PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
As the linking hub for scholarly content, it’s our job to tame URLs and put in their place something better. Why? Most URLs suffer from link rot and can be created, deleted or changed at any time. And that’s a problem if you’re trying to cite them.
Thus the Crossref DOI was born: an Identifier which is Persistent, which means that it’s designed to live forever (or, as Geoff Bilder rather more prosaically puts it, as long as we do), and also Resolvable, which means that you can click on it. A DOI is a URL, but it’s imbued with special properties. I say special, not magical, because all of the things that make Crossref DOIs what they are, are obtained through agreements and common standards rather than any kind of magic.
As part of the development of Crossref Event Data I’ve been doing some research about the relationship between DOIs and URLs. It’s a problem we have to solve in order to make Event Data work, but it’s a much broader and more interesting story, and the results have wide applicability. I’ll be telling this story at PIDapalooza. If you’re interested in Persistent Identifiers you should go and registration is open, though hurry, as it’s next week and in Rejkjavik, Iceland!
This is also a story in progress. As I write not all of the data is in, and we can be certain that it will evolve in ways we have no idea about. It’s also quite long but I’ll do my best to disqualify it from the bedtime reading list.
Full circle
Crossref was established just over fifteen years ago with the purpose of forming the linking hub between publishers. Our job was — and still is — to register content for publishers and then continue to work with them to ensure their DOIs always point to the right location of the content. To do this we need to do one main thing: send people in the right direction when they click on a DOI, and know which direction to point them in.
Today, linking is still an important part of what Crossref does, but we do a huge amount more. One of the new things we’re working on is Crossref Event Data. It’s a service for tracking how and where people use scholarly content (such as articles) across the web and social media. Early research suggested that if we limited ourselves to just looking for DOIs we wouldn’t find much. Instead we broadened our aims a little: rather than looking for mentions of registered content exclusively via their DOIs, we look for them via the most suitable mechanism. In most cases this means the actual URL of the Item. So we have come full circle: we started linking DOIs to URLs. Now we’re trying to link URLs back to DOIs.
Which URL are we talking about here? The Crossref Guidelines say:
DOI-routed reference links enabled by Crossref must resolve to a response page containing no less than complete bibliographic information about the target content …
This is what’s referred to as the Landing Page. Every Landing Page has a URL. Usually when you want to read information about an Article, it’s the Landing Page that you’re looking at. I should also say at this point that when I say Article I mean any item of Crossref Registered Content with a DOI. So the same applies to books, chapters, conference proceedings etc. But as most items are Articles, I’ll stick with that for now.
I’m going to make some assumptions. Unfortunately, and I don’t want to spoil the surprise here, they all turn out to be false. They’re all reasonable assumptions, though, and you would be forgiven for thinking, or at least wishing, that they were true.
So suspend your disbelief and follow me down the rabbit-hole…
Assumption 1: A DOI points directly to a Landing Page URL
When you click on a DOI you are taken to the Article Landing Page. It seems like a perfectly valid assumption to think that you are taken directly there.
The DOI system is essentially a big lookup table. In the first column is the DOI and in the second column is the URL. Publishers request that we register each item’s DOI and supply us with the URL it should point to. We work with CNRI and the International DOI Foundation to keep the system running and it means that when you, the reader at home, click on a DOI, you end up on the article’s Landing Page.
It would be very convenient if our assumption were true. If we wanted to turn a URL back into an article page, we could just swap the two columns and find the DOI by looking up the URL.
It turns out that it’s not quite so simple.
The Landing Page is under control of the publisher, as is the URL that they supply us with. They don’t need to supply us with the final landing page URL, only with one that leads to the landing page.
HTTP redirects
When you request a URL, either by typing it into your browser or by clicking on a link, your browser contacts the server and gets a reply. That reply can be “200 OK, here’s your page”, “303, look over there” or the dreaded “404, I can’t find it”. Other HTTP response codes are available, including well-known classics such as 201, 500 and 418.
If it’s a 303, your browser will follow the redirect URL. The response that comes back from that redirect could be another 303. You could end up following a whole chain of redirects. You wouldn’t notice anything, except having to wait an extra few milliseconds.
Extraordinary diversity
Crossref was created by a group of publishers who needed a way to link between articles. It was an ambitious goal: create a central system with which any publisher can integrate their own systems; one that allows linking to any article no matter who published it. Today we have over 5,000 members and counting, all contributing to our metadata engine. And up to 2 million DOIs are resolved every day, by all kinds of people and systems. Our wide range of members means a wide range of systems with a wide range of designs.
