8 minute read.Resolution reports: a look inside and ahead
Isaac Farley, technical support manager, and Jon Stark, software developer, provide a glimpse into the history and current state of our popular monthly resolution reports. They invite you, our members, to help us understand how you use these reports. This will help us determine the best next steps for further improvement of these reports, and particularly what we do and don’t filter out of them.
Isaac joined Crossref in April 2018. Before that, he was with one of our members, a geoscience society in Oklahoma (USA). As a Crossref member, like all of our members, he received the resolution reports to his inbox during the first week of each month. And like many of you, he had questions.
- What exactly is this report?
- What are all these numbers?
- Now, what about those 10 top DOIs is making them so popular?
- Why are some of these DOIs failing?
- And, what’s with this filtering of “known search engine crawlers?”
Now that Isaac is the Crossref Technical Support Manager, instead of asking these questions, he answers many of them.
Whoa…too fast…what exactly are resolution reports?
The resolution report provides an overview of DOI resolution traffic, and can identify problems with your DOI links. The failed DOI.csv linked to your resolution report email contains a list of all DOIs with failed resolution attempts (more on this later). If a user clicks on a DOI with your DOI prefix and the DOI is not registered, it won’t resolve to a web page, and thus will appear on your report.
What are those numbers?
This is always a good starting point for wrangling statistical information. Resolution statistics are based on the number of DOI resolutions made through the DOI proxy server on a month-by-month basis. These statistics give an indication of the traffic generated by users - both human and machine - clicking (or, resolving) DOIs. CNRI (the organisation that manages the DOI proxy server) sends us resolution logs at the end of every month and we pass the data on to you.
Resolution reports are sent by default to the business contact on your account, and we can always add or change the recipient(s) as needed. We send a separate report for each DOI prefix you’re responsible for.
