6 minute read.How do you deposit data citations?
Very carefully, one at a time? However you wish.
Last year, we introduced linking publication metadata to associated data and software when registering publisher content with Crossref Linking Publications to Data and Software. This blog post follows the “whats” and “whys” with the all-important “how(s)” for depositing data and software citations. We have made the process simple and fairly straightforward: publishers deposit data & software links by adding them directly into the standard metadata deposit via relation type and/or references. This is part of the **existing Content Registration ** process and requires no new workflows.
Relationships
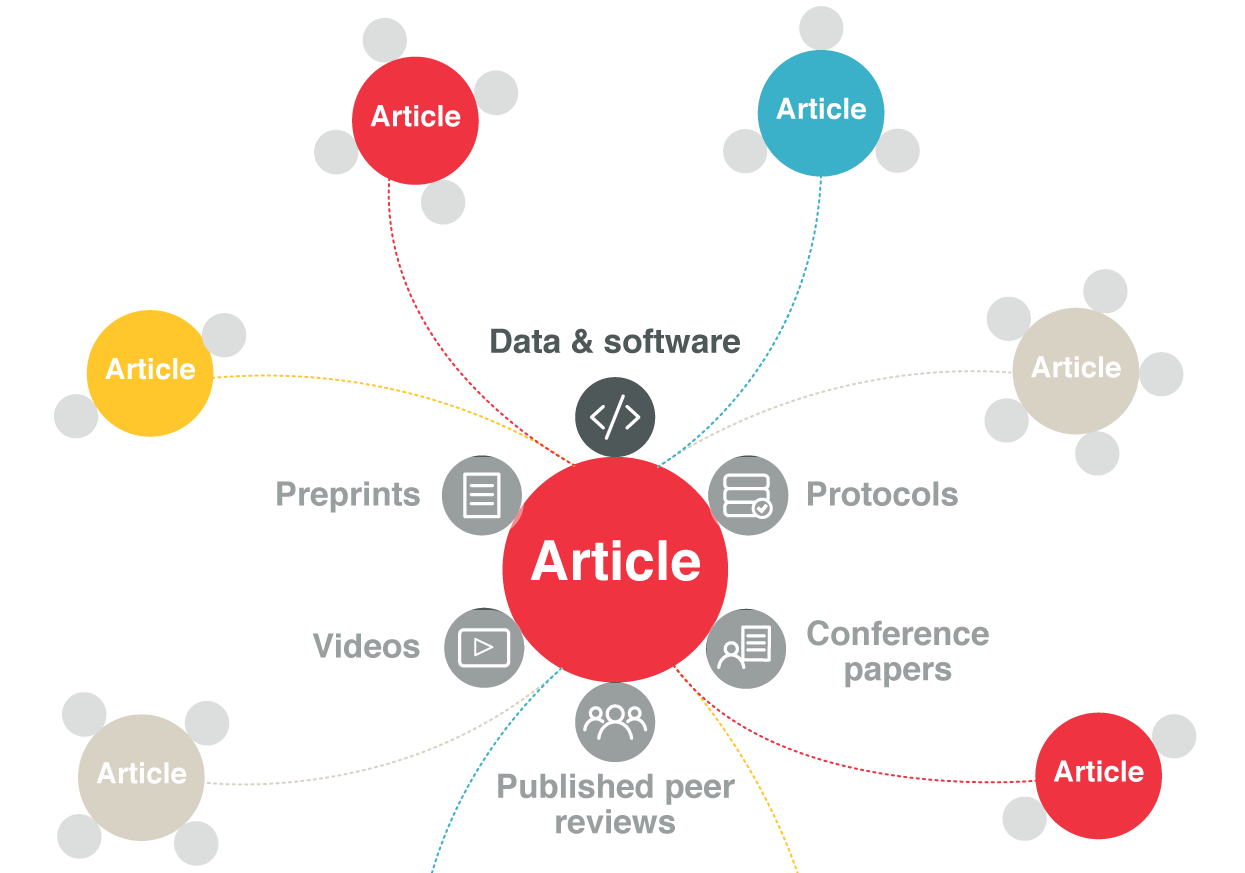
Data & software citations are a valuable part of the “research article nexus”, comprised of the publication linked to a variety of associated research objects, including data and software, supporting information, protocols, videos, published peer reviews, a preprint, conference papers, etc. For all of these resources, we use relation types in the metadata deposit to “anchor” the article in the article nexus and link to it.
For data & software, we ask for:
- identifier of the dataset/software
- identifier type: “DOI”, “Accession”, “PURL”, “ARK”, “URI”, “Other” *
- relationship type: “isSupplementedBy” or “references”
- description of dataset or software.
*Additional identifier types beyond those used for data or software are also accepted, including ARXIV, ECLI, Handle, ISSN, ISBN, PMID, PMCID, and UUID.
Crossref maintains an expansive set of relationship types to support the various resources linked in the research article nexus. For data and software, we recommend “isSupplementedBy” and “references” as relationship types in the metadata. Use the former if it was generated de novo as part of the research results. For those generated by another project and then reused, we recommend applying “references” in the relationship type. These were selected in consultation with DataCite and data working groups. They will provide the level of specificity requested by the community.