This brings an extraordinary diversity of behavior. If we want to make observations about DOIs we can’t just take a random sample of the over 80 million. Instead, we need to take a sample of DOIs per Publisher System. Even taking a sample per publisher might not do the job because some publishers run a variety of systems.
Experiment 1: Does Crossref know all Landing Pages?
By NASA / Paul Riedel (Great Images in NASA: Home - info - pic) [Public domain], via Wikimedia Commons
Hypothesis: Crossref knows the Landing Page URL for all DOIs.
For a sample of Items, we can follow the DOI link all the way through to the Landing Page, following any redirects, then compare the final Landing Page URL to the one that Crossref knows about. If there are extra redirects, that means that the one we have on file isn’t the final one.
We need to tighten up the terminology at this stage:
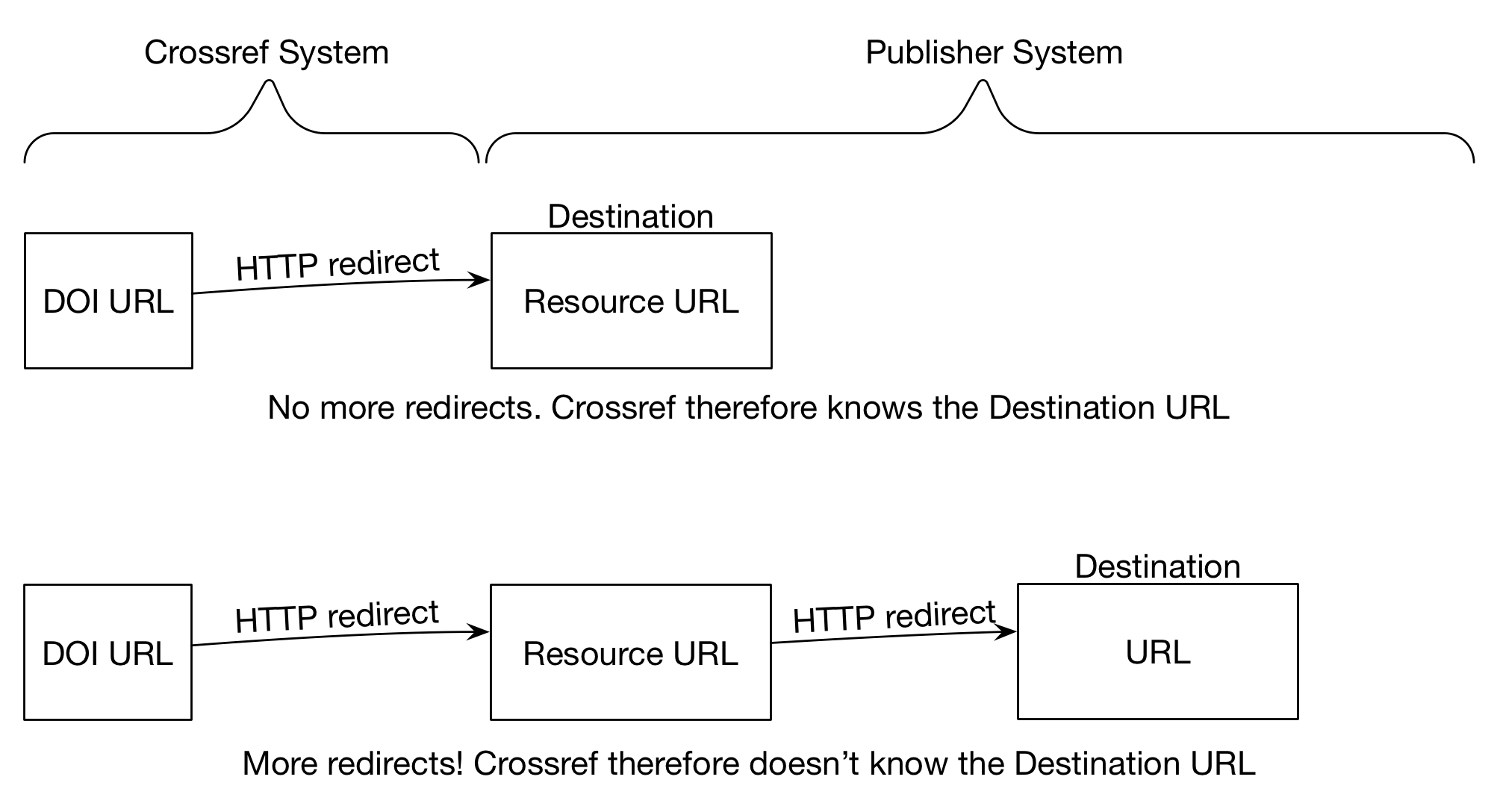
Resource URL - The URL that Crossref has on file (stored in our system). This is where the browser is initially redirected.
