8 minute read.ROR announces the first Org ID prototype
What has hundreds of heads, 91,000 affiliations, and roars like a lion? If you guessed the Research Organization Registry community, you’d be absolutely right!
Last month was a big and busy one for the ROR project team: we released a working API and search interface for the registry, we held our first ROR community meeting, and we showcased the initial prototypes at PIDapalooza in Dublin.
We’re energized by the positive reception and response we’ve received and we wanted to take a moment to share information with the community. Here are the links to our latest work, a recap of everything that happened in Dublin, some of the next steps for the project, and how the community can continue to be involved.
🎉 Ta da! The first ROR prototype
The Research Organization Registry (ROR) is finally here! We’re thrilled to officially announce the launch of our ROR MVR (minimum viable registry). The MVR consists of the following components, which are ready for anyone to use right now.
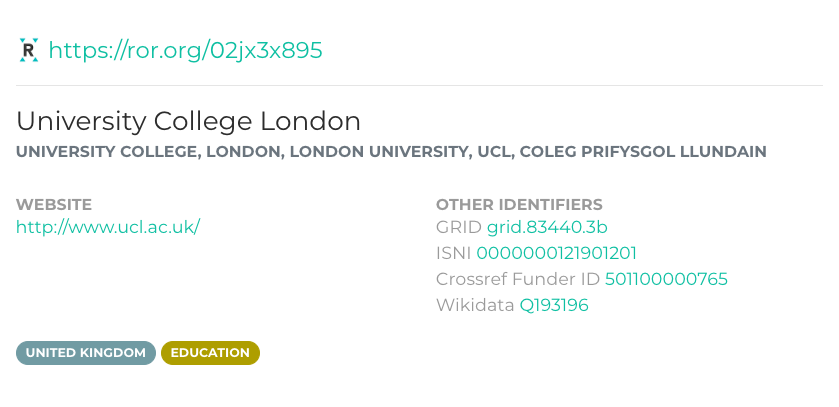
ROR IDs: Starting with seed data from GRID, ROR has begun assigning unique identifiers to approximately 91,000 organisations in its registry. ROR IDs include a random, unique, and opaque 9-character string and are expressed as URLs that resolve to the organisation’s record. For instance, here is the ROR ID for California Digital Library: https://ror.org/03yrm5c26
Search: We also built a search interface to look up organisations in the registry: https://ror.org/search.

- ROR records: ROR IDs are stored with additional metadata about the organisation, such as alternate names/abbreviations, external URLs (e.g., an organisation’s official website), and other identifiers, such as Wikidata, ISNI, and the Open Funder Registry. This metadata will allow ROR to be interoperable with other identifiers and across different systems. The current schema is based on GRID’s dataset and we plan to incorporate other metadata fields over time and according to community needs.
On January 22, 60+ representatives from across the research and publishing community gathered in Dublin to see what the ROR project team has been up to, demo the first prototypes in action, and discuss where we want to go next - and, of course, to practice ROR-ing together.
<img src="/images/blog/pride-of-lions.jpg" alt=“ROR-ing lions Dublin 2019" height=“300px” class=“img-responsive”>
In the second half of the meeting, attendees split into discussion groups to identify specific aspirations for ROR and brainstorm concrete actions needed to achieve these goals, focusing on the main use case of exposing and capturing all research outputs of a given institution. The proposed ideas covered a spectrum of possibilities for ROR, highlighting the following themes:
ROR as seamlessly-integrated and sometimes invisible infrastructure
Integration between and within existing systems (and in new ones!)
Auto-detection of ROR IDs for example in manuscript tracking and funding application platforms
As such, researchers don’t ever have to be responsible for knowing what a ROR is and using it appropriately - the systems they use will do this for them.
ROR as a critical piece of funder workflows and infrastructure
Demonstrate to funders how ROR can help them analyze impact of research they fund
Conduct outreach with key international funders, especially those interested in open infrastructure
Make funders aware of ROR and encourage them to adopt and mandate use of ROR IDs - involve funders at the beginning to collaborate on technology
Integrate ROR with existing systems and identifiers already in use by funders and other stakeholders
ROR as a trusted registry, collaborative partner, and responsible steward
Culturally sensitive, inclusive, and respectful of what countries are already doing with regard to organisational identifiers, partnering with national bodies working on this and mapping ROR IDs to locally used identifiers.
