5 minute read.The article nexus: linking publications to associated research outputs
Crossref began its service by linking publications to other publications via references. Today, this extends to relationships with associated entities. People (authors, reviewers, editors, other collaborators), funders, and research affiliations are important players in this story. Other metadata also figure prominently in it as well: references, licenses and access indicators, publication history (updates, revisions, corrections, retractions, publication dates), clinical trial and study information, etc. The list goes on.
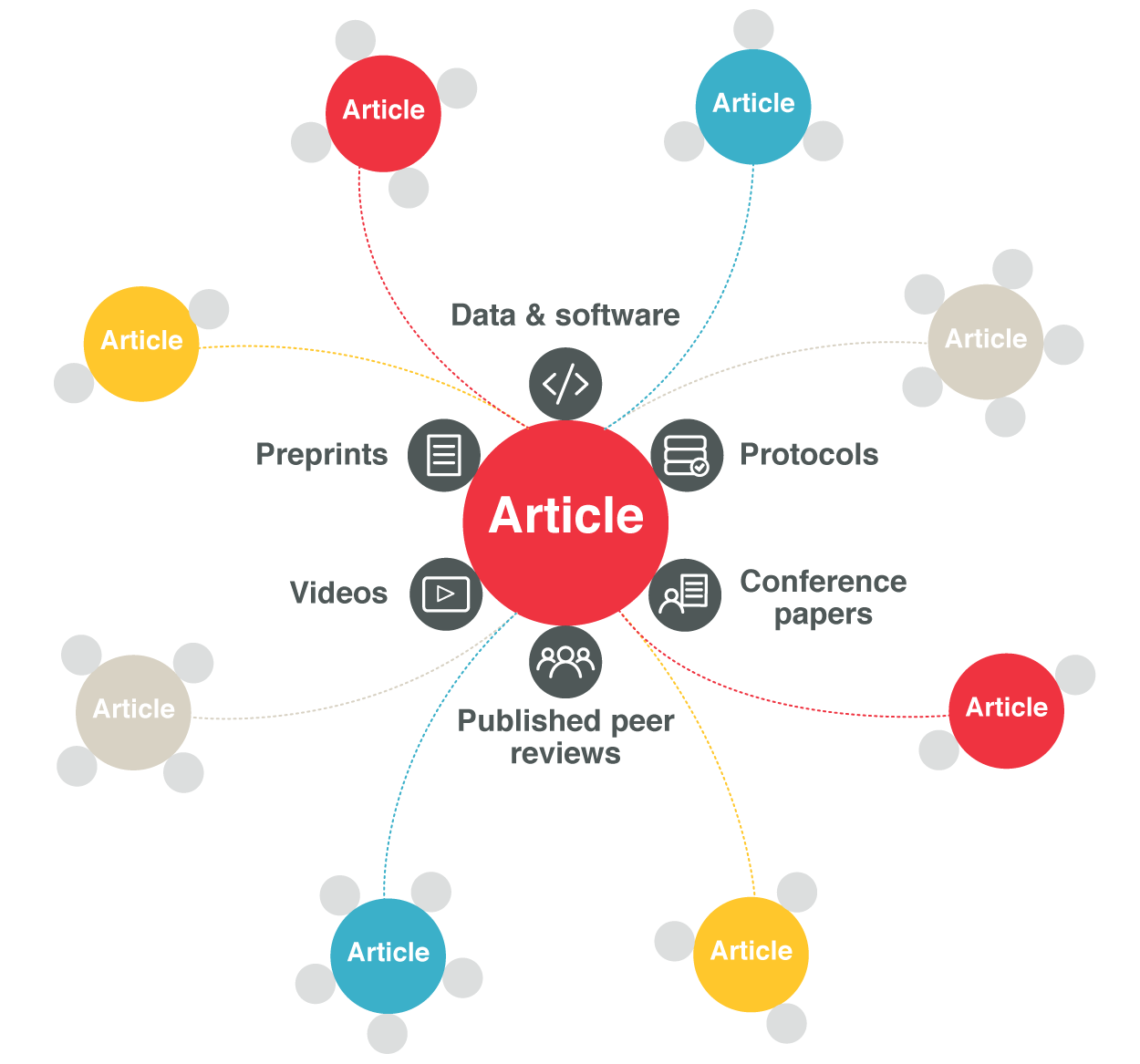
What is lesser known (and utilized) is that Crossref is increasingly linking publications to associated scholarly artifacts. At the bottom of it all, these links can help researchers better understand, reproduce, and build off of the results in the paper. But associated research objects can enormously bolster the research enterprise in many ways (e.g., discovery, reporting, evaluation, etc.).
