easier to handle.
Self-duplicates
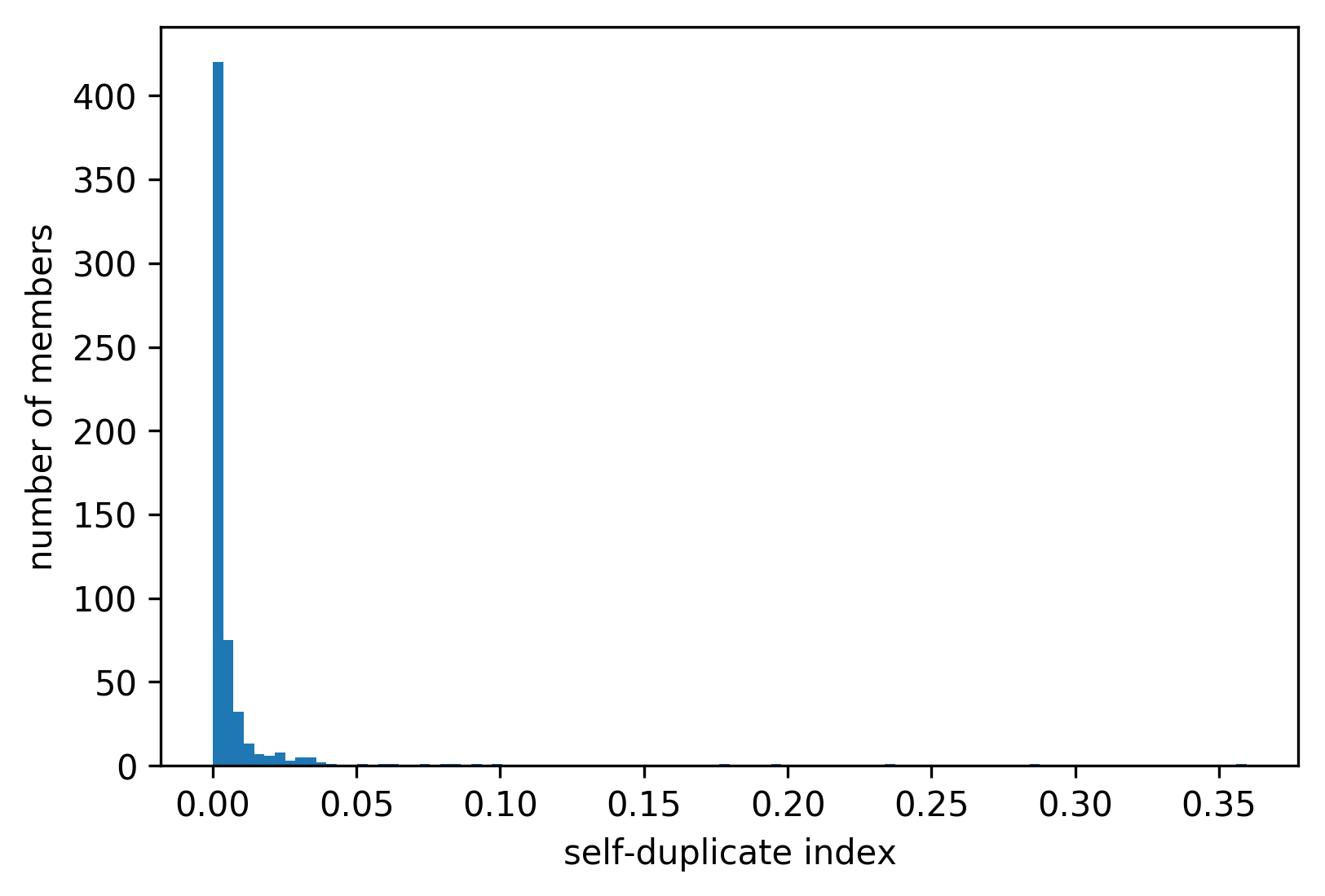
To explore the levels of self-duplicates among members, I used a custom member-level metric called self-duplicate index. Self-duplicate index is the fraction of self-duplicates among the member’s DOIs, in this case calculated over a sample.
