PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
In our previous instalments of the blog series about matching (see part 1 and part 2), we explained what metadata matching is, why it is important and described its basic terminology. In this entry, we will discuss a few common beliefs about metadata matching that are often encountered when interacting with users, developers, integrators, and other stakeholders. Spoiler alert: we are calling them myths because these beliefs are not true! Read on to learn why.
If you have stuck with us this far in our series, hopefully, you are at least a bit excited about the possibility of creating new relationships between the works, authors, institutions, preprints, datasets, and myriad other objects in our existing scholarly metadata. Who would not want all of these to be better connected?
We have to pause for a moment and be honest with you: metadata matching is a complex problem, and doing it correctly requires significant effort. What is worse, even if we do everything right, our matching won’t be perfect. This may be counterintuitive. Perhaps you’ve heard that matching is not a hard problem, or have encountered people surprised that a matching strategy returned a wrong or incomplete answer. Sometimes, it is obvious to a person from looking at some specific example that a match should (or should not) have been made, so they naturally assume that a change to account for this has to be simple.
Misconceptions like these can be problematic. They create confusion around matching, drive users’ expectations to unreasonable levels, and make people drastically underestimate the effort needed to build and integrate matching strategies. So let’s dive right in and debunk a few common myths about metadata matching.
Myth #1: A metadata matching strategy should be 100% correct
Anyone who has built or supported a matching strategy has likely encountered the following belief: it is possible to develop a perfect strategy, meaning one that always returns the correct results, no matter the inputs. The unfortunate truth is that while one’s aim should always be to design matching strategies that return correct results, once we move beyond the simplest class of problems or artificially clean data, no strategy can achieve this outcome. In thinking through why this is the case, some inherent constraints become obvious:
The inputs to matching are often strings in human-readable formats, which can vary wildly in their structure, order and completeness. Since they’re intended to be parsed by people, instead of machines, they’re inherently lossy and frequently unstructured, anticipating that a person can infer from the source context what is being referenced. Matching strategies, although built to make sense of unstructured data, unfortunately, don’t have the luxury of this flexibility. A strategy has to account for translating a messy, partial, or inconsistent input into a correct and structured match.
Consider, for example, the following inputs to an affiliation matching strategy:
“Department of Radiology, St. Mary’s Hospital, London W2 1NY, UK”
“Saint Mary’s Hospital, Manchester University NHS Foundation Trust”
“St. Mary’s Medical Center, San Francisco, CA”
“St Mary’s Hosp., Dublin”
“St Mary’s Hospital Imperial College Healthcare NHS Trust”
“聖マリア病院”
In order to correctly identify the organisations mentioned here, the matching strategy must be able to distinguish between different ways of representing the same institution, disambiguate multiple institutions that have similar names, and handle variant forms for the parts of each name (Saint/St./St), identify the same name in different languages (“聖マリア病院” is Japanese for “St. Mary’s Hospital”), and make assumptions about partial or ambiguous locations translating to more precise references. While a person reviewing each of these strings might be able to accomplish these tasks, even here there are some challenges. Does “St Mary’s Hosp., Dublin” refer to the hospital in Ireland or a separate hospital in one of the many cities that share this name? Should we presume that because “聖マリア病院” is in Japanese, this refers to a hospital in Japan? Would someone, by default, be aware that St. Mary’s Hospital in London is part of the Imperial College Healthcare NHS Trust, such that inputs one and five refer to the same organisation?
An additional challenge lies in the quality of the data, which in the context of matching, encompasses both the input and the dataset being matched against. In real world circumstances, no dataset is fully accurate, complete, or current and certainly not all three. As a result, there will always be functionally random differences between inputs to the strategy and the entities to be matched. A theoretically perfect matching strategy would thus need to distinguish between inconsequential discrepancies resulting from gaps, errors, and variable forms of reference and actual, meaningful differences indicating an incorrect match. As one might imagine, this would require near total knowledge of the meaning and context for all inputs and outputs, a nigh-on impossible task for any person or system!