Destination URL - The URL that we end up at if we follow all the redirects.
Article Landing Page - The page that represents the item. If everything works, this should be the same as the Destination URL.
The reason we’re talking about the Destination URL as distinct from the Article Landing Page when they should be the same thing will become clear later. Consider yourself foreshadowed.
So let’s re-word our hypothesis:
Hypothesis: The Destination URL is the same as the Resource URL.
Method: A sample of DOIs was taken (most items updated in 2016, all from 2009 or earlier). The Resource URL was obtained for all of them. The DOIs were split by the domain name of the Resource URL (to give a good coverage of all Publisher systems). A sample of Resource URLs was followed per domain, at least 200 (or fewer if that exceeds the number of DOIs available). Where there were HTTP redirects they were followed.
Observations:
Number of Items sampled Destination URL: 253,381
Number where Resource URL = Destination URL: 46,995 or 19.96%
Conclusion: Not all Resource URLs are the same as the Destination URL by a long shot. Crossref does not automatically know every landing page URL.
Now we know the truth about our first assumption: DOIs don’t point directly to Landing Pages. If we want to reverse Landing Pages back into DOIs, we’re going to need to go a bit deeper…
Interlude
But first, an interlude with some information about publishers, owners, and systems, because now seems like the right time to do it.
Assumption 2: You can tell the publisher of a DOI by looking at its prefix
Whilst this turns out to be true most of the time, it’s not true for all Items, which makes it a dangerous assumption to make.
It is true that every publisher is given a prefix. They can then register DOIs with this prefix. It is also true that Items can be transferred between publishers. Because DOIs are persistent, the prefix in the DOI doesn’t change. So you might find a DOI that belongs to a publisher that has an unexpected prefix. Publishers can also be bought and sold, merged and split, which means that whilst most publishers have a single prefix, some, like Elsevier, have several. Take the case of Elsevier, who has 26 at the time of writing (you can see this in Elsevier’s entry in the Crossref Metadata API).
Every Item has an ‘owner prefix’ in addition to the prefix in the DOI. The owner prefix is the same as the DOI prefix when the Item is created, but over time, as articles are transferred, that can change to indicate that it is owned by another publisher.
Every Item has a DOI, and every DOI has a prefix. But every Item also has an Owner Prefix (you can check this in the Metadata API in the ‘prefix’ field).
So Assumption 2 has been laid to rest. The only thing you can tell from looking at a DOI is that it is, in fact, a DOI (you can tell by the “10.” index code).
Why do we care about identifying publishers anyway?
A Fair Test
We fundamentally want to conduct a fair test. The reason we can’t just take a random sample from the set of all DOIs is that there are lots of members who all do things slightly differently. Therefore we need to take a sample per publisher ‘system’. The word ‘system’ is a bit fuzzy, but my assumption is that two articles in the same system will behave the same way so we can treat them the same.
We also know that each Crossref member may be running more than one system, or a mixture. Therefore just looking at the owner of a DOI may not give accurate results if we want to conduct a survey of all the systems out there.
There’s no perfect answer, but the approach I’m taking is to look at the domain name of the Resource URL. We often find lots of subdomains for the same publisher, for example, “psw.sagepub.com”, “pol.sagepub.com”, “psx.sagepub.com” and “bpi.sagepub.com”. It’s clear that these are all operated by Sage, but they might or might not all be running on different ‘systems’.
Therefore I’m splitting DOIs up into groups based on the domain of their Resource URL. It may turn out that some publishers use a single system running on many domains, or it may turn out that some publishers use a different system for each domain they use. The key point is to find a sampling technique that broadly works, and that allows us to explore and differentiate, as keenly as possible, the variety of systems and behaviours.
Why all the redirects?
Curious minds might at this stage be wondering about all these extra redirects. Surely it’s extra stuff for the publisher to maintain. Why don’t they just point the DOI directly to the landing page?
