PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
On January 20th, 2015 the main DOI HTTP proxy at doi.org experienced a partial, rolling global outage. The system was never completely down, but for at least part of the subsequent 48 hours, up to 50% of DOI resolution traffic was effectively broken. This was true for almost all DOI registration agencies, including Crossref, DataCite and mEDRA.
At the time we kept people updated on what we knew via Twitter, mailing lists and our technical blog at CrossTech. We also promised that, once we’d done a thorough investigation, we’d report back. Well, we haven’t finished investigating all implications of the outage. There are both substantial technical and governance issues to investigate. But last week we provided a preliminary report to the Crossref board on the basic technical issues, and we thought we’d share that publicly now.
The Gory Details
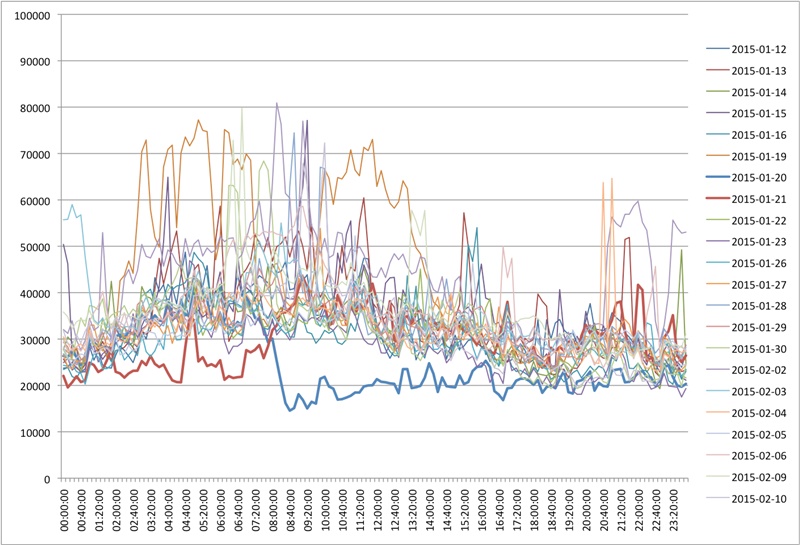
First, the outage of January 20th was not caused by a software or hardware failure, but was instead due to an administrative error at the Corporation for National Research Initiatives (CNRI). The domain name “doi.org” is managed by CNRI on behalf of the International DOI Foundation (IDF). The domain name was not on “auto-renew” and CNRI staff simply forgot to manually renew the domain. Once the domain name was renewed, it took about 48 hours for the fix to propagate through the DNS system and for the DOI resolution service to return to normal. Working with CNRI we analysed traffic through the Handle HTTP proxy and here’s the graph:
The above graph shows traffic over a 24 hour period on each day from January 12, 2015 through February 10th, 2015. The heavy blue line for January 20th and the heavy red line for January 21st show how referrals declined as the doi.org domain was first deleted, and then added back to DNS.
It could have been much worse. The domain registrar (GoDaddy) at least had a “renewal grace and registry redemption period” which meant that even though CNRI forgot to pay its bill to renew the domain, the domain was simply “parked” and could easily be renewed by them. This is the standard setting for GoDaddy. Cheaper domain registrars might not include this kind of protection by default. Had there been no grace period, then it would have been possible for somebody other than CNRI to quickly buy the domain name as soon as it expired. There are many automated processes which search for and register recently expired domain names. Had this happened, at the very least it would have been expensive for CNRI to buy the domain back. The interruption to DOI resolutions during this period would have also been almost complete.
So we got off relatively easy. The domain name is now on auto-renew. The outage was not as bad as it could have been. It was addressed quickly and we can be reasonably confident that the same administrative error will not happen again. Crossref even managed to garner some public praise for the way in which we handled the outage. It is tempting to heave a sigh of relief and move on.
We also know that everybody involved at CNRI, the IDF and Crossref have felt truly dreadful about what happened. So it is also tempting to not re-open old wounds.