Historically we have done our best to filter out obvious crawlers and machine activity - thus valuing human-driven traffic to traffic generated by machines. That sentence above about those obvious crawlers is the real reason we are here today blogging.
Why are some of those DOIs failing?
The ideal failure rate is 0%. A failure rate of 0% would mean that every DOI you owned that was clicked in the previous month successfully resolved to the resolution URL you registered with us. But, in reality, a 0% failure rate is rare, because any string of characters that is combined with your prefix (e.g., 10.5555/ThisIsNOTARealDOI) and attempted to be resolved will go through the resolver and result in another single failed count toward your monthly resolution report. If you are new to Crossref, or have only deposited metadata for a small number of content items, you may have a high failure percentage (for example, 2 failures and 8 successes = 20% failure rate).
Before 2019, the overall resolution failure rate across all publishers held fairly steady each month between 2 and 4%. You may have noticed that that number has been climbing this year. And, as a result, we think a new normal is closer to 10%.
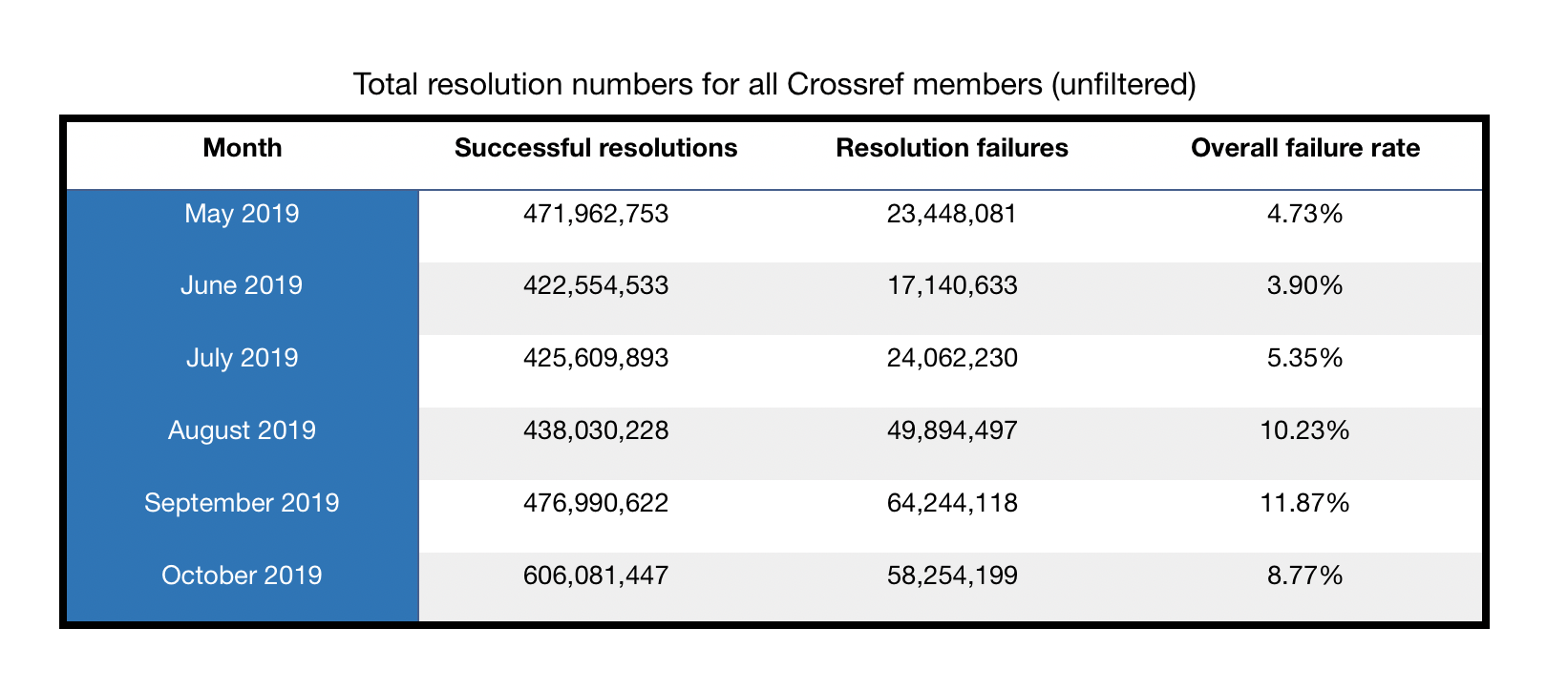
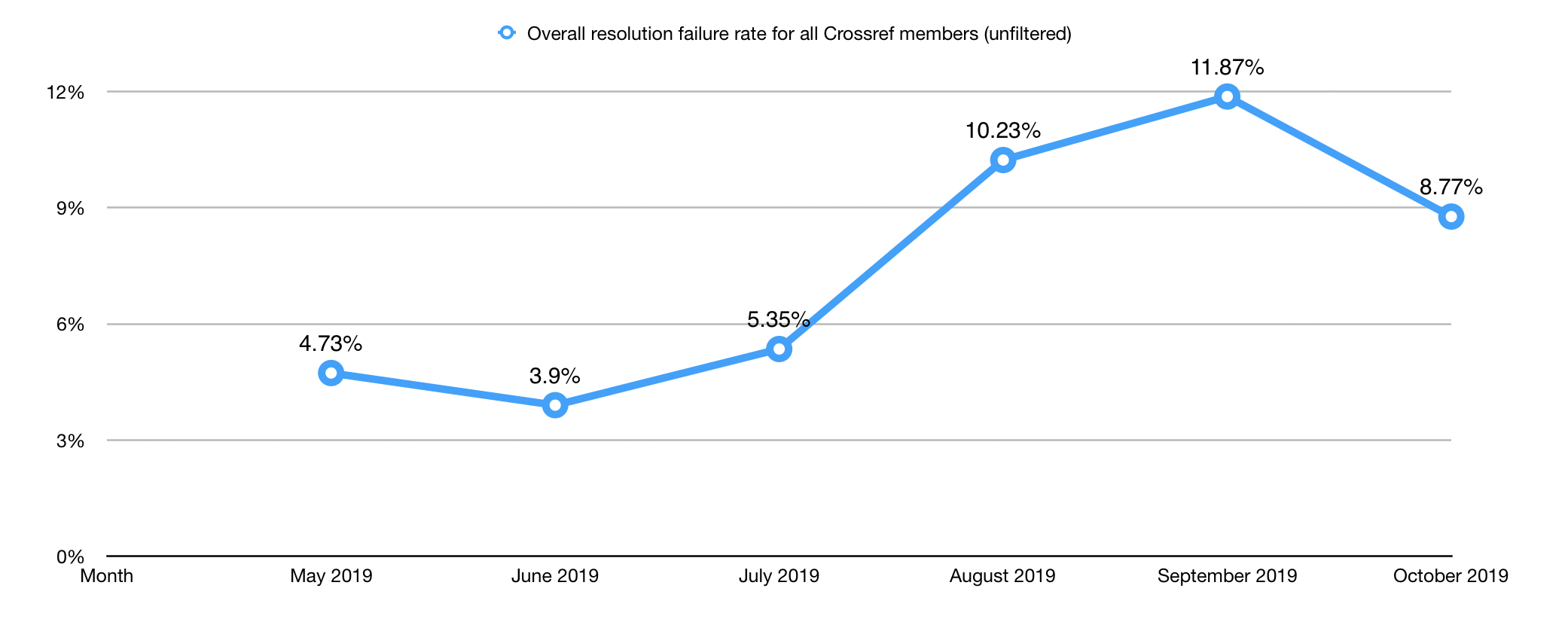
Given this new norm, if your overall resolution failure rate is higher than 8 to 12%, we advise you to look closely at the failed DOI.csv file that we include in the monthly report we email you. The first step in your analysis of this portion of the report is to make sure the DOIs listed have been registered. Very often failures of legitimate DOIs are the result of content registration errors or workflow inefficiencies (i.e., DOIs are shared with the editorial team and/or contributors before being registered with us, leading to premature clicks). If during your investigation, you find invalid DOIs (like the example above: 10.5555/ThisIsNOTARealDOI) - and you will find invalid DOIs because we all make mistakes when resolving DOIs - you may simply ignore those DOIs within the report.