The answer must be prefaced by repeating that there is a huge number of publishers, running a variety of systems, so we’ll never be able to completely answer that. But some humble suggestions:
They might want to be able to change the URLs of the Landing Pages. It may be easier to update their internal systems than send the update to Crossref, especially in bulk.
Different parts of their technology stack may be owned by different parts of the company, or outsourced. It’s easier to define internal boundaries than to co-ordinate business units and cross an external one.
A publisher may run a mix of different technology. As part of their systems integration process, they set up a redirect server to make everything work together.
A publisher assigns DOIs to articles but also has their own internal IDs. They maintain their own DOI-to-internal-ID lookup service.
Internal DOI resolvers
That last point is an interesting one. The DOI system is the canonical “DOI-to-URL resolver”. That doesn’t prevent publishers from running their own. Indeed, many do.
To take a real example of PLoS, an Open Access publisher who registers lots of content with Crossref. To follow one of their DOIs we go on the following journey of redirects:
Given that the last step uses a DOI, this suggests that they use the DOI as an internal identifier. All those redirects were for some purpose, but they weren’t mapping a DOI to an internal ID. This is therefore not an internal DOI resolver.
In this case we see a mapping from the DOI 10.1001/archsurg.142.7.595 to the ID 487551.
Can we define a heuristic for this pattern? Yes, but not a perfect one. My test is this:
Does the resource URL contain the DOI?
If so, does it redirect to a different destination URL?
If so, does the destination URL not contain the DOI?
The last step is important, because we can’t really say the publisher is running a DOI resolver if they use the DOI all the way through.
It’s not perfect and no doubt has false negatives. But we’re just trying to find out whether some publishers run their own DOI resolver systems.
Experiment 2: Determine how widespread use of internal DOI resolvers is:
Hypothesis: Some publishers run their own DOI resolvers.
Method: A number of Destination URLs were sampled per Resource URL Domain. If the Resource URL contains the DOI but the Destination URL doesn’t, that’s marked as a Publisher DOI resolver redirect.
Observations:
Number of Items sampled with Resource URL and Destination URL: 253,381
Number of Items that appear to be DOI resolvers: 166,352 = 65.6%
Conclusions: Some publishers run their own DOI resolvers.
This isn’t of much practical use, but it’s interesting to know, and hints at the way the Crossref system and DOIs are integrated with Publishers’ systems. Now that we’ve got a little insight into the reasons that publishers might run their own DOI resolvers, we can resume our journey of assumptions.
Assumption 3: We can find the Landing Page for Every DOI
Now we know that we can’t just use the lookup table in reverse, but have to follow the links all the way to their destination. Does this approach actually work?
This is a pretty big question and we need to be clear about what we mean by ‘every’ DOI. The set of DOIs I’m using (although I’m using a subset) is “all DOIs in our Metadata API that are found in doi.org”.
What is a DOI? Geoff Bilder went over it in the DOI-like-strings blog post earlier this year. The definition I’m working to here is:
A DOI is an identifier for an item of content registered in the DOI system.
That is, if you resolve the DOI on https://doi.org/ and it’s recognised, that counts as a DOI. I’m working from the set of DOIs found in the Crossref system as I’m primarily concerned with Crossref DOIs. However, we collaborate closely with DataCite.
Back to our assumption: “we can find the Landing Page for every DOI”. The answer is that we can, most of the time. But because Crossref Event Data has to work as well as possible, and therefore work with as many DOIs as possible, we have to scour all the nooks and crannies.
Assumption 4: Every DOI points somewhere unique
Stop me when you find the deliberate mistake:
Every Item corresponds to a different thing
Every Item has a single DOI
Every DOI is different
Every DOI points to a landing page
Therefore every DOI points to a different landing page
Two things immediately suggest themselves:
“Every item has a single DOI” should be true, but it isn’t. We find that sometimes two DOIs are assigned to the same item. This can happen when publications change hands between publishers, or when mistakes are made, or for a variety of other reasons. We also find that in some cases Publishers registered a DOI for the metadata and one for the article abstract. The two DOIs point to the same place. In some cases where there were two DOIs registered for the same thing we create an Alias.
When we alias a DOI we simply say “this DOI should actually point to this one”. Both DOIs still exist, and both still point to the ‘correct’ thing, it’s just that they both point to the same place. If we have two DOIs pointing to the same place, then there isn’t a one-to-one mapping, and Assumption 4 is incorrect.
