4 minute read.Search: An Evolution
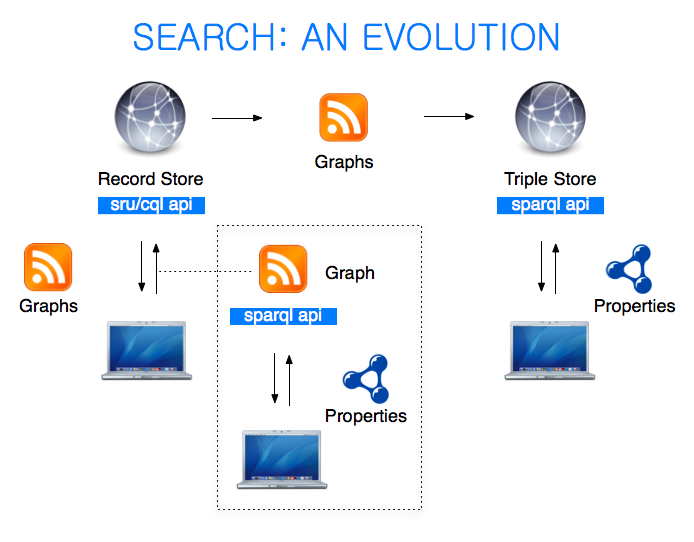
(Click image for full size graphic.)
I thought I could take this opportunity to demonstrate one evolution path from traditional record-based search to a more contemporary triple-based search. The aim is to show that these two modes of search do not have to be alternative approaches but can co-exist within a single workflow.
Let me first mention a couple of terms I’m using here: ‘graphs’ and ‘properties’. I’m using ‘property’ loosely to refer to the individual RDF statement (or triple) containing a property, i.e. a triple is a ‘(subject, property, value)’ assertion. And a ‘graph’ is just a collection of ‘properties’ (or, more properly, triples). Oh, and I’ll also use the term ‘records’ when considering ‘graphs’ as pre-fabricated objects returned within a result set.
So, what do we have here? We have on the left a traditional means of disseminating search results which is typically record based. A new set of records may be generated by querying using the API provided, whether proprietary or public such as Lucene or SRU/CQL. We can thus consider this search service as a ‘record store’ – even though records tend to generated anew rather than retrieved. The individual records in the result set are collections or groupings of ‘properties’ about the subjects of the query. Note that this is somewhat similar to the way music is packaged for physical distribution with many tracks (‘properties’) combined onto a single album (‘record’ or ‘graph’) which contains a thematic coherence – either same artist or compilation around a given topic.
Digital music distribution, on the other hand, allows for albums to be atomized so that individual tracks may be cherry-picked at will. This is not dissimilar from what happens in a ‘triple store’ where the basic properties (‘tracks’) that in a regular search engine were together combined in a ‘record’ (‘album’) to present a search result can now be plucked apart and recombined into newer bespoke ensembles. Note that this querying and recombination can be applied across the full triple store or even across this triple store and remote triple stores since the same data model is applied. Certainly, at the data model level federated searching thus becomes a non-issue.
Suppose now that our search server (or record store) is an OpenSearch-type service, i.e. the result sets are distributed as some list-based format, typically RSS, and that the list-based format either provides an RDF graph or can be transformed to such a graph, we could then use that as a basis for feeding an RDF triple store.
So, now then at right we have a triple store which is a large database of triples (or properties) compiled from all the records in the record store. And since this is a triple store we can query it using SPARQL. For example, this trival SPARQL query:
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX prism: <http://prismstandard.org/namespaces/basic/2.0/>
SELECT ?doi ?title
WHERE {
?s prism:doi ?doi .
?s dc:title ?title .
FILTER regex(?title, "boson", "i" )
}
LIMIT 5
returns the first five articles (referenced by DOI) with title containing the word ‘boson’:
--------------------------------------------------------------------------------------------------
| doi | title |
==================================================================================================
| "10.1038/nature05513" | "Comparison of the Hanbury Brown–Twiss effect for bosons and fermions" |
| "10.1038/221999a0" | "Physics: The Intermediate Boson" |
| "10.1038/313506b0" | "The nuts and bolts of bosons" |
| "10.1038/301287a0" | "The search for bosons: A golden year for the weak force" |
| "10.1038/424003a" | "Below-par performance hampers Fermilab quest for Higgs boson" |
--------------------------------------------------------------------------------------------------
Now let’s contrast this with a conventional record-based search, such as shown at left, to find the first five articles (referenced by DOI) with title containing the word ‘boson’ would use a query (here SRU/CQL, and CQL is bolded) such as:
?query=dc.title="boson"&maximumRecords=5&httpAccept=application/rss+xml
and would receive a set of result records (here RSS) like so:
...
<item rdf:about="http://dx.doi.org/10.1038/nature05513">
<title>Comparison of the Hanbury Brown–Twiss effect for bosons and fermions</title>
<link>http://dx.doi.org/10.1038/nature05513</link>
<dc:identifier>doi:10.1038/nature05513</dc:identifier>
<dc:title>Comparison of the Hanbury Brown–Twiss effect for bosons and fermions</dc:title>
...
</item>
<item rdf:about="http://dx.doi.org/10.1038/221999a0">
<title>Physics: The Intermediate Boson</title>
<link>http://dx.doi.org/10.1038/221999a0</link>
<dc:identifier>doi:10.1038/221999a0</dc:identifier>
<dc:title>Physics: The Intermediate Boson</dc:title>
...
</item>
...
Note also that there is an interesting halfway house as shown in the diagram, whereby a set of result records presenting a single RDF graph can be queried as its own (very) restricted triple store.
In general, because a triple store is so primitive and it can be queried alongside other triple stores the queries that can be put together can be highly complex and customized with arbitrary data. The result from such a query differs from a traditional ‘record’ where a fixed property set is bound together in a presentation. Such a result is user-determined as opposed to the server-determined nature of traditional result ‘records’.
I hope that this post has been able to show in some degree that although there are some obvious differences there is nevertheless a synergy between these two modes of searching: prêt-à-porter and tailored.