But it would be a mistake if we did not examine a fundamental strategic issue that this partial outage has raised: How can Crossref claim that its DOIs are ‘persistent’ if Crossref does not control some of the key infrastructure on which it depends? What can we do to address these dependencies?
What do we mean by “persistent?”
@kaythaney tweets on definition of “persistent”
To start with, we should probably explore what we mean by ‘persistent’. We use the word “persistent” or “persistence” about 470 times on the Crossref web site. The word “persistent” appears central to our image of ourselves and of the services that we provide. We describe our core, mandatory service as the “Crossref Persistent Citation Infrastructure.”
The primary sense of the word “persistent” in the New Oxford American Dictionary is:
Continuing firmly or obstinately in a course of action in spite of difficulty or opposition.
We play on this sense of the word as a synonym for “stubborn” when we half-jokingly say that, “Crossref DOIs are as persistent as Crossref staff.” Underlying this joke is a truth, which is that persistence is primarily a social issue, not a technical issue.
Yet presumably we once chose to use the word “persistent” instead of “perpetual” or “permanent” for other reasons. “Persistence” implies longevity, without committing to “forever.” Scholarly publishers, perhaps more than most industries, understand the long term. After all, the scholarly record dates back to at least 1665 and we know that the scholarly community values even our oldest journal backfiles. By using the word “persistent” as opposed to the more emphatic “permanent” we are essentially acknowledging that we, as an industry, understand the complexity and expense of stewarding the content for even a few hundred years to say nothing of “forever.” Only the chronologically naïve would recklessly coin terms like “permalink” for standard HTTP links which have a documented half-life of well under a decade.
So “persistent” implies longevity- without committing to forever- but this still begs questions. What time span is long enough to qualify as “persistent?” What, in particular, do we mean by “persistent” when we talk about Crossref’s “Persistent Citation Infrastructure?” or of Crossref DOIs being “persistent identifiers?”
What do we mean by “persistent identifiers?”
]5 @violetailik tweets on outage and implication for term “persistent identifier”
First, we often make the mistake of talking about “persistent identifiers” as if there is some technical magic that makes them continue working when things like HTTP URIs break. The very term “persistent identifier” encourages this kind of magical thinking and, ideally, we would instead talk about “persist-able” identifiers. That is, those that have some form of indirection built into them. There are many technologies that do this- Handles, DOIs, Purls, ARKs and every URL shortener in existence. Each of them simply introduces a pointer mapping between an identifier and location where a resource or content resides. This mapping can be updated when the content moves, thus preserving the link. Of course, just because an identifier is persist-able doesn’t mean it is persistent. If Purls or DOIs are not updated when content moves, then they are no more persistent than normal URLs.
Andrew Treloar points out that when we talk about “persistent identifiers,” we tend to conflate several things:
The persistence of the identifier- that is the token or string itself.
The persistence of the thing being pointed at by the identifier. For example, the content.
The persistence of the mapping of the identifier to the thing being identified.
The persistence of the resolver that allows one to follow the mapping of the identifier to the thing being identified.
The persistence of a mechanism for updating the mapping of the identifier to the thing being identified.
If any of the above fails, then “persistence” fails. This is probably why we tend to conflate them in the first place.
Each of these aspects of “persistence” is worthy of much closer scrutiny, however, in the most recent case of the January outage of “doi.org,” the problem specifically occurred with item “D”- the persistence of the resolver. When CNRI failed to renew the domain name for “doi.org” on time, the DOI resolver was rendered unavailable to a large percentage of people over a period of about 48 hours as global DNS servers first removed, and then added back the “doi.org” domain.
The initial public reaction to the outage was, almost unanimous in one respect- people assumed that the problem originated with Crossref.