Experiment 4: Aliased DOIs
Hypothesis: There isn’t a one-to-one mapping between DOIs and URLs because some DOIs are aliased to others.
Method: We collected a sample of Resource URLs from the DOI API. We count how many DOIs are classified as Aliases in the DOI system.
Observations:
From a sample of 11,227,458 DOIs
14,566 are aliased to others, or 0.129%
Conclusion: There aren’t many aliases. But there are some, and we should be aware of them.
Experiment 5: Duplicate Resource URLs
Hypothesis: There isn’t a one-to-one mapping between DOIs and URLs because some DOIs have duplicate Resource URLs.
Method: A sample of Resource URLs was collected from the DOI API. We counted how many DOIs have Resource URLs that aren’t unique. We subtract the number of deleted DOIs because all deleted DOIs have the same resource URL.
Observations:
From a sample size of 11,227,458
a total of 112,195 have duplicate resource URLs, or 0.99%
of these duplicates, 77,896 have the ‘deleted’ URL
leaving 34,229, or 0.30% having non-unique Resource URLs
Conclusion: A small number of DOIs have duplicate Resource URLs, even if we exclude those that have been deleted, which means that not every DOI can have a unique URL.
Assumption 5: The Landing Page is the same as the Destination Page.
HTTP has a very neat system for doing redirects. If it were that simple, then we could easily look up every Destination page and confidently say that it was the Landing Page. Not so.
Cookies
Web browsers aren’t the only tools that use HTTP. Most programming languages have HTTP capabilities built in.
Using cookies is a requirement of some websites, but it’s not a requirement of HTTP. Most websites use cookies in some way or another. When you log into a site, you expect cookies. But when you’re just browsing there isn’t any technical need. A small number of websites absolutely require cookies to be enabled to use the site, even if you’re just browsing and not logged in. Unfortunately, this includes some publishers.
Requiring cookies to use a publisher site means that you can’t fully resolve a DOI without enabling cookies. Most tools out there don’t. Some privacy-conscious people quite reasonably don’t enable cookies from all sites.
Using cookies when resolving a DOI adds considerable overhead and isn’t fool-proof.
Experiment 6: Some DOIs can’t be resolved without cookies
Hypothesis: We can’t resolve some DOIs to the Landing Page using standard tools because cookies are required.
Method: A sample of DOIs was taken per Resource URL Domain. They were resolved by following HTTP links. Where the Destination URL contains the word ‘cookie’, we mark that as a DOI requiring a cookie.
Observations:
A sample of 253,381 DOIs were resolved following HTTP redirects where necessary
a total of 6305 resolved to a page with ‘cookie’ in the URL or 2.48%
Conclusion: There are cookies at play for at least 2.48% of DOIs. This is probably a very conservative estimate, as we’re using a blunt tool looking for ‘cookie’ in the URL.
Cookies Required
For one DOI I found, the publisher system set cookies, then sent us on a series of redirects which set cookies that expired in the past and then, as far as I can tell, checked whether or not they were sent back. My working hypothesis is that it was profiling the behaviour to see what browser I was using.
I have also seen javascript-based redirects. This is where a web page loads a javascript file, which executes and sends the browser onto another URL. This seems to be to be a browser detection method. There is no way you can follow these DOIs without actually using a real browser.
This is a problem for Crossref Event Data. We can’t fire up a browser and follow every DOI: it isn’t practical. When I tried this for a sample as an experiment I got an email from another publisher who was worried that we were scraping data (good bot operators always put contact details in their request headers!).
The Crossref member rules leave some wiggle-room about whether this is allowed, but for the Event Data service, we can say that it’s a physical impossibility to collect all Event Data for DOIs like this.
Bring in the Browser
To quantify the size of the problem, we need to bring in a web browser. If we assume that some Publishers design their sites to work only with real browsers, that’s what we’ll use. Luckily there are web browsers packaged up into an automatable package, and we can use these to visit the DOI.
Using one of these is considerably slower than just following link headers.
I have split the ‘destination’ concept into two:
Naïve destination URL: The URL that you get from following HTTP redirects acccording to the HTTP specification
Browser destination URL: The URL that you get from letting a browser follow the DOI doing whatever a browser does.
Rather than defining a complicated spectrum of types of DOI resolution behaviour, I am classifying DOIs into two groups: those where standard HTTP redirects are sufficient and everything else.