What’s with this filtering of “known search engine crawlers?”
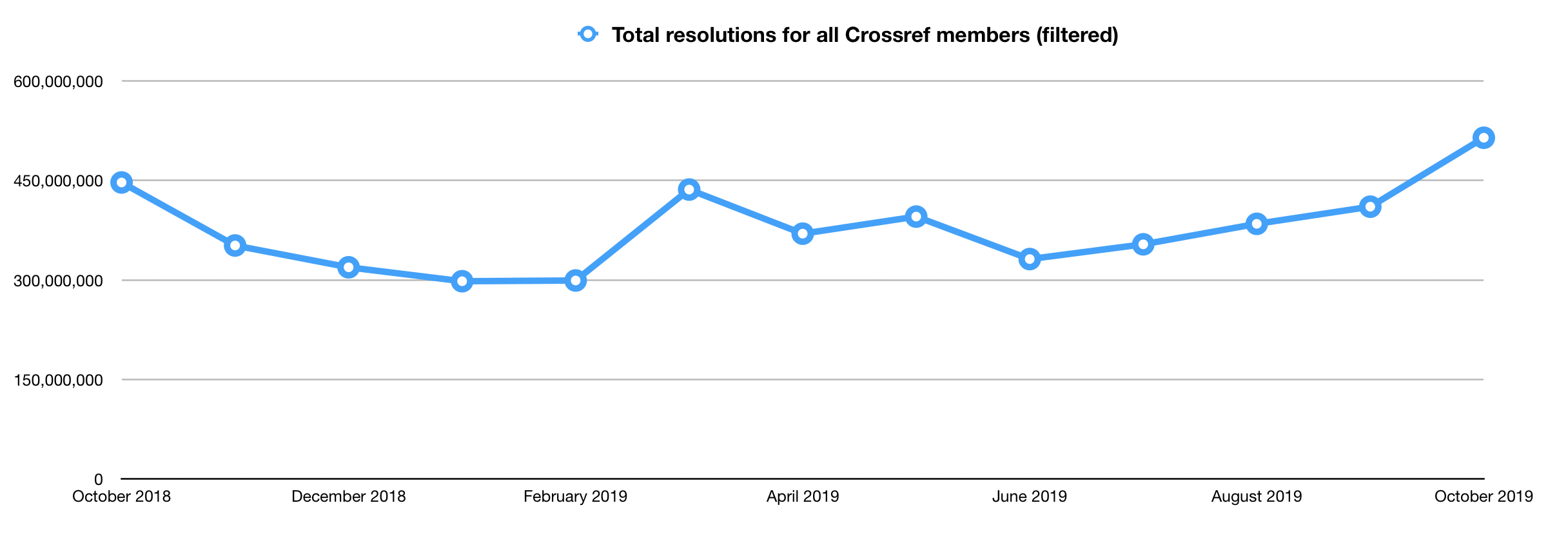
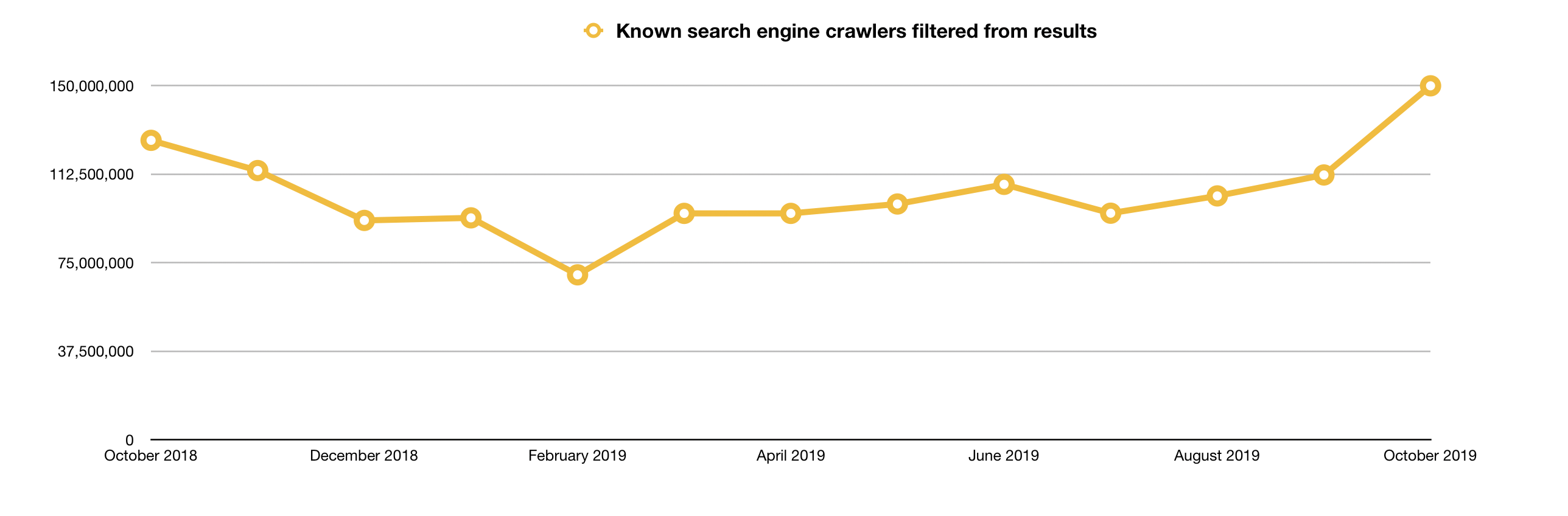
You may have recently noticed that we made a few changes to the resolution reports. We merged, rearranged, and in some cases completely rewrote the report you receive to your inboxes, because, well, it needed it. It was confusing. Parts of the report still are. Most specifically, those “known search engine crawlers.” To that point, you may have also noticed that the reports that arrived to your inboxes in early November 2019 were scrubbed of nearly 150 million resolutions across all members.
Based on Jon’s analysis of these 150 million filtered resolutions, they were from bots. In the past, it was important to filter out bots, as we found our community was most focused on human readers. But should we be