4 minute read.Using the Crossref REST API. Part 9 (with Dimensions)
Continuing our blog series highlighting the uses of Crossref metadata, we talked to the team behind new search and discovery tool Dimensions: Daniel Hook, Digital Science CEO; Christian Herzog, ÜberResearch CEO; and Simon Porter, Director of Innovation. They talk about the work they’re doing, the collaborative approach, and how Dimensions uses the Crossref REST API as part of our Metadata Plus service, to augment other data and their workflow.
Introducing Dimensions
Dimensions is a next-generation approach to discovering, connecting with and contextualising research. Modern academics need data about the research ecosystem in which they exist as much as the administrators who develop institutional research strategies. All academics are now required to think long-range about their research projects, contextualise their research, and demonstrate the impact of their program. Additionally, they need to find funding, ensure that students go on to good positions, and hire talented colleagues whose skills fit well with ongoing projects. Dimensions gives the first fully-linked view of publications, grants, patents and clinical trials in an analytically-centred user experience.
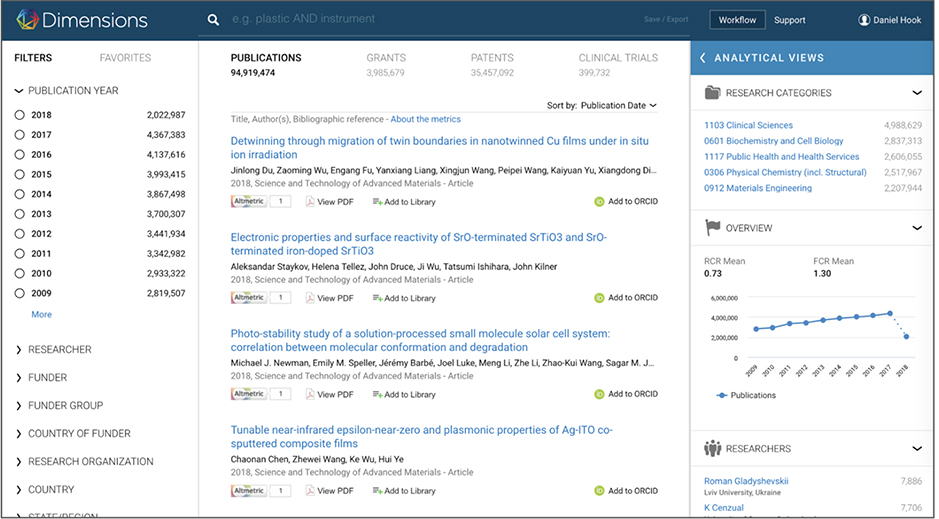
How is Crossref data used within Dimensions?
For an article to appear in Dimensions it must have a Crossref DOI, so it would not be possible to create Dimensions’ Publication index without Crossref’s data. Dimensions is built on several principles that we’ve talked about before. Here the most relevant of those principles are:
- unique identifiers should underlie everything that we do;
- data should not be inclusive and the tool should allow the user to select what they want to see;
- data should be more available to our community;
- data should be presented with as much contextual information as possible;
- the community should have enough data available to be able to create and experiment with their own metrics and indicators.
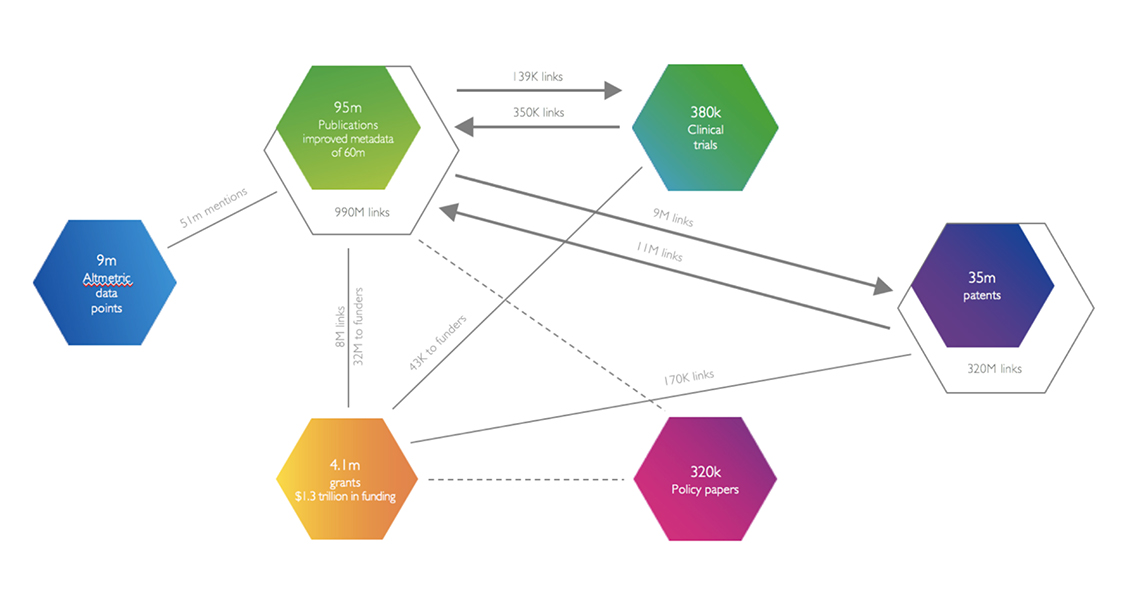
In the context of these principles, Crossref makes a perfect starting place to create a tool like Dimensions. We use the Crossref data to know about our possible “universe” of articles. We then enhance the Crossref core with data from several different places: open access publications in the DOAJ, PubMed, BioArXiv, and through relationships with publishers. In all, 60 million of the 95 million articles in the Dimensions index have a full text version that we can text and data mine for additional information.