With all the relationships declared across all 80+ million Crossref metadata records, Crossref creates a global metadata graph across subject areas and disciplines that can be used by all.
Research article nexus
As research increasingly goes digital, more research artifacts associated with the formal publication are stored or shared online. We see a plethora of materials closely connected to publications, including: versions, peer reviews, datasets generated or analysed in the research, software packages used in the analysis, protocols and related materials, preprints, conference posters, language translations, comments, etc. Occasionally, these resources are linked from the publication. But very rarely are these relationships made available beyond the publisher platform.
Crossref will make these relationships available to the broader research ecosystem. When publishers register content for a publication, they can identify the associated scholarly artifacts directly in the article metadata. Doing so not only groups digital objects together, but formally associates with the publication. Each link is a relationship and the sum of all these relationships constitutes a “research article nexus.”
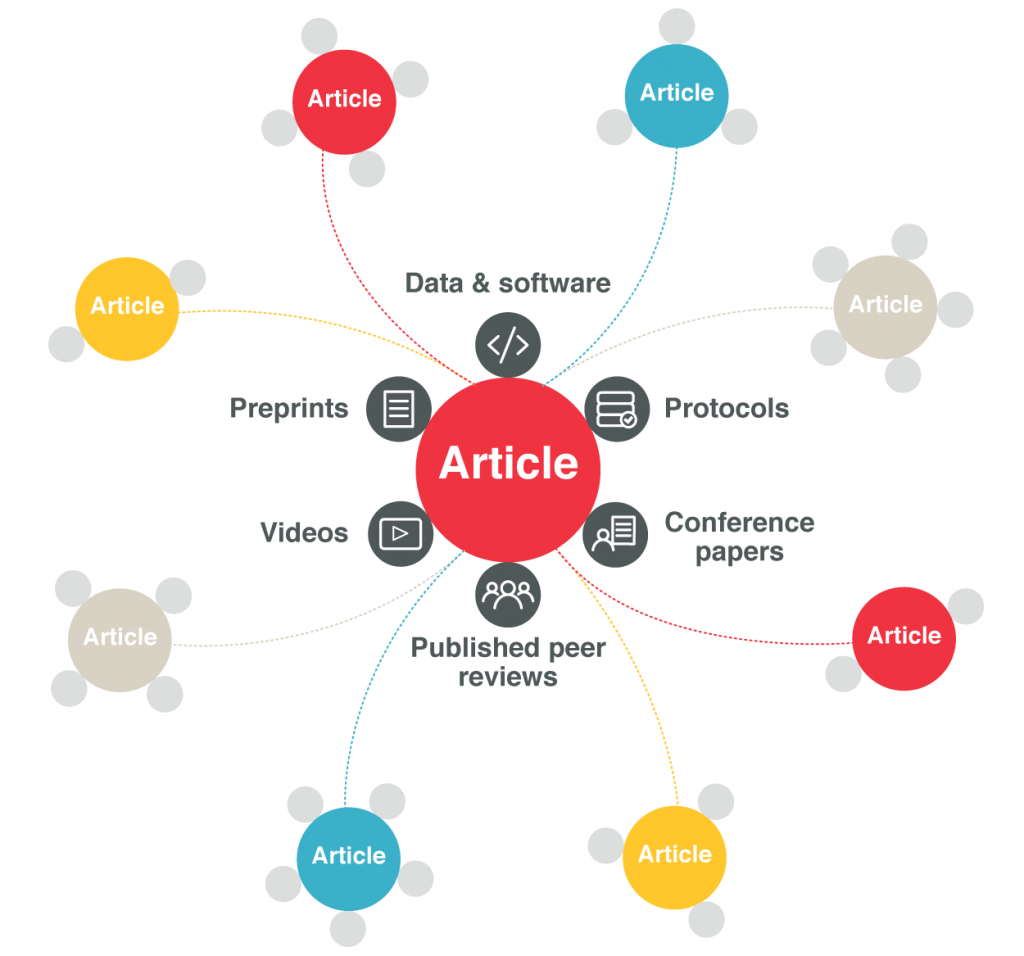
An assortment of connections already abound in the wild today. Examples include:
F1000Research article http://doi.org/10.12688/f1000research.2-198.v3 connected to initial version http://doi.org/10.12688/f1000research.2-198.v1 OECD publication http://dx.doi.org/10.1787/empl_outlook-2014-en and its German translation http://dx.doi.org/10.1787/empl_outlook-2014-dePeerJ article http://doi.org/10.7717/peerj.1135 and its peer review http://doi.org/10.7287/peerj.1135v0.1/reviews/3 eLife article http://doi.org/10.7554/eLife.09771 and its BioArXiv preprint http://doi.org/10.1101/018317PLOS ONE article http://doi.org/10.1371/journal.pone.0161541 with underlying data in Dryad http://doi.org/10.5061/dryad.d2vf8Frontiers article http://doi.org/10.3389/fevo.2015.00015 with a figshare http://doi.org/10.6084/m9.figshare.1305089.v1 videoJournal of Chemical Theory and Computation article http://doi.org/10.1021/ct400399x with software archived in Zenodo http://doi.org/10.5281/zenodo.60678Nature Biotech article http://doi.org/10.1038/nbt.3481 with a Protocols.io protocol http://doi.org/10.17504/protocols.io.dm649dTo date, almost all these relationships are not directly recorded in the article metadata (great job, PeerJ!). And as a result, they are more than likely “invisible” to the broader scholarly research ecosystem. Publishers can remedy these gaps by depositing associations when registering content with Crossref or updating the records after registration. That is how the article nexus is formed.
(Associated datasets can also be identified in the reference list as per Joint Declaration of Data Citation Principles as with the FORCE11 Software Citation Principles. Stay tuned next week for a follow up blog post on Crossref’s support for publisher data and software citations through its metadata.)