As a consequence, no metadata matching strategy will ever be perfect. It is unreasonable for us to expect them to be. This does not mean, of course, that all strategies are equally flawed or destined to forever return middling results. Some are better than others and we can improve them over time. Which brings us to the next myth:
Myth #2: It is always a good idea to adapt the matching strategy to a specific input
Matching strategies are not static. They can - and should - be improved. There is, however, a deceptive trap that one can fall into when attempting to improve a matching strategy. Whenever we encounter an incorrect or missing result for a specific input, we treat this problem like a software bug and try to adapt the strategy to work better for it, without considering all other cases.
The more complicated reality is that the quality of matching results is controlled through a complex set of trade-offs between precision and recall that determine the kind and number of relationships created between items:
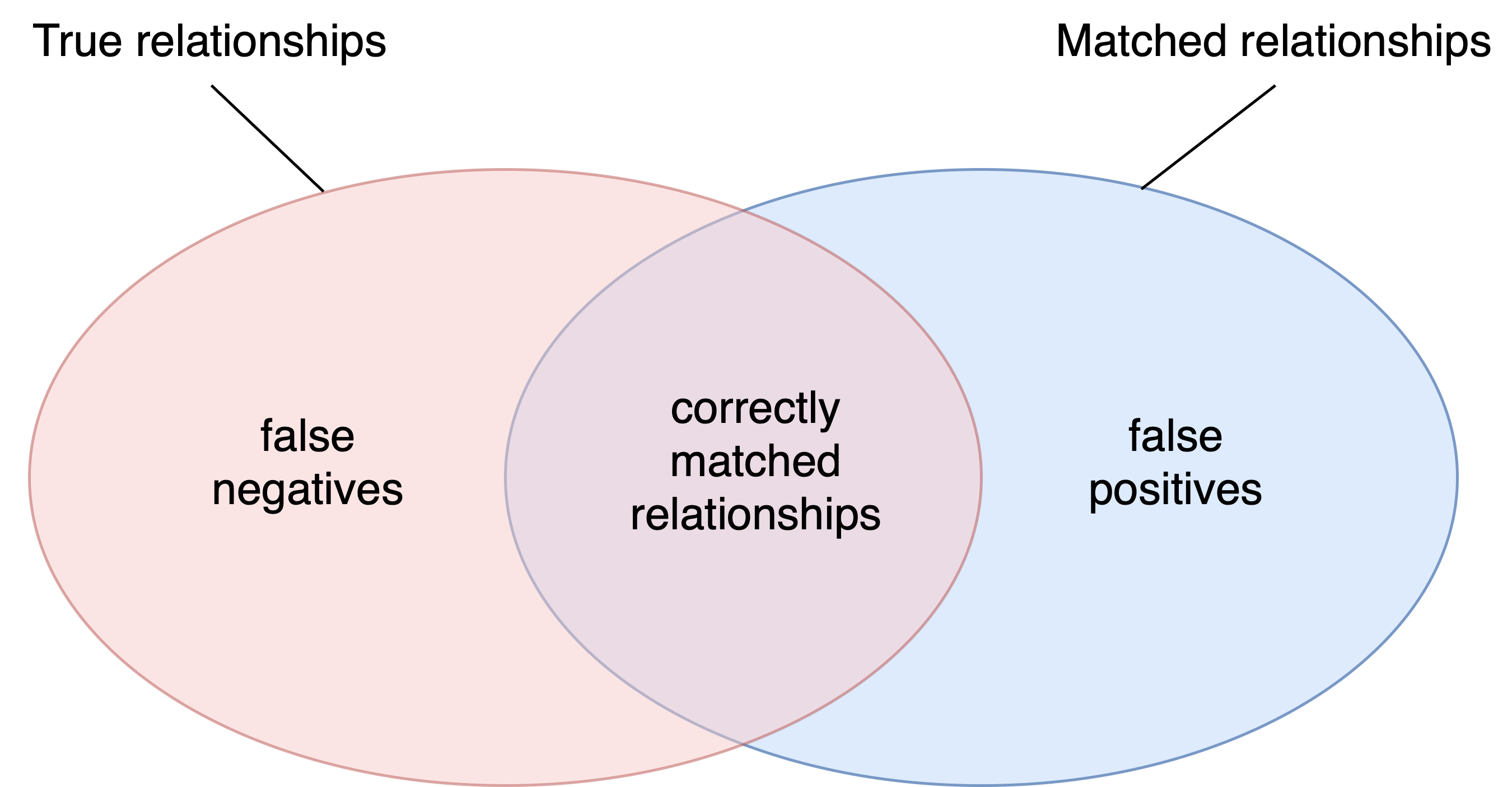
Precision is calculated as the number of correctly matched relationships resulting from a strategy, divided by the total number of matched relationships. It can also be interpreted as the probability that a match is correct. Low precision indicates a high rate of false positives, which are incorrect relationships created by the strategy.