@iainh_z tweets to Crossref enquiring about failed DOI resoluton@LibSkrat tweets at Crossref about DOI outage
This is both surprising and unsurprising. It is surprising because we have fairly recent data indicating that lots of people recognise the DOI brand, but not the Crossref brand. Chances are, that this relatively superficial “brand” awareness does not correlate with understanding how the system works or how it relates to persistence. It is likely plenty of people clicked on DOIs at the time of the outage and, when they didn’t work, simply shrugged or cursed under their breath. They were aware of the term ‘DOI’ but not of the promise of “persistence”. Hence, they did not take to twitter to complain about it, and if they did, they probably wouldn’t have known who to complain to or even how to complain to them (neither CNRI or the IDF has a Twitter account).
But the focus on Crossref is also unsurprising. Crossref is by far the largest and most visible DOI Registration Agency. Many otherwise knowledgeable people in the industry simply don’t know that there are even other RAs.
They also generally didn’t know of the strategic dependencies that exist in the Crossref system. By “strategic dependencies” we are not talking about the vendors, equipment and services that virtually every online enterprise depends on. These kinds of services are largely fungible. Their failures may be inconvenient and even dramatic, but they are rarely existential.
Instead we are talking about dependencies that underpin Crossref’s ability to deliver on its mission. Dependencies that not only affect Crossref’s operations, but also its ability to self-govern and meet the needs of its membership. In this case there are three major dependencies: Two of which are specific to Crossref and other DOI registration agencies and one which is shared by virtually all online enterprises today. The organisations are: The International DOI Foundation (IDF), Corporation for National Research Initiatives (CNRI) and the Internet Corporation for Assigned Names and Numbers (ICANN).
Dependency of RAs on IDF, CNRI and ICANN. Turtles all the way down.
Each of these agencies has technology, governance and policy impacts on Crossref and the other DOI registration agencies, but here we will focus on the technological dependencies.
At the top of the diagram are a subset of the various DOI Registration Agencies. Each RA uses the DOI for a particular constituency (e.g. scholarly publishers) and application (e.g. citation). Sometimes these constituencies/applications overlap (as with mEDRA, Crossref and DataCite), but sometimes they are orthogonal to the other RAs, as is the case with EIDR. All, however, are members of the IDF.
The IDF sets technical policies and development agendas for the DOI infrastructure. This includes recommendations about how RAs should display and link DOIs. Of course all of these decisions have an impact on the RAs. However, the IDF provides little technical infrastructure of its own as it has no full-time staff. Instead it outsources the operation of the system to CNRI, this includes the management of the doi.org domain which the IDF owns.
The actual DOI infrastructure is hosted on a platform called the Handle System which was developed by and is currently run by CNRI. The Handle System is part of a quite complex and sophisticated platform for managing digital objects that was originally developed for DARPA. A subset of the Handle system is designated for use by DOIs and is identified by the “10” prefix (e.g. 10.5555/12345678). The Handle system itself is not based on HTTP (the web protocol). Indeed, one of the much touted features of the Handle System is that it isn’t based on any specific resolution technology. This was seen as a great virtue in the late 1990s when the DOI system was developed and the internet had just witnessed an explosion of seemingly transient, competing protocols (e.g. Gopher, WAIS, Archie, HyperWave/Hyper-G, HTTP, etc.). But what looked like a wild-west of protocols quickly settled into an HTTP hegemony. In practice, virtually all DOI interactions with the Handle system are via HTTP and so, in order to interact with the web, the Handle System employs a “Handle proxy” which translates back and forth between HTTP, and the native Handle system. This all may sound complicated, and the backend of the Handle system is really very sophisticated, but it turns out that the DOI really uses only a fraction of the Handle system’s features. In fact, the vast majority of DOI interactions merely use the Handle system as a giant lookup table which allows one to translate an identifier into a web location. For example, it will take a DOI Handle like this:
10.5555/12345678
and redirect it to (as of this writing) the following URL:
This whole transformation is normally never seen by a user. It is handled transparently by the web browser, which does the lookup and redirection in the background using HTTP and talking to the Handle Proxy. In the late 1990s, even doing this simple translation quickly, at scale with a robust distributed infrastructure, was not easy. These days however we see dozens if not hundreds of “URL Shorteners” doing exactly the same thing at far greater scale than the Handle System.