On average, members have a very small self-duplicate index of 0.67%. In addition, in the samples of 44% of analyzed members no self-duplicates were found. The histogram shows the skewness of the distribution:
As we can see in the distribution, there are only a few members with high self-duplicate index. The table shows all members with the self-duplicate higher than 10%:
Name
Total DOIs
Sample size
Self-duplicate index
University of California Press
129,741
798
36%
Inderscience Publishers
127,729
998
29%
American Society of Hematology
137,124
990
24%
Pro Reitoria de Pesquisa, Pos Graduacao e Inovacao - UFF
7,756
919
19%
American Diabetes Association
49,536
946
18%
Other-duplicates
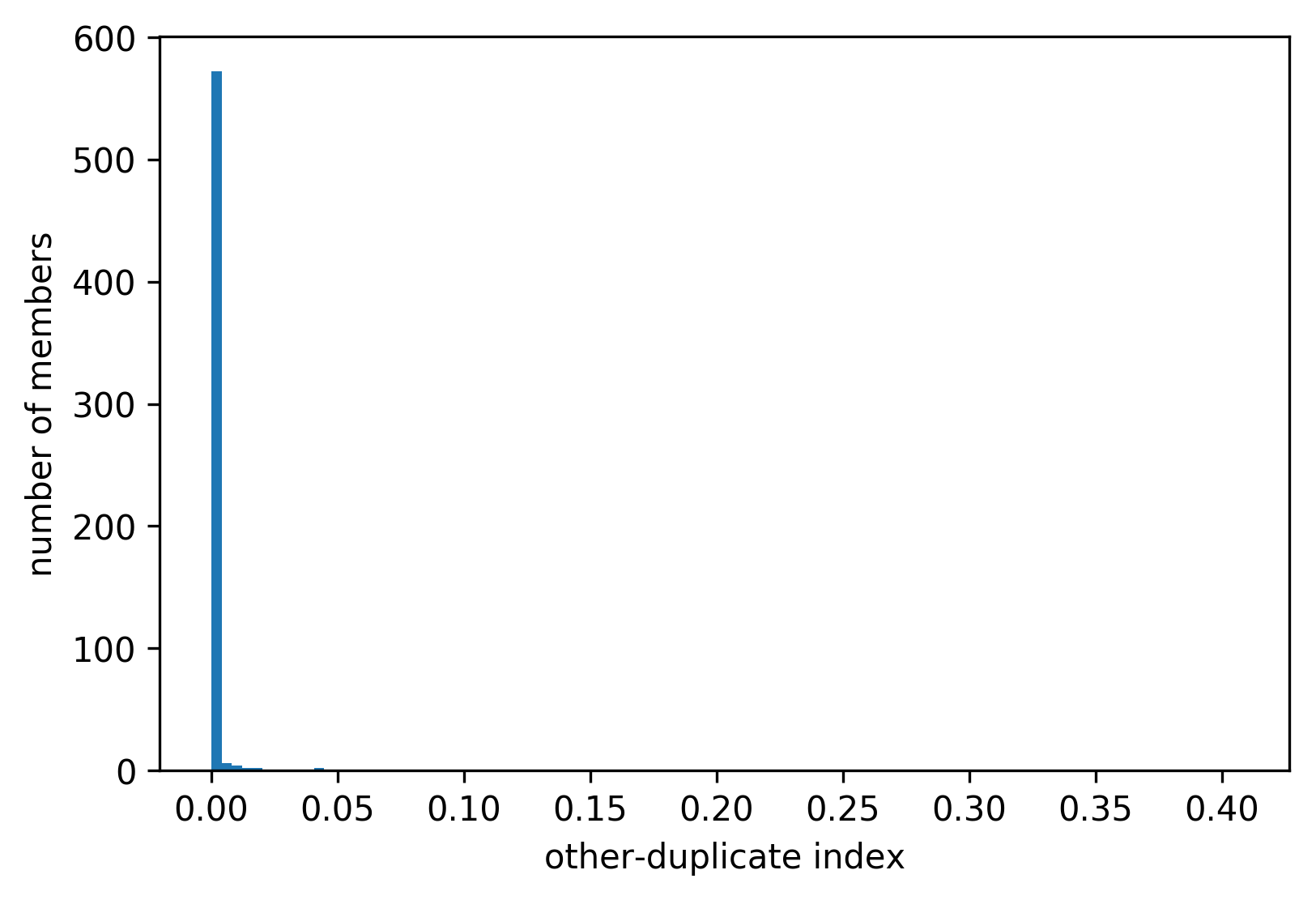
Other-duplicate index is the fraction of other duplicates among the member’s DOIs, in this case calculated from a sample.
