Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
Some of you who have submitted content to us during the first two months of 2021 may have experienced content registration delays. We noticed; you did, too.
The time between us receiving XML from members, to the content being registered with us and the DOI resolving to the correct resolution URL, is usually a matter of minutes. Some submissions take longer - for example, book registrations with large reference lists, or very large files from larger publishers can take up to 24 to 48 hours to process.
However, in January and February 2021 we saw content registration delays of several days for all record types and all file sizes.
Tell me more
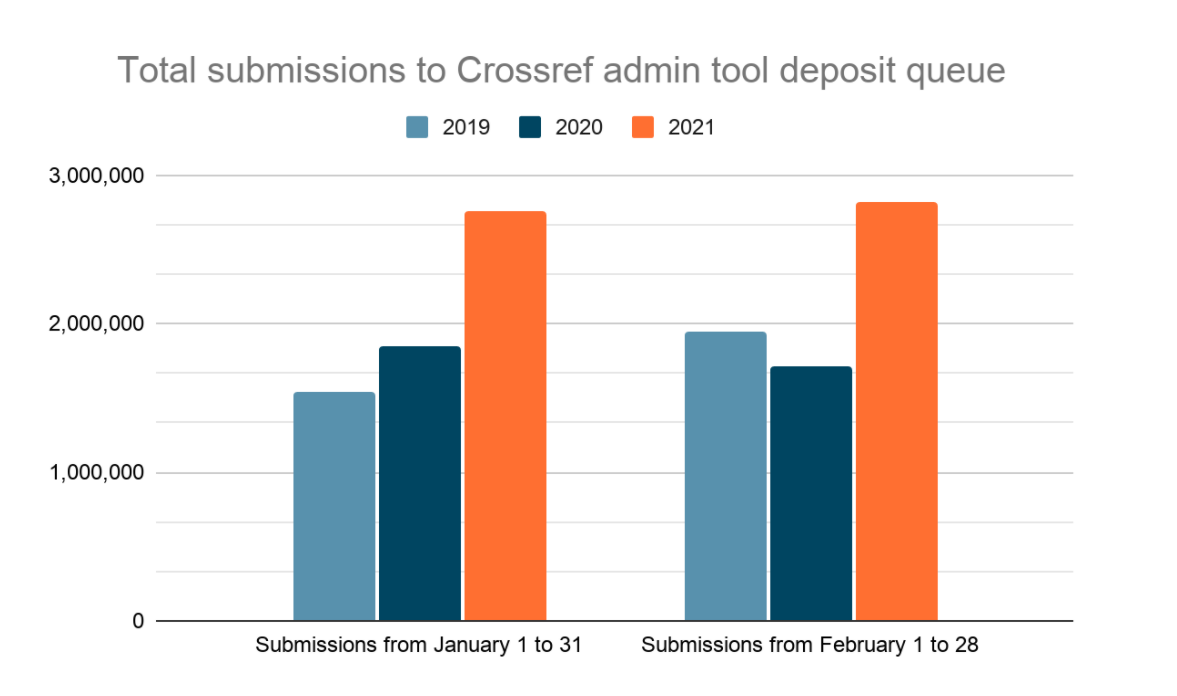
Januaries and Februaries are usually busy at Crossref. Journal ownership changes hands. Members migrate from one platform to another (and can need to update tens of thousands of their resolution URLs). And, many of you are registering your first issues, books, or conferences of the year. Others of you have heard the calls of The Initiative for Open Citations (I4OC) and The Initiative for Open Abstracts (I4OA) and are enriching your metadata accordingly (thank you!). Tickets into our support and membership colleagues peak for the year. But did we see significantly more submissions this year?
As you can see, we did see larger-than-normal numbers of submissions in the first two months of the year. For the entire month of January 2021, we received nearly 1 million more submissions into our admin tool deposit queue than we did in January 2020 (2,757,781 in 2021 versus 1,848,261 in 2020). Under normal circumstances, this would lead to an increase in our processing times, so there’s that to consider. But there was also something else at play this year. We desperately needed to upgrade our load balancer, and so we did. Unfortunately, unforeseen at the time, these upgrades caused hiccups in our deposit processing and slowed down submissions even further, building up the number of unprocessed submissions in the queue.
When we saw the impact this was having we suspended the load balancer work until things were stable again. We also increased the resources serving our queue to bring it back down to normal. To make sure we don’t face the same problem again, we have put in better tools to detect trends in queue usage- tools which, in turn, will allow us to anticipate problems in the queue instead of reacting to them after they’ve already occurred. And as a longer-term project, we are addressing two decades of technical debt and rearchitecting our system so that our entire system is much more efficient.
Gory technical details
As part of our effort to resolve our technical debt, we’re looking to transition more of our services to the cloud. To accomplish this, we first needed to upgrade our internal traffic handling capabilities to route things to their new locations better. This upgrade caused some unforeseen and hard to notice problems, like the queue being stalled. Since the queue still showed things in process, it wasn’t immediately apparent that things were not processing (normally the processing on the queue will clear a thread if a significant problem occurs).