Involve the institutions listed in the registry early on as well as CRIS systems
Interoperability with existing communities and governance bodies
Workflows to support trust and responsible management of organisational metadata, with policies and procedures for long-term curation and maintenance of records
What we’re hearing
Now that the ROR MVR is here, we’re hearing some really good questions about the data we’re capturing, how it can be used, and how we’ll be maintaining the registry going forward. We wanted to take a moment to respond to some of these questions.
What is the criteria for being listed in ROR? What is a “research organisation”?
We define the notion of “research organisation” quite broadly as any organisation that conducts, produces, manages, or touches research. This is in line with ROR’s stated scope, which is to address the affiliation use case and be able to identify which organisations are associated with which research outputs. We use “affiliation” to describe any formal relationship between a researcher and an organisation associated with researchers, including but not limited to their employer, educator, funder, or scholarly society.
Will ROR map organisational hierarchies?
No - ROR is focused on being a top-level registry of organisations so we can address the fundamental affiliation use case, and provide a critical source of metadata that can interoperate with other institutional identifiers.
ROR IDs are cool - what can I do with them?
Now that we have built our MVR, we will be working to incorporate ROR IDs into relevant pieces of the scholarly communication infrastructure. If you are a publisher, funder, metadata provider, research office, or anyone else interested in capturing affiliations, please get in touch with us to discuss how we might coordinate. If you are a developer, you are welcome to start playing around with the API: https://api.ror.org/organisations.
There’s an error in my organisation’s ROR record — can you fix it?
For the time being, please email info@ror.org to request an update to an existing record in ROR or request that a new record be added. We will formalize our data management policies and procedures in the next stage of the project.
What is ROR’s relationship to other organisational identifiers?
For ROR to be useful, it needs to augment the current offerings in a way that is open, trusted, complementary, and collaborative, and not intentionally competitive. We are committed to providing a service that the community finds helpful and not duplicative, and enables as many connections as possible between organisation records across systems.
I have my own dataset of institutional affiliations — can I give it to ROR?
We are always happy to hear about other efforts to capture affiliation data. Please get in touch with us to discuss how we might coordinate.
Can ROR support multiple languages and character sets?
GRID already supports multiple languages and character sets, so by extension ROR will have this enabled as well. Here is one example: https://ror.org/01k4yrm29.
How will ROR handle curation, i.e., updating records if an organisation changes its name or ceases to exist?
The curation and long-term management of records will be a cornerstone of our efforts in 2019 and we hope to release a working set of policies and procedures soon.
What’s next for ROR
Now that we have our MVR, what happens next for ROR? We’re eager to sustain the momentum from January’s stakeholder meeting at the same time we know there are some longer-term plans to put in place, and so we’re looking at both some immediate tasks as well as bigger-picture questions.
Product development
We have a few to-do items on our list following the launch of the MVR to keep everything running smoothly while we develop a comprehensive long-term product roadmap.
Rewrite some of the code for both the API and the OpenRefine reconciler
Address a few bugs in our repos
Provide guidance for troubleshooting issues
Communicate our processes for users to request changes, report bugs, and suggest features
As a reminder, you can access the existing code in Github: https://github.com/ror-community
Policy development
We’ve been emphasizing here and in community conversations that our primary focus now turns to formulating policies and procedures to ensure the successful management of ROR data over the long term. This is something we can’t (and shouldn’t) do on our own — we want to work with community stakeholders to develop the right solutions and establish the right frameworks. We understand the urgency of firming up these policies, but we are also aware that something this important can take time to complete and is not something to rush into lightly.
To help guide the next stages of the project, we are putting out an open call for participation in the ROR community advisory group. Advisory group members will be involved in giving input on data management, testing out new features, giving feedback on the product roadmap, and discussing ideas for events and outreach. We plan to convene this advisory group through bimonthly calls and asynchronous communication channels through the end of the year. We hope you will consider joining us! Please email info@ror.org if you are interested.
For those who want to stay informed about the project but not necessarily be part of the advisory group, you have other options!
You can also always drop us a line at info@ror.org, and let us know if you’d ever like to set up a meeting or conference call to talk about the project in more detail.
Final thoughts
Community engagement has been vital to ROR’s beginnings and will likewise be critically important for the next steps that we take. As both a registry of identifiers and a community of stakeholders involved in building open scholarly infrastructure, ROR depends on guidance and involvement at multiple levels. Thank you for being part of the journey thus far, and for joining us on the road that lies ahead. 🦁




