PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
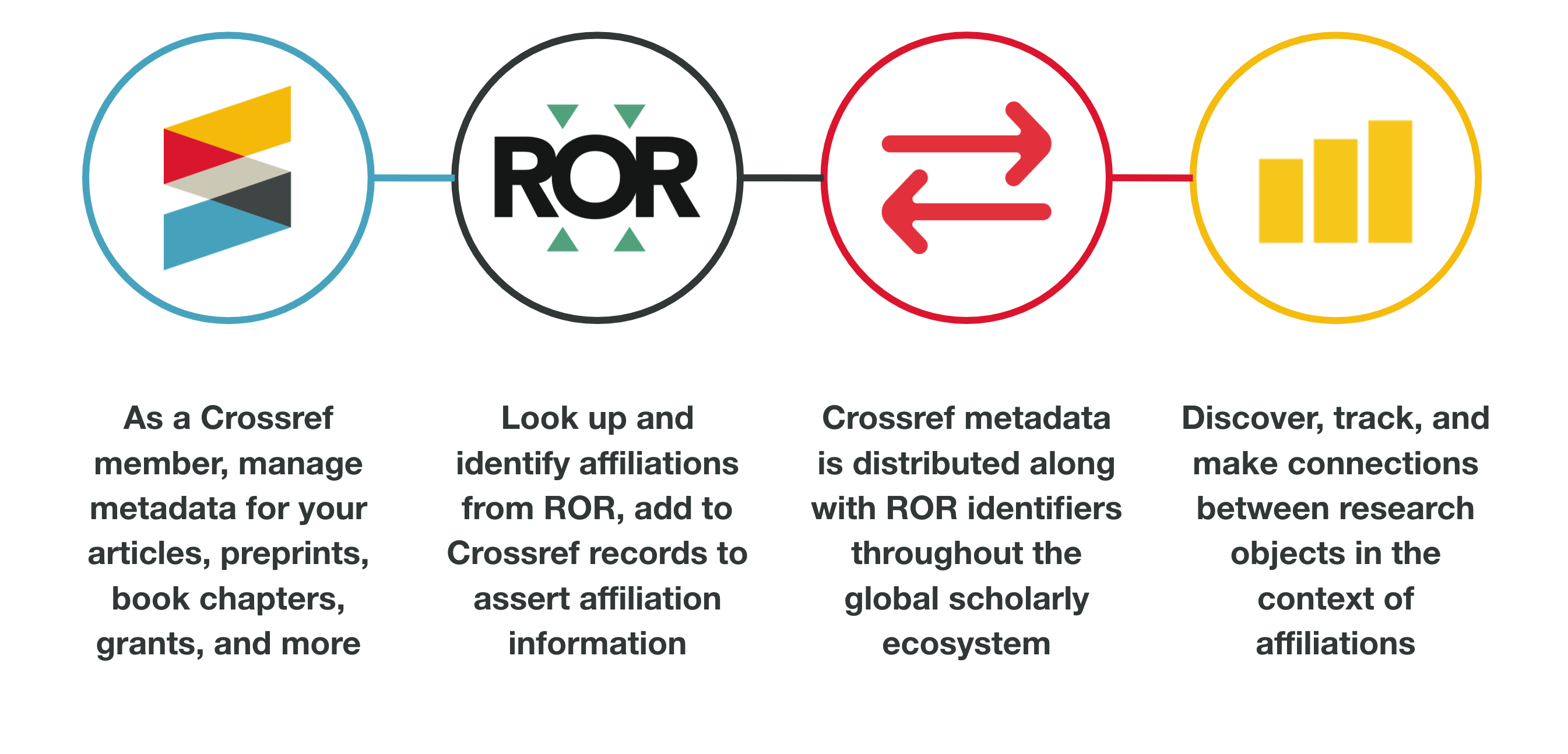
We’ve just added to our input schema the ability to include affiliation information using ROR identifiers. Members who register content using XML can now include ROR IDs, and we’ll add the capability to our manual content registration form, participation reports, and metadata retrieval APIs in the near future. And we are inviting members to a Crossref/ROR webinar on 29th September at 3pm UTC.
The background
We’ve been working on the Research Organization Registry (ROR) as a community initiative for the last few years. Along with the California Digital Library and DataCite, our staff has been involved in setting the strategy, planning governance and sustainability, developing technical infrastructure, hiring/loaning staff, and engaging with people in person and online. In our view, it’s the best current model of a collaborative initiative between like-minded open scholarly infrastructure (OSI) organisations.
Last year, Project Manager Maria Gould described the case for publishers adopting ROR and ROR was ranked the number one priority at our last in-person annual meeting. Now it’s time that Crossref’s services themselves took up the baton to meet the growing demand.
The inclusion of ROR in the Crossref metadata will help everyone in the scholarly ecosystem make critical connections more easily. For example, research institutions need to monitor and measure their output by the articles and other resources their researchers have produced. Journals need to know with which institutions authors are affiliated to determine eligibility for institutionally sponsored publishing agreements. Funders need to be able to discover and track the research and researchers they have supported. Academic librarians need to easily find all of the publications associated with their campus.
Earlier this month, GRID and ROR announced that after working together to seed the community-run Research Organization Registry, GRID would be retiring from public service and handing the proverbial torch over to ROR as the scholarly community’s reliable universal open identifier for affiliations. That means that our members who have been using GRID now need to consider their move to ROR and think about how they can add ROR IDs into the metadata that they manage and share through Crossref.
The plan
We’ve been able to include ROR IDs for our grant metadata schema as affiliation information for two years, since July 2019. And the Australia Research Data Commons (ARDC) was the first member to add ROR IDs to the Crossref system in 2020. In early July, we completed the work to accept ROR IDs for affiliation assertions for all other types of records with an affiliation or institution element, such as journal articles, book chapters, preprints, datasets, dissertations, and many more.
Next, we will commence the plans to support ROR in our other tools and services, such as Participation Reports. We’ll work on alignment with the Open Funder Registry and share our plans to collect the information via the new user interface we’re developing for registering and managing metadata. Open Journal Systems (OJS) already has a ROR Plugin, developed by the German National Library of Science and Technology (TIB). This supports the collection of ROR IDs and future releases of this plugin and the OJS DOI plugin will allow including ROR IDs in the metadata sent to Crossref, to support thousands of our members to share ROR IDs via their Crossref metadata.
We also aim to add ROR to our metadata retrieval options, including the REST API, which recently saw the start of an unblocking with our move to a more robust technical foundation.
The call for participation
Many Crossref publishers, funders, and service providers are already planning to integrate ROR with their systems, map their affiliation data to ROR, and include ROR in Crossref metadata. In addition to publishers and funders, libraries, repositories, and other stakeholders are developing support for ROR. For example, the Plan S Journal Checker tool uses ROR IDs to let people check whether a particular journal is compliant with an author’s funder and institutional open access policies. In addition, the ROR website shows a growing list of active and in-progress ROR integrations.
Crossref members registering research grants via Altum’s ProposalCentral system can already add ROR IDs. Now those registering articles, books, preprints, datasets, dissertations, and other research objects, can start including much clearer and all-important affiliation metadata as part of their content registration going forward. As with all newly-introduced metadata elements, we recommend adding ROR IDs from now and ongoing, but planning a distinct project to backfill older records. We know that more than 80% of records have been updated and enriched at least once with additional and cleaner metadata, so as members do this routinely, they can include ROR IDs alongside updating URLs, license or funding information, and other metadata.