We initially noticed a problem on 5 February and thought we had a fix in place on the 10th. But, we again realized on 16 February that the underlying problem had recurred, and we needed a closer investigation.
For many reasons it took us too much time to realize the connection, until people started complaining.
While our technical team worked on those load balancer upgrades, some of your submissions lingered for days in the deposit queue. In a few examples, larger submissions took over a week to complete processing. Total pending submissions began to push nearly 100,000, an unusually large backlog. We called an emergency meeting, paused all related work, and dedicated additional time and resources to processing all pending submissions. On 22 February, we completed working through the backlog of pending submissions and new submissions were being processed at normal levels. As we finish up this blog on 2 March, there are less than 3,000 pending submissions in the queue, the oldest of which has been there for less than three hours.
This brings us back to the entire rationale for what we are doing with the load balancer - which, ironically, was to move some services out of the data centre so that we could free-up resources and scale things more dynamically to match the ebbs and flows of your content registration.
But before we proceed, we’ll be looking at what happened. The bumps associated with upgrading ancient software were expected, so we were looking for side effects. We just didn’t look in the right place. And we should have detected that the queues had stalled well before people started to report it to us. A lot of our queue management is still manual. This means we are not adjusting it 24x7. So if something does come in when we are not around, it can exacerbate problems quickly.
What are we going to do about it?
In a word: much. We know that timely deposit processing is critical. We can and will do better.
First off, we have increased the number of concurrently processing threads dedicated to metadata uploads in our deposit queue from 20 to 25. That’s a permanent increase. A million more submissions in a month necessitates additional resources, but that’s only a short-term patch. And we were only able to make this change recently due to some index optimizations we implemented late last year.
One of the other things that we’ve immediately put into place is a better system for measuring trends in our queue usage so that we can, in turn, anticipate rather than react to surges in the queue. And, of course, the next step will be to automate this queue management.
All this is part of an overall, multi-year effort to address a boat-load of technical debt that we’ve accumulated over two decades. Our system was designed to handle a few million DOIs. It has been incrementally poked and prodded to deal with well over a hundred million. But it is suffering.
Anybody who is even semi-technically-aware might be wondering what all the fuss is about? Why can’t we fix this relatively easily? After all, 130 million records—though a significant milestone for Crossref—does not in any way qualify as “big data.” All our DOI records fit onto an average sized micro-SD card. There are open source toolchains that can manage data many, many times this size. We’ve occasionally used these tools to load and analyse all our DOI records on a desktop computer. And it has taken in just a few minutes (admittedly using a beefier-than-usual desktop computer). So how can a queue with just 100,000 items in it take so long to process?
Our scale problem isn’t so much about the number of records we process. It is about the 20 years of accumulated processing rules and services that we have in place. Much of it undocumented and the rationale for which has been lost over the decades. It is this complexity that slows us down.
And one of the challenges we face as we move to a new architecture is deciding which of these rules and services are “essential complexity” and which are not. For example, we have very complex rules for verifying that submissions contain a correct journal title. These rules involve a lot of text matching and, until they are successfully completed, they block the rest of the registration process.
But the workflow these rules are designed for is one that was developed before ISSNs were widely deposited and before we had our own, internal title identifiers for items that do not have an ISSN. And so a lot of this process is probably anachronistic. It is not clear which (if any) parts of it are still essential.
We have layers upon layers of these kinds of processing rules, many of which are mutually dependent and which are therefore not easily amenable to the kind of horizontal scaling that is the basis for modern, scalable data processing toolchains. All this means that, as part of moving to a new architecture, we also have to understand which rules and services we need to move over and which ones have outlived their usefulness. And we need to understand which remaining rules can be decoupled so that they can be run in parallel instead of in sequence.
Pro tip: Due to the current checks performed in our admin tool, for those of you submitting XML, the most efficient way to do so is by packaging the equivalent of a journal issue’s worth of content in each submission (i.e., ten to twelve content items - a 1 MB submission is our suggested file size when striving for efficient processing)
Which brings us conveniently back to queues. We did not react soon enough to the queue backing up. We can do much better at monitoring and managing our existing registration pipeline infrastructure. But we are not fooling ourselves into thinking this will deal with the systemic issue.
We recognize that, with current technology and tools, it is absurd that a queue of 100,000 items should take so long to process. It is also important that people know that we are addressing the root of the issues as well. And that we’re not succumbing to the now-legendary anti-pattern of trying to rewrite our system from scratch. Instead we are building a framework that will allow us to incrementally extract the essential complexity of our existing system and discard some of the anachronistic jetsam that has accumulated over the years.
Content Registration should typically take seconds. We wanted to let you know, that we know, and we are working on it.