The method I am using is to resolve a sample of URLs using the browser. I can then compare the Naïve Destination URL with the Browser Destination URL. If they are the same, then I didn’t need to use the browser after all. If they give a different result however, I trust the Browser one better and declare that DOI to require a browser to resolve.
Again, I took a sample of DOIs per Resource URL domain.
Experiment 7: Quantify proportion of DOIs that require a browser to redirect
Hypothesis: A number of DOIs can’t be resolved with standard tools but instead require a browser.
Method: A sample of DOIs was selected per Resource URL domain. The links were followed using standard HTTP and using a browser. Where the URLs between the two were different, the DOI was counted as requiring a browser to resolve.
Observations:
A total of 59,453 items were followed both using the Naïve and Browser methods.
Of these 5,883 items have a different URL between the two methods, or 9.88%
Conclusion: We can’t rely on the Naïve redirect, and would have to fire up the browser in about 10% of cases in the sample.
Other gnarly things
There are one or two supplementary gnarly things that crop up.
First, session IDs are sometimes embedded in the URL. This is a tracking technique similar to cookies, but instead of sending cookies, which are invisible to the user, a unique code is placed on the end of the URL. This means that everyone gets a different URL. The most popular of these is the JSESSIONID, which is used by servers in the Java ecosystem. An example URL is:
We can easily remove these if they appear at the end of a URL. Sometimes they occur in the middle of a URL, as above. Sometimes they appear as query parameters:
In this case we make no attempt to remove them. These URLs won’t be any use for matching, and we have to acknowledge that and move on.
Interpreting the results
All the above experiments involved taking as many DOIs as we had time for, gathering the Resource URLs, and then grouping the DOIs per Resource URL Domain. A sample of DOIs was investigated per each Resource URL domain to give the best chance at even coverage. The above figures have been presented as a proportion of the sampled data-set.
Now it’s time to draw some practical conclusions. I grouped the results per Resource URL Domain, so I can say that “for this domain, X% of DOIs was deleted, or aliased, or whatever”. This means that we can look at the statistics for a given domain and work out the best method for working with DOIs that belong to it.
I have created histograms of domains by their various proportions.
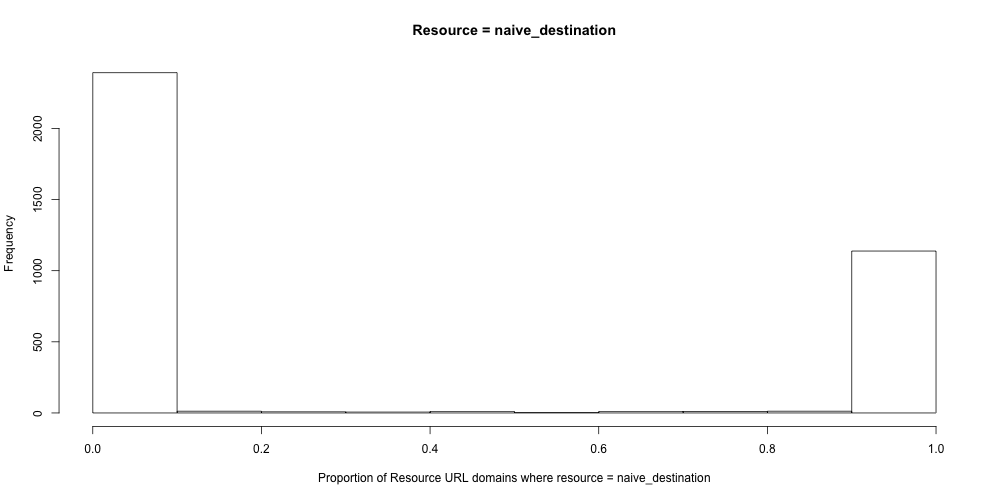
Our first chart is histogram of Resource URL Domains where the Naïve Destination = the Resource URL. Each domain is given a proportion which represents how many DOIs sampled on that domain have a Landing Page equal to the Resource URL.
There’s a clear bimodal distribution here. The conclusion here is “most domains require you to follow the link to find the destination URL“. Furthermore, the domains are consistent: there are virtually no domains that have a mix of DOIs that behave differently.