The mechanism of declaring these relationships is straightforward and a longstanding part of the standard deposit process. For each associated research object, simply provide the identifier and identifier type for the object, an optional description of it, as well as name the relationship into the metadata record. For the latter, Crossref and DataCite share a closed list of relationship types, which ensures interoperability between mappings. See Crossref technical documentation for more details.
We maintain a list of the recommended relation types for a host of associated research objects to promote standardization across publishers. If you have relationships not specified, please contact us at feedback@crossref.org to identify a suitable one considered best practice. Common adoption of relation types will make relationship metadata useful to tool builders and systems. For example, programmatic queries on supporting materials require proper tagging of their respective relationship types.
This approach is highly extensible and accommodates the introduction of new research object forms as they emerge. It also supports associated research objects regardless of identifier type. When an associated entity has a DOI, however, we can validate the relationship during metadata processing as well as provide a more reliable representation of the article nexus.
Article nexus: a far richer scholarly map
Bibliographic metadata is like a ship’s manifest that catalogs each item of cargo in a ship’s hold - crate, drum, sack, and barrel. It identifies the components that have an internal relation to the publication (contributor, funder, article update, license, etc.), each of which are well-understood points on the scholarly map. But when we integrate the article nexus into the graph, new territories become visible - not isolated islands, but places with highways connecting them to addresses already known.
When a publication has its relationships clearly identified, the connections both go out as well as lead back to it. The more connections, the more visibility on the scholarly map, as the Art of Cartography goes. Numerous systems tap into this map: publishing, funders, research institutions, research councils, indexers & repositories, indexers, research information systems, lab & diagnostics systems, reference management and literature discovery, other PID suppliers. So publishers, you can provide the fullest value to your own publishing operation, your authors, their research communities, and the overall research enterprise by ensuring that all publications are fully linked both inside and out.
Further reading
- Oct 12, 2020 – EASE Council Post: Rachael Lammey on the Research Nexus
- May 26, 2026 – Two billion citation links in Crossref help research travel further
- Mar 23, 2023 – Start citing data now. Not later
- Jul 20, 2026 – Position paper: persistent identifiers in research infrastructure policy
- Jul 20, 2026 – Why PID strategies need more than PIDs: our first position paper
- Jul 9, 2026 – Schema 5.5 now available: adding CRediT, new record types for blogs and posters, and more
- Jun 18, 2026 – Building better connections: the story of Crossref's metadata development
- Mar 31, 2026 – Voices from Crossref Metadata Sprint in São Paulo