PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
TL;DR: We no longer charge fees for members to participate in Crossmark, and we encourage all our members to register metadata about corrections and retractions - even if you can’t yet add the Crossmark button and pop-up box to your landing pages or PDFs.
–
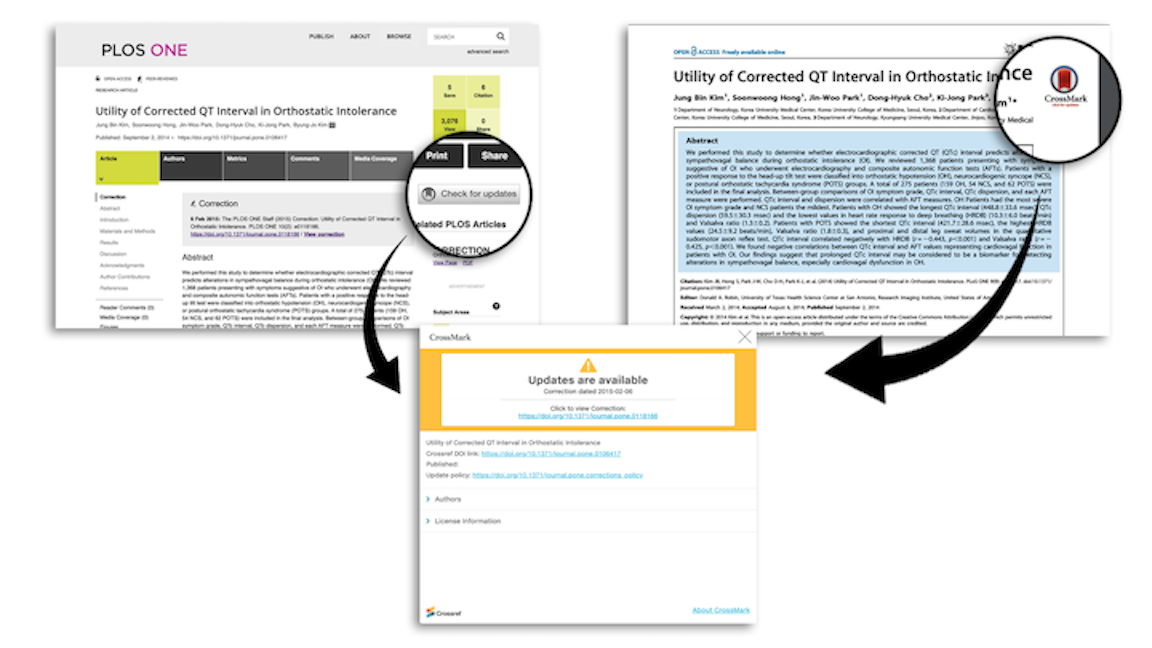
Research doesn’t stand still; even after publication, articles can be updated with supplementary data or corrections. When research outputs are is changed in this way the publisher should report and link it, so that those accessing and citing the content know if it’s been updated, corrected or even retracted. This also emphasizes the member’s commitment to the ongoing stewardship of research outputs.
Many people find and store articles to read later, either as PDFs on their laptop or on one of any number of reference management systems - when they come back to read and cite these articles, possibly many months later, they want to know if the version they have is current or not.
Removing Crossmark fees
To encourage even wider adoption of Crossmark, and to promote best practice around better reporting of corrections and retractions, we will no longer be charging additional fees for our Crossmark service. This change applies to all Crossmark metadata registered from 1 January 2020. All members are now encouraged to add Crossmark metadata and add the Crossmark button and pop-up box to their publications - and you can do so as part of your regular content registration.
Richer metadata gives important context
We know that there are many more corrections and retractions that are not yet being registered, and to address this, we are now asking all of our members to start registering metadata for significant updates to your publications, even if you don’t implement the Crossmark button and pop-up box on your content. Remember, anyone can access the Crossmark metadata through our public REST API, and start using it straight away - even if you’re not ready to implement the Crossmark button.
Check out how to get started; if you only want to deposit metadata, follow steps one through four. If you also want to add the Crossmark button and pop-up box to your web pages/PDFs so that readers can easily see when content has changed, then also follow the rest of the steps.