filtering out resolutions from bots any more? We live in a time where most of our work (at least in the Crossref community) requires both human and machine interaction; thus, aren’t at least some of these resolutions from machines legitimate?
Our internal analysis shows that we cannot reliably determine which usage is from:
- Individual humans;
- Machines acting as intermediaries between researchers and DOIs;
- Internet service providers with real human users behind them; or,
- Bots that do not result in actual human usage.
As a result, it is our thinking that we may serve you better by not filtering any traffic, as we cannot guarantee that we’re removing the right things. We feel that it may be better for us to just give you everything we know. And invite you to make your own judgments.
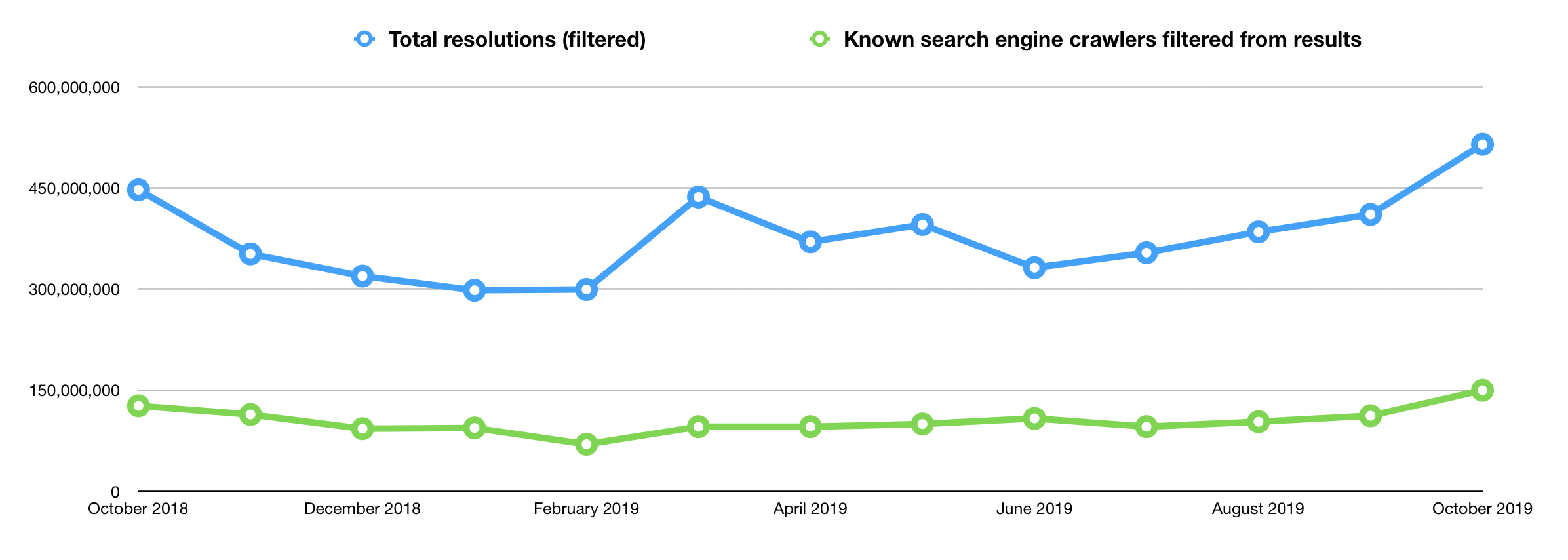
How’d we get here?