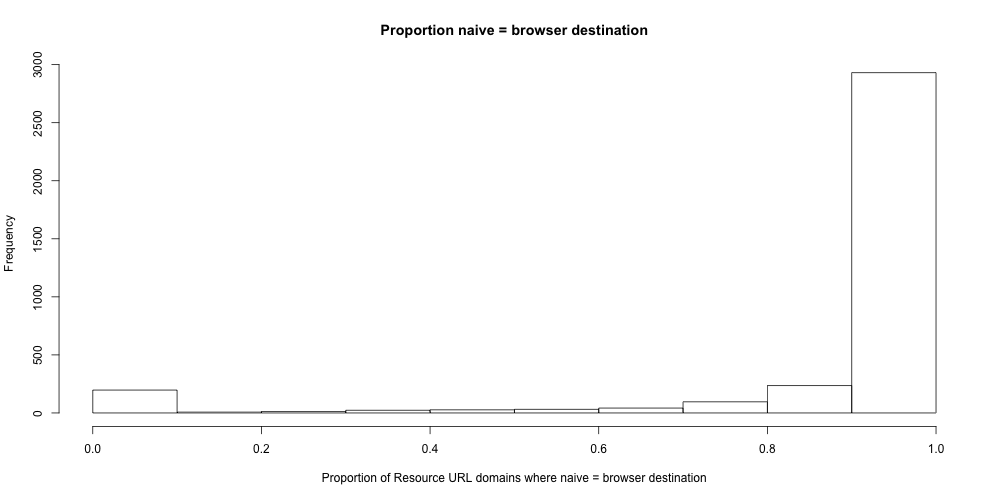
Our second chart is a histogram of Resource URLs where the Browser-based redirect = the Naive URL. Each domain is given a proportion which represents how many DOIs sampled on that domain require us to fire up a browser.
Overwhelmingly, the Browser Redirect URL is the same as the Naïve Redirect URL, meaning that we don’t need to fire up the browser, we can just use the Naïve URL, which is much easier to compute. There are some resource URL domains which require every DOI to be followed in a browser rather than just following links.
We know from this that we don’t have to use the browser most of the time. There is a small number of domains where we’re unsure (under 500) and a small number of domains where we know that we have to use a browser. This means we can focus our efforts.
There are lots of DOIs and they all behave differently.
There are thousands of publishers out there registering DOIs. There are thousands of domains. Some publishers have lots of domains. This makes it impossible to make many general observations about DOIs.
You can’t tell anything by looking at the DOI
Just by looking at the DOI you can’t tell who published it, or which publisher’s system is hosting it. Therefore you can’t tell how it’s going to behave.
We’ve looked at five kinds of URLs:
The DOI itself
The Resource URL
The “naïve” redirect URL
The “browser” redirect URL
The Article Landing Page
In some cases, the Resource URL, naïve redirect URL, browser redirect and Article Landing Page are the same. In some cases they aren’t. Of these, the fifth is somewhat mythical.
DOIs fall into classifications
Each DOI falls into a category, most preferable first:
The Resource URL is the same as the Landing Page.
The Landing Page can be discovered by following HTTP redirects.
The Landing Page can be discovered by firing up a web browser to follow redirects.
The Landing Page can’t be determined.
We can predictively group DOIs
We can group DOIs by their Resource URLs and take a sample per Resource URL Domain. If all samples for a domain behave a certain way, we can place the DOIs into one of the above four groups with a probability.
We’ll never know the full story.
Because of the diversity of Publisher Systems and the long history of Crossref DOIs, we’ll never be able to describe exactly what’s going on for all DOIs.
What next?
We’re continuing to develop Crossref Event Data. The part of the system that handles turning URLs back into DOIs will never be perfect, but we know from this research that we can at least work with a subset.
I’m also working on another project which will attempt to reverse a Landing Page URL back into a DOI by looking at the metadata on the Landing Page. You can read about it here. Ultimately we’re going to have to take a blended approach. Building a useful set of Landing Page URL to DOI mappings will be part of the mix.
As Event Data matures we’ll be sharing all the datasets automatically as part of our infrastructure, including our DOI-to-URL mapping.
And any members reading, please make your DOIs as easy to follow as possible! Please don’t require JavaScript or cookies when resolving DOIs.
If you’re read this far, perhaps you’re as interested in DOIs as we are. There’s a lot more to say on the subject, but that’s enough for now. See you at PIDapalooza!
Image Credits
All images from Wikipedia Commons. Click or hover on the image to see the attribution.