It may seem a shame that more of the Handle Systems features are not used, but the truth is the much touted platform independence of the Handle System rapidly became more of a liability and impediment to persistence than an aid. To be blunt, if in X years a new technology comes out that supersedes the web, what do we think the societal priority is going to be?
To provide a robust and transparent transition from the squillions of existing HTTP URI identifiers that the entire world depends on?
To provide a robust and transparent transition from the tiny subset of Handle-based identifiers that are used by about a hundred million specialist resources?
Quite simply, the more the Handle/DOI systems diverge from common web protocols and practice, then the more we will jeopardise the longevity of our so-called persistent identifiers.
So, in the end, DOI registration agencies really only use the Handle system for translating web addresses. All of the other services and features one might associate with DOIs (reference resolution, metadata lookup, content negotiation, OAI-PMH, REST APIs, Crossmark, CrossCheck, TDM Services, FundRef etc) are all provided at the RA level.
But this address resolution is still critical. And it is exactly what failed for many users on January 20th 2015. And to be clear, it wasn’t the robust and scaleable Handle System that failed. It wasn’t the Handle Proxy that failed. And it certainly wasn’t any RA-controlled technology that failed. These systems were all up and running. What happened was that the standard handle proxy that the IDF recommends RAs use, “dx.doi.org”, was effectively rendered invisible to wide portions the internet because the “doi.org” domain was not renewed. This underscores two important points.
The first is that it doesn’t much matter what precisely caused the outage. In this case it was an administrative error. But the effect would have been similar if the Handle proxies had failed of if the Handle system itself had somehow collapsed. In the end, Crossref and all DOI registration agencies are existentially dependent on the Handle system running and being accessible.
The second is that the entire chain of dependencies from the RAs down through CNRI are also dependent on the DNS system which, in turn, is governed by ICANN. We should really not be making too much of the purported technology independence of the DOI and Handle systems. To be fair, this limitation is inherent to all persistent identifier schemes that aim to work with the web. It really is “turtles all the way down.”
What didn’t fail on January 19th/20th and why?
You may have noticed a lot of hedging in our description of the outage of January 19th/20th. For one thing, we use the term “rolling outage.” Access to the Handle Proxy via “dx.doi.org” was never completely unavailable during the period. As we’ve explained, this is because the error was discovered very quickly and the domain was renewed hours after it expired. The nature of DNS propagation meant that even as some DNS servers were deleting the “doi.org” entry, others were adding it back to their tables. In some ways this was really confusing because it meant it was difficult to predict where the system was working and where it wasn’t. Ultimately it all stabilised after the standard 48-hour DNS propagation cycle.
But there were also some Handle-based services that simply were not affected at all by the outage. During the outage, a few people asked us if there was an alternative way to resolve DOIs. The answer was “yes,” there were several. It turns out that “doi.org” is not the only DNS name that points to the Handle Proxy. People could easily substitute “dx.doi.org” with “dx.crossref.org” or “dx.medra.org” or “hdl.handle.net” and “resolve” any DOI. Many of Crossref’s internal services use these internal names and so the services continued to work. This is partly why we only discovered the “doi.org” was down from people reporting it on Twitter.
And, of course, there were other services that were not affected by the outage. Crossmark, the REST API, and Crossref Metadata Search all continued to work during the outage.
Protecting ourselves
So what can we do to reduce our dependencies and/or the risks intrinsic to those dependencies?
Obviously, the simplest way to have avoided the outage would have been to ensure that the “doi.org” domain was set to automatically renew. That’s been done. Is there anything else we should do? A few ideas have been floated that might allow us to provide even more resilience. They range greatly in complexity and involvement.