In Dimensions’ enhancement stage we can extract address information (where not included in the original Crossref record) and map it to GRID funding information and the list of funders in Crossref’s Funder Registry as well as to our database of grants in Dimensions.
How have you incorporated citation data?
Access to citations has historically been a thorny issue for citations databases. However, I4OC celebrated its first anniversary in April this year and this project has been a key driver in helping us to build Dimensions with the level of citation coverage that we managed –– it is a fantastic enabling initiative and should be warmly welcomed by the sector. Crossref is not the only source we were able to use to gather citation data; some text mining was needed to get a full graph. Dimensions goes beyond inter-article citations and includes links between patents and publications, links between clinical trials and publications, and Altmetric mentions of publications.
Is Dimensions openly available?
Given that there is so much open data in Dimensions, it was always our intention to give a free version to the community. If you visit http://app.dimensions.ai then you’ll be able to play with the system and use it for your research. While only the publications index is fully open, when you see a link to a grant, patent or clinical trial in an article detail page, you’ll be able to navigate to that record so that you can see the full context of the data.
Beyond the ability to link the publications, Dimensions also displays the CV information which the researcher made visible publicly.
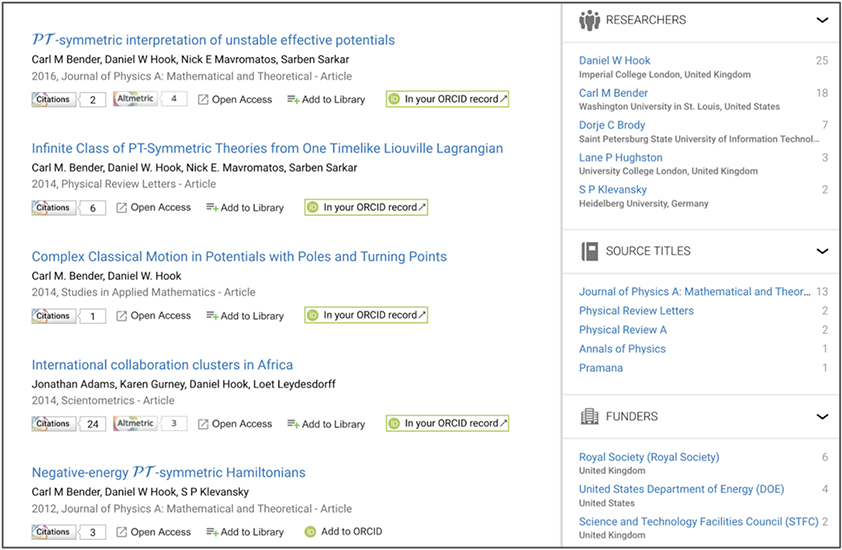
Most recently, we’ve integrated ORCID into Dimensions. This means that you can push data from Dimensions into ORCID if you connect your ORCID account to your Dimensions account.
What are the future plans for Dimensions?
Dimensions is still moving quickly and adding more functionality. Our aim is to release more data facets very soon. We plan to add a Policy Document archive and a Research Data archive. We’ve already found some fascinating insights from joining the existing data together and these two new archives should add even more interesting data.
Open access information is something that we work with Unpaywall to source for Dimensions right now. It would be great if Crossref and Unpaywall could work together to make this data higher quality and more ubiquitous.
Thank you Daniel, Christian and Simon.
If you would like to contribute a case study on the uses of Crossref Metadata APIs please contact the Community team.




