[Update - 2009.06.07: As pointed out by Todd Carpenter of NISO (see comments below) the phrase “SRU by contrast is an initiative to update Z39.50 for the Web” is inaccurate. I should have said “By contrast SRU is an initiative recognized by ZING (Z39.50 International Next Generation) to bring Z39.50 functionality into the mainstream Web“.]
[Update - 2009.06.08: Bizarrely I find in mentioning query languages below that I omitted to mention SQL. I don’t know what that means. Probably just that there’s no Web-based API. And that again it’s tied to a particular technology - RDBMS.]
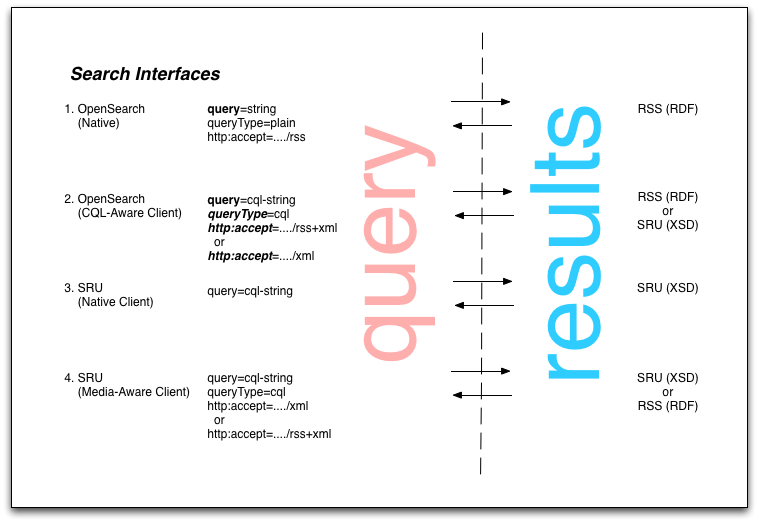
(Click image to enlarge.)
There are two well-known public search APIs for generic Web-based search: OpenSearch and SRU. (Note that the key term here is “generic”, so neither Solr/Lucene nor XQuery really qualify for that slot. Also, I am concentrating here on “classic” query languages rather than on semantic query languages such as SPARQL.)
OpenSearch was created by Amazon’s A9.com and is a cheap and cheerful means to interface to a search service by declaring a template URL and returning a structured XML format. It therefore allows for structured result sets while placing no constraints on the query string. As outlined in my earlier post Search Web Service, there is support for search operation control parameters (pagination, encoding, etc.), but no inroads are made into the query string itself which is regarded as opaque.
SRU by contrast is an initiative to update Z39.50 for the Web and is firmly focussed on structured queries and responses. Specifically a query can be expressed in the high-level query language CQL which is independent of any underlying implementation. Result records are returned using any declared W3C XML Schema format and are transported within a defined XML wrapper format for SRU. (Note that the SRU 2.0 draft provides support for arbitrary result formats based on media type.)
One can summarize the respective OpenSearch and SRU functionalities as in this table:
| Structure | <th width="33%" align="center">
OpenSearch
</th>
<th width="33%" align="center">
SRU
</th>
|---|
| query | <td align="center">
no
</td>
<td align="center">
yes
</td>
| results | <td align="center">
yes
</td>
<td align="center">
yes
</td>
| control | <td align="center">
yes
</td>
<td align="center">
yes
</td>
| diagnostics | <td align="center">
no
</td>
<td align="center">
yes
</td>
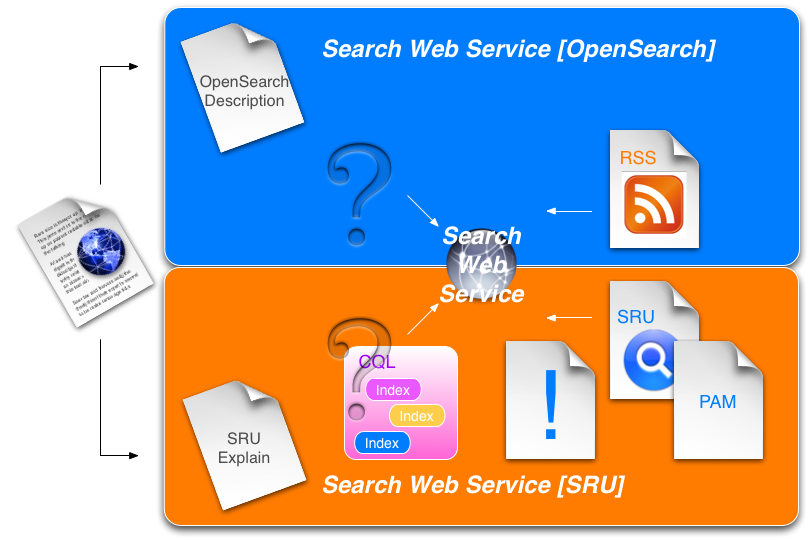
What I wanted to discuss here was the OpenSearch and SRU interfaces to a Search Web Service such as outlined in my previous post. The diagram at top of this post shows query forms for OpenSearch and SRU and associated result types. The Search Web Service is taken to be exposing an SRU interface. It might be simplest to walk through each of the cases.
(Continues below.)