Recall is calculated as the number of correctly matched relationships resulting from a strategy, divided by the number of true (expected) relationships. It can also be interpreted as the probability that a true (correct) relationship will be created by the strategy. Low recall means a high rate of false negatives, which are relationships that should have been created by the strategy but were not made.
The diagram depicts false negatives and false positives. The ideal outcome would be that the ellipses are identical, matched relationships are exactly the same as true relationships, and there are no false negatives or false positives. In practice, we try to make the intersection as big as possible.
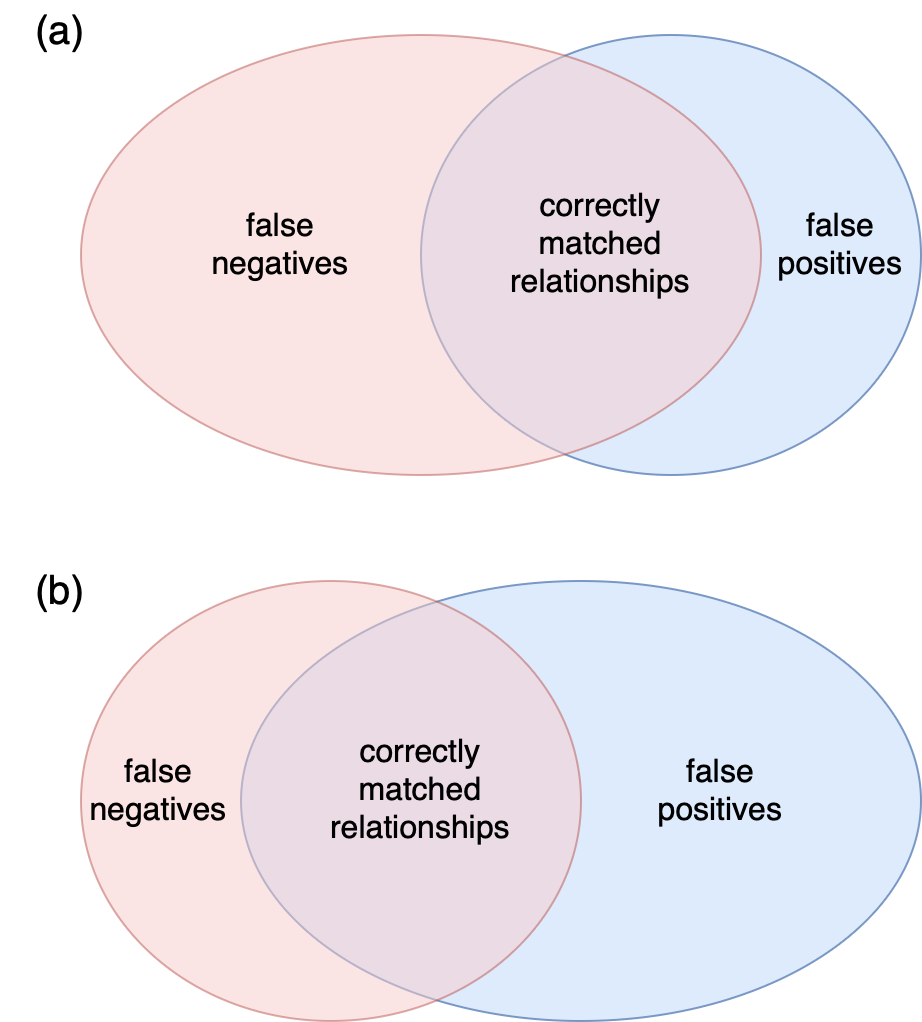
The tradeoff between precision and recall roughly means that modifying the strategy to improve recall will decrease precision, and vice versa.
