11 minute read.What’s that DOI?
This is a long overdue followup to 2016’s “URLs and DOIs: a complicated relationship”. Like that post, this accompanies my talk at PIDapalooza, the festival of open persistent identifiers). I don’t think I need to give a spoiler warning when I tell you that it’s still complicated. But this post presents some vocabulary to describe exactly how complicated it is. Event Data has been up and running and collecting data for a couple of years now, but this post describes changes we made toward the end of 2018.
If Event Data is new to you, you can read about its development in other blog posts and the User Guide. Today I’ll be describing a specific but important part of the machinery: how we match landing pages to DOIs.
Some background
Our Event Data service provides you with a live database of links to DOIs, found from across the web and social media. Data comes from a variety of places, and most of it is produced by Agents operated by Crossref. We have Agents monitoring Twitter, Wikipedia, Reddit, Stack Overflow, blogs and more besides. It is a sad truth that the good news of DOIs has not reached all corners of world, let alone the dustiest vertices of the world wide web. And even within scholarly publishing and academia, not everyone has heard of DOIs and other persistent identifiers.
Of course, this means that when we look for links to content-that-has-DOIs, what we at Crossref call ‘registered content’, we can’t content ourselves with only looking for DOIs. We also have to look for article landing pages. These are the pages you arrive at when you click on a DOI, the page you’re on when you decide to share an article.
Half full or half empty?
So we’re trying to track down links to these landing pages, rather than just DOIs. You could look at this two ways.
