4 minute read.Using the Crossref REST API. Part 7 (with CHORUS)
Continuing our blog series highlighting the uses of Crossref metadata, we talked to Sara Girard and Howard Ratner at CHORUS about the work they’re doing, and how they’re using our REST API as part of their workflow.
Introducing CHORUS
CHORUS (www.chorusaccess.org) is an innovative non-profit organisation that supports funders, publishers, authors and institutions to deliver public access to articles reporting on funded research. Our vision is to create a future where the output flowing from funded research is easily and permanently discoverable, accessible and verifiable by anyone in the world.
CHORUS currently monitors over 400,000 articles for more than 20 US federal and two international funding agencies, and has partnerships with Department of Defense, Department of Energy, National Science Foundation, National Institute of Standards and Technology, Office of the Director National of Intelligence: Intelligence Advanced Research Projects Activity, Smithsonian Institution, US Department of Agriculture, US Geological Survey, Japan Science and Technology Agency, and the Australian Research Council. CHORUS is supported by over 50 publisher and affiliate members who represent the majority of funded published research.
<img align=right" src="/images/blog/chorus-blog.png" width=“700” alt=“mage of interaction of platforms” class=“img-responsive”/>
What problem is your service trying to solve?
CHORUS is the first service of CHOR Inc., founded in 2013 in response to the directive of the US Office of Science and Technology Policy (OSTP) for all US federal research agencies to develop and implement plans to widen public access to publications and data associated with federally funded research.
CHORUS aims to minimize public access compliance burdens and ensure the long-term preservation and accessibility of articles reporting on funded research. We provide the necessary metadata infrastructure and governance to enable a smooth, low-friction interface between funders, authors, institutions and publishers in a distributed network environment. CHORUS’ services track public accessibility of articles regardless of whether they are published Gold OA or made open by the publisher.
Can you tell us how you are using the Crossref REST API at CHORUS?
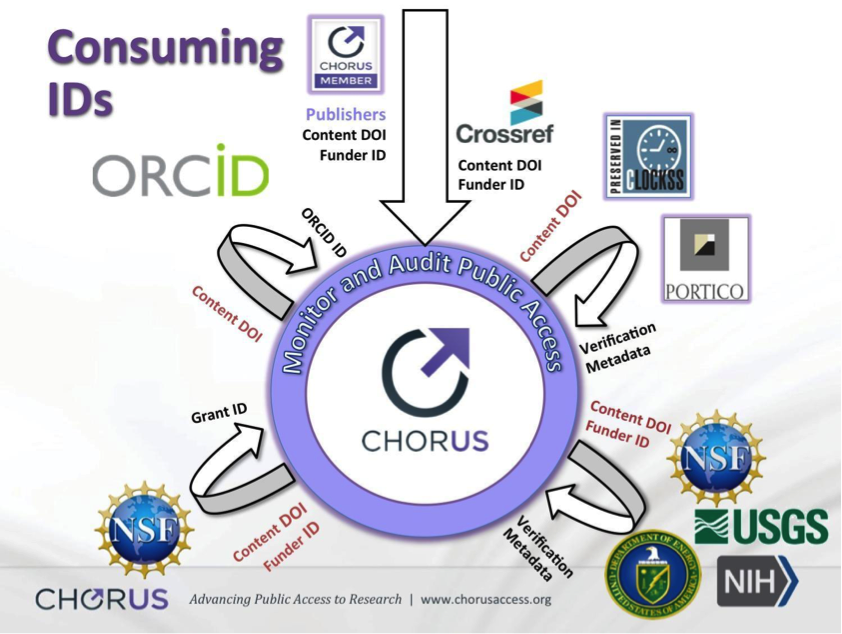
The Crossref REST API is a key source for the metadata database that powers the CHORUS Dashboard, Search and Reporting services for Funders, Institutions and Publishers.
We pull the basic bibliographic information such as publisher, journal title, article title, authors and publication date. Perhaps even more important to our area of focus are the funder, grant and license information.
CHORUS uses the Crossref REST API every day.
Every night we query the Crossref API to send us metadata for all article or conference proceeding records for our member publishers that have funder metadata matching the funders monitored by CHORUS.
CHORUS monitors these DOIs for public accessibility on publisher websites; inclusion in agency search tools; deposit in a growing list of funder repositories (e.g.,US DOE PAGES,NSF PAR, and USGS Publications Warehouse and NIH PubMed Central); and for associated ORCID researcher records. CHORUS also uses the reuse license metadata to identify when an article is expected to be made publicly accessible.
Finally, we check for ingestion in CLOCKSS and/or Portico to ensure long-term preservation and accessibility of research findings reported in journal and proceedings articles. Our preservation partners keep the full text in their dark archives, only making it available when the content may no longer be made publicly accessible by the publisher.
The collected and enhanced metadata is presented in our dashboard, search and reporting services all including links back to the publisher sites via the Crossref DOI.
What are the future plans for CHORUS?
Following the success of our Funder and Publisher Dashboards, CHORUS is expanding the services we provide to international funders, non-governmental funders, and institutions. Our first funder partnership outside of the United States is with the Japan Science and Technology Agency (JST). CHORUS announced its new Institution Dashboard service this Autumn after successfully concluding pilots with the University of Florida and University of Denver. CHORUS will also be adding links to relevant datasets and other metadata utilizing forthcoming identifiers and metadata standards.
What else would you like to see the REST API offer
It would be great to see more identification of funders from Crossref members. While we have seen great leaps since 2013, we all have a long way to go. We are also eager to see Crossref incorporate the organisation Identifiers that they have begun with ORCID, DataCite and others.
Thanks, CHORUS! If you would like to contribute a case study on the uses of Crossref Metadata APIs please contact the Community team.