On average, members have a very low other-duplicate index of only 0.13%. What is more, 89% members have no other-duplicates in the sample, and the distribution is even more skewed than in the case of self-duplicates:
Here is the list of all members with more than 2% of other-duplicates in the sample:
Name
Total DOIs
Sample size
Other-duplicate index
American Bryological and Lichenological Society
5,593
844
41%
Maney Publishing
15,342
832
6%
JSTOR
1,612,174
864
4%
American Mathematical Society (AMS)
83,015
844
4%
American Bryological and Lichenological Society is a clear outlier with 41% of their sample flagged as duplicates. Interestingly, all those duplicates come from one other member only (JSTOR) and JSTOR was the first to deposit them.
Similarly, all other-duplicates detected in the American Mathematical Society’s sample are shared with JSTOR, and JSTOR was the first to deposit them.
Maney Publishing’s 51 other-duplicates are all shared with a member not listed in this table: Informa UK Limited.
JSTOR is the only member in this table, whose 36 other-duplicates are shared with multiple (8) members.
Another interesting observation is that the members in this table (apart from JSTOR) are rather small or medium, in terms of total DOIs registered by them. It is also worrying that Informa UK Limited, a member that shares 51 other-duplicates flagged in Maney Publishing’s sample, was not flagged by this index. The reason might be differences in the overall number of registered DOIs: two members that deposited the same number of other-duplicates, but have different overall numbers of registered DOIs, will have different other-duplicate indexes.
To address this issue, I looked at a third index called global other-duplicate index. Global other-duplicate index is the fraction of globally detected other-duplicates involving a given member.
Global other-duplicate index has a useful interpretation: it tells us how much the overall number of other-duplicates would drop, if the given member resolved all its other-duplicates (for example by setting appropriate relations or correcting the metadata so that it is no longer so similar).
Here is the list of members with global-duplicate index higher than 2%:
Name
Total DOIs
Global other-duplicate index
JSTOR
1,612,174
69%
American Bryological and Lichenological Society
5,593
54%
Informa UK Limited
4,275,507
15%
Maney Publishing
15,342
8%
American Mathematical Society (AMS)
83,015
6%
Project Muse
326,300
5%
Wiley
8,003,815
3%
Elsevier BV
16,268,943
3%
Liverpool University Press
31,870
3%
Cambridge University Press (CUP)
1,621,713
2%
Ovid Technologies (Wolters Kluwer Health)
2,152,723
2%
University of Toronto Press Inc. (UTPress)
46,778
2%
Note that the values add up to more than 100%. This is because in every other-duplicate there are two members involved, so the involvement adds up to 200%.
As we can see, all the members from the previous table are in this one as well. Apart from them, however, this index flagged several large members. Among them, Informa UK Limited, that was missing from the previous table.
All the indexes defined here are useful in identifying members that contribute a lot of duplicates to the Crossref metadata. They can be used to help to clean up the metadata, and also to monitor the situation in the future.
Limitations
It is important to remember that index values presented here were calculated on a single sample of DOIs drawn for a given member. The values would be different if a different sample was used, and so they shouldn’t be treated as exact numbers.
The tables include members with the index exceeding a certain threshold, chosen arbitrarily, for illustrative purposes. Different runs with different samples could result in different members being included in the tables, especially in their lower parts.
To obtain more stable values of indexes, multiple samples could be used. Alternatively, in the case of smaller members, exact values could be calculated from all their DOIs.