Crossmark
We launched Crossmark in 2012 to raise awareness of these critical changes, by asking Crossref members to:
help readers find out about the changes by placing a Crossmark button and pop-up box (which is consistent across all members making it recognizable to readers) on your landing pages and in PDFs
Members can also use Crossmark to register additional metadata about content, giving further context and background for the reader. These metadata appear in the “More Information” section of the Crossmark box. 7 million DOIs have some additional metadata, the most common being copyright statements, publication history, and peer review methods.
Anyone can access the Crossmark metadata through our public REST API, providing a myriad of opportunities for integration with other systems, and analysis of changes to the scholarly record.
Who has implemented Crossmark?
440 Crossref members have implemented Crossmark to date. 11.4 million DOIs have some Crossmark metadata.
Total DOIs
DOIs with Crossmark metadata
%
Journal articles
80,862,460
10,155,340
12.56%
Book chapters
14,040,646
792,953
5.65%
Conference Papers
6,175,733
457,237
7.40%
Datasets
1,862,852
19,206
1.03%
Books
753,298
239
0.03%
Monographs
469,333
23
0.00%
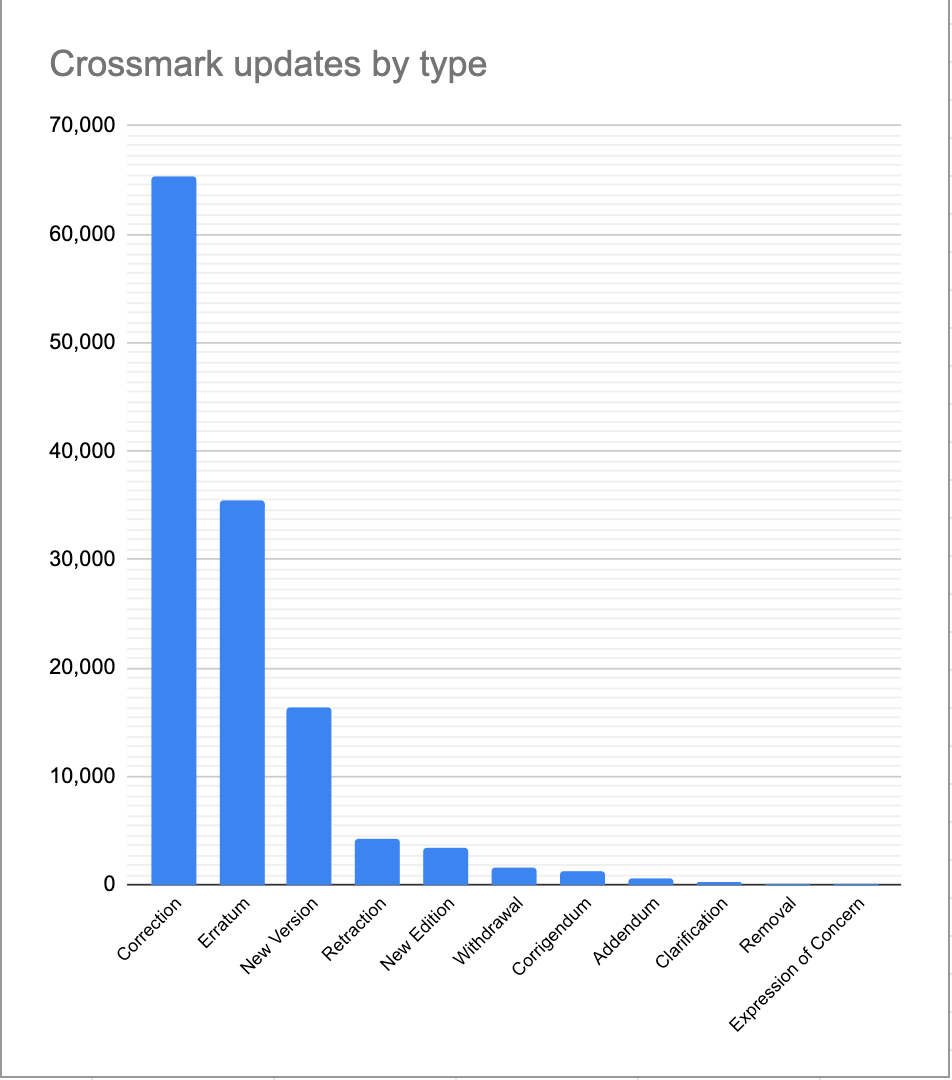
Of those, about 130,000 contain an update:
You can see which members or journals have implemented Crossmark by viewing the relevant Crossref Participation Report.