Provide well-publicised public status dashboards that show what systems are up and which clearly map dependencies so that people could, for instance, see that the doi.org server was not visible to systems that depended on it. Of course, if such a dashboard had been hosted at doi.org, nobody would have been able to connect to it. Stoopid turtles.
Encourage DOI RAs to have the members point to Handle proxies using domain names under the RA’s control. Simply put, if Crossref members had been using “dx.crossref.org” instead of “dx.doi.org”, then Crossref DOIs would have continued to work throughout the outage of “doi.org”. The same with mEDRA, and the other RAs. This way each RA would have control over another critical piece of their infrastructure. It would also mean that if any single RA made a similar domain name renewal mistake, the impact would be isolated to a particular constituency. Finally, using RA-specific domains for resolving DOIs might also make it clear that different DOIs are managed by different RAs and might have different services associated with them. Perhaps Crossref would spend less time supporting non-Crossref DOIs?
Provide a parallel, backup resolution technology that could be pointed to in the event of a catastrophic Handle System failure. For example we could run a parallel system based on PURLs, ARKs or another persist-able identifier infrastructure.
Explore working with ICANN to get the handle resolvers moved under the special “.arpa” top level domain (TLD). This TLD (RFC 3172) is reserved for services that are considered to be “critical to the operation of the internet.” This is an option that was first discussed at a meeting of persistent identifier providers in 2011.
These are all tactical approaches to addressing the specific technical problem of the Handle System becoming unavailable, but they do not address deeper issues relating to our strategic dependence on several third parties. Even though the IDF and CNRI provide us with pretty simple and limited functionality, that functionality is critical to our operations and our claim to be providing persistent identifiers. Yet these technologies are not in our direct control. We had to scramble to get hold of people to fix the problem. For a while, we were not able to tell our users or members what was happening because we did not know ourselves.
The irony is that Crossref was held to account, and we were in the firing line the entire time. Again, this was almost unavoidable. In addition to being the largest DOI RA, we are also the only RA that has any significant social media presence and support resources. Still, it meant that we were the public face of the outage while the IDF and CNRI remained in the background.
And this is partly why our board has encouraged us to investigate another option:
Explore what it would take to remove Crossref dependencies on the IDF and CNRI.
Crossref is just part of a chain of dependencies the goes from our members down through the IDF, CNRI and, ultimately, ICANN. Our claim to providing a persistent identifier structure depends entirely on the IDF and CNRI. Here we have explored some of the technical dependencies. But there are also complex governance and policy implications of these dependencies. Each organisation has membership rules, guidelines and governance structures which can impact Crossref members. Indeed, the IDF and CNRI are themselves members of groups (ISO and DONA, respectively) which might ultimately have policy or governance impact for DOI registration agencies. We will need to understand the strategic implications of these non technical dependencies as well.
Note that the Crossref board has merely asked us to “explore” what it would take to remove dependencies. They have not asked us to actually take any action. Crossref has been massively supportive of the IDF and CNRI, and they have been massively supportive of us. Still, over the years we have all grown and our respective circumstances have changed. It is important that occasionally we question what we might have once considered to be axioms. As we discussed above, we use the term “persistent” which, in turn, is a synonym for “stubborn.” At the very least we need to document the inter-dependencies that we have so that we can understand just how stubborn we can reasonably expect our identifiers to be.
The outage of January 20th was a humbling experience. But in a way we were lucky: Forgetting to renew the domain name was a silly and prosaic way to partially bring down a persistent identifier infrastructure, but it was also relatively easy to fix. Inevitably, there was a little snark and some pointed barbs directed at us during the outage, but we were truly overwhelmed by the support and constructive criticism we received as well. We have also been left with a clear message that, in order for this good-will to continue, we need to follow-up with a public, detailed and candid analysis of our infrastructure and its dependencies. Consider this to be the first section of a multi-part report.
@kevingashley tweets asking for followup analysis@WilliamKilbride tweets asking for followup and lessons learned
Image Credits
Turtle image CC-BY “Unrecognised MJ” from the Noun Project