To illustrate how to represent the link within the metadata deposit, we offer two examples from two popular dataset identifiers, one for each of the relationship types.
| Dataset | Snippet of deposit XML containing link |
|---|
Dataset with DOI:
Data from: Extreme genetic structure in a social bird species despite high dispersal capacity.
Database: Dryad Digital Repository
DOI: https://doi.org/10.5061/dryad.684v0 | <program xmlns="http://www.crossref.org/relations.xsd">
<related_item>
<description>Data from: Extreme genetic structure in a social bird species despite high dispersal capacity</description>
<inter_work_relation relationship-type="isSupplementedBy" identifier-type="doi">10.5061/dryad.684v0</inter_work_relation>
</related_item>
</program> |
Dataset with accession number:
NKX2-5 mutations causative for congenital heart disease retain functionality and are directed to hundreds of targets
Database: Gene Expression Omnibus (GEO)
Accession number: GSE44902
URL: https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE44902 | <program xmlns="http://www.crossref.org/relations.xsd">
<related_item>
<description>NKX2-5 mutations causative for congenital heart disease retain and are directed to hundreds of targets</description>
<inter_work_relation relationship-type="references" identifier-type="Accession">GSE44902</inter_work_relation>
</related_item>
</program> |
| |
| In the examples above, the Dryad dataset was generated as part of the research published in an article. Hence, it contains the “isSupplementedBy” relationship type. The GEO dataset was reused by and referenced in a scholarly article published separate from the project that generated this dataset. Hence, it contains the “references” relationship type. | |
Both Crossref and DataCite employ this method of linking. Data repositories who register their content with DataCite follow the same process and apply the same metadata tags. This means that we achieve direct data interoperability with links in the reverse direction (data and software repositories to journal articles).
References
Another mechanism for depositing data and software citations is to insert it into the manuscript’s references. Publishers then deposit it as part of the article’s references. To do so, publishers follow the general process for depositing references. (Visit Crossref’s Support page for step-by-step instructions.)
Publishers can deposit the full data or software citation as a unstructured reference.
<citation key="ref=3">
<unstructured_citation>Morinha F, Dávila JA, Estela B, Cabral JA, Frías Ó, González JL, Travassos P, Carvalho D, Milá B, Blanco G (2017) Data from: Extreme genetic structure in a social bird species despite high dispersal capacity. Dryad Digital Repository. http://dx.doi.org/10.5061/dryad.684v0</unstructured_citation\>
</citation>
</citation_list>
Or they can employ any number of reference tags currently accepted by Crossref. Most do not readily suit datasets and software as the suite was originally established to match article and book references. This leaves out substantial metadata needed to identify and describe the dataset, however, if the resource does not have a DOI.
<citation key="ref2">
<doi>10.5061/dryad.684v0</doi>
<cYear>2017</cYear>
<author>Morinha F, Dávila JA, Estela B, Cabral JA, Frías Ó, González JL, Travassos P, Carvalho D, Milá B, Blanco G</author>
</citation>
We are exploring the JATS4R recommendations while we consider expanding the current collection. We welcome additional suggestions from the community.
Precise, accessible links
Crossref’s infrastructure is setup to facilitate the flow of information about scholarly works across the research network. We maintain a fair degree of flexibility both in the structure and completeness of metadata deposited. The aim, though, is to make the links rich in metadata, accurate in associating literature to corresponding resource, and available to both human and machine consumers as per Principle #5 and #7 in the Joint Declaration of Data Citation Principles.
As with the other associated resources in the article nexus, we recommend depositing data/software links in the publication metadata via relationships. Publishers are free to do this on top of or independent of references. Relationship metadata offer a high degree of precision. References are a hodgepodge of various resources cited by the publication, including articles, books, media, blogs, reference materials, etc. and data citations are hard to isolate. Furthermore, the unstructured, “spaghetti string” text is difficult for systems to parse and extract specific information.
With relationship metadata, data and software resources are expressly designated. We obtain a more accurate link that specifies identifier type and explicitly identifies data generated as part of the research shared in the paper or as reuse of existing data). The richer metadata contained here enables consumers to conduct powerful queries based on different attributes (identifier type, description, relationship), taking data discovery and mining to the next level.
Furthermore, relationships are important for achieving full accessibility of data and software citations. Access to references is based on publisher permission so not all data citations can be shared (excluding DataCite DOIs). In contrast, all links deposited via relationships are publicly available.
Publishers play an important role in supporting research validation and reproducibility. Data & software citation is a basic part of of this practice, and instrumental in enabling the reuse and verification of these research outputs, tracking their impact, and creating a scholarly structure that recognizes and rewards those involved in producing them. For the full scoop of how to deposit (i.e., technical details and more), we encourage you to reference the Crossref Data & Software Citations Deposit Guide and contact us (support@crossref.org) with questions or feedback.