Imagine, for example, we received a report about a relationship that was missed by matching because of a partial, noisy, or ambiguous input. We might be tempted to resolve this issue by relaxing our matching criteria. Unfortunately, this will have a cost of a higher overall rate of false positive matches.
Conversely, if we encounter a case where the matching has returned an incorrect match, we might attempt to make the matching strategy stricter to avoid this result. We should remember, however, that this may have the consequence of causing the strategy to skip many perfectly valid matches.
The tradeoff between precision and recall. (a) A strict strategy prioritises precision over recall resulting in more false negatives. (b) A relaxed strategy prioritises recall over precision resulting in more false positives.
Striking this balance becomes even more difficult when attempting to address multiple issues at once, or considering constraints like the time and resources consumed by each aspect of the strategy. Each choice can compound the individual effects in unanticipated and expensive ways. The aim of matching ultimately then can’t be to achieve perfect results for every single case. Fixing one particular situation might not be desirable, as it can result in breaking multiple other cases. Instead, we have to find a locally optimal balance that optimises the strategy’s utility, relative to these inherent limitations. This means accepting some level of imperfection as not just inevitable, but necessary for implementing a workable strategy. When you consider all this, you might conclude that…
Myth #3: We shouldn’t do large-scale, unsupervised matching
Imperfect matching strategies, when applied automatically to real-world large datasets, might:
Fail to discover some relationships (false negatives), an outcome that may not be terribly problematic. In the worst case scenario, we have wasted a great deal of effort developing matching strategies that do not improve our metadata.
Create incorrect relationships between items (false positives), what seems like a potentially larger problem, where we have added incorrect relationships to the metadata.
Many have the instinct to avoid false positives at any cost, even if this means missing many additional correct relationships at the same time. They might come to the conclusion that if we cannot have 100% precision (see our previous myth), we simply should not allow matching strategies to act in an automated, unsupervised way on large datasets. While there might be circumstances where this belief is rational, in the context of the scholarly record, this notion is seriously flawed.
First, if you are dealing with any medium to large-sized dataset, it almost certainly contains errors, even before you apply any automated processing to it. Even if data is submitted and curated by users, they can still make mistakes, and might themselves be using automated tools for extracting the data from other sources, without your knowledge. It is thus not entirely obvious that applying an (imperfect) matching strategy to create more relationships would actually make the data quality worse.
Second, while we cannot eliminate all matching errors, we can place a high priority on precision when developing strategies, with the aim of keeping the number of incorrectly matched results as low as possible. We can also make use of additional mechanisms to easily correct for incorrectly matched results, for example doing so manually, in response to error reports.
Finally, the results of matching should always contain provenance information to distinguish them from those that have been manually curated. This way, the users can make their own decisions about whether to use and trust the matching results, relative to their use case.
By applying those additional checks, we can minimise the negative effects of incorrect matching, while at the same time reap the benefits of filling gaps in the scholarly record.
Myth #4: We can only ever guess at the accuracy of our matching results
In attempting to determine the correctness of our matching, we immediately encounter a number of inherent limitations. The sheer amount of entries in many datasets prevents a thorough, manual validation of the results, but if instead, we use too few or specific items as our benchmarks, these are unlikely to be representative of overall performance. The unpredictable nature of future data adds another wrinkle: will our matching always be as successful as when we first benchmarked it or will its performance degrade relative to some change in the data?
With so many unknowns, are we then doomed? No! We have rigorous and scientific tools at our disposal that can help us estimate how accurate our matching will be. How do we use them? Well, that is a big and fairly technical topic, so we will leave you with this little cliffhanger. See you in the next post!