Jon joined Crossref in 2004. He wrote the original version of the resolution report in late 2009 in an effort to provide you, our members, with information about the usage of registered Crossref DOIs. At that time, most members were creating DOIs, but then had no real feedback about the traffic that was getting to their content (via the DOI proxy server lookups of their DOIs). These reports filled that gap. The other benefit of the report was the information it provided about failed resolutions. As suggested above, the list of failed resolutions helped members identify potential problems with the content registration process.
A DOI that appeared on the report as a failed resolution could be cause of concern for the member. But, then again, humans and machines make mistakes when attempting to resolve DOIs (e.g., typos). Thus, not much has changed in the last ten years - the DOIs that appear in the failed resolution reports must be evaluated. Care should especially be taken when a DOI that should have been registered has not and appears as a failed resolution (e.g., data problem, agent behind on deposits, etc.) within this report.
Like we said, mistakes happen. Users may enter a DOI incorrectly when looking it up. Or, it could be a bot throwing randomly generated traffic that looks like a DOI, but is not. And, sometimes bots are scraping through PDFs for DOIs and simply extract them incorrectly. These are all user errors, and not necessarily a concern for our members. That’s why we provide that list of what failed.
At the start, there were a few well known crawlers that were resolving large numbers of DOIs regularly. It was our opinion at the time that it would be helpful to filter that usage since we assumed members only cared about human-driven traffic. As the next decade passed, it became clear that the internet had and would continue to change. With bots popping up every day and IP addresses moving or spanning broad address ranges (and IPs we had already filtered with the potential of being repurposed), it was obvious that we would always miss as much as we caught.
Between the constantly changing landscape and the fact that real usage can be hidden behind IP addresses that appear like bot traffic, we no longer have confidence in our filtering process. It may be best for our users to just get the data as the data exists and know that our metadata world covers a vast range of usages - many as valid and valuable today as that human-driven traffic we prioritized ten years ago. Perhaps there is some other metric we can provide that might be useful for understanding the traffic in better ways, but filtering some of this traffic seems no longer useful.
Your help with next steps
There you have it. Our thinking: we’ve been filtering these resolution reports the best we can for ten years. Today, our confidence in the filtering process has waned. We’re proposing a change: we want to give you the raw resolution numbers, for machines and humans alike. We want to make this change soon, but we also want to hear from you.
- How are you using the resolution reports?
- What you do you think of this proposed change?
- Will our removal of all filters from monthly resolution reports affect how you use the information within?
We want to hear from you, and we’re inviting you to help us determine our next steps. We are going to give you until Friday, 31 January to tell us what you think of this proposed change. Then, Isaac and Jon will be back in early February to share with you what you have helped us decide. Thanks in advance!
Further reading
- Apr 10, 2020 – Changes to resolution reports
- Jan 25, 2024 – Solving your technical support questions in a snap!
- Jun 30, 2026 – Building, refining, and connecting: summary of our May 2026 community update
- Mar 30, 2026 – DOI resolution and deposit outage on 17 March 2026
- Feb 3, 2026 – Innovation in scientific publishing and its implications for Crossref DOI registration practices - MetaROR’s approach
- Nov 6, 2025 – The sunset is on the horizon for Metadata Manager. What's next?
- Sep 25, 2025 – Innovation in scientific publishing and its implications for Crossref DOI registration practices - Request for input
- Jun 24, 2025 – Scholarly blogs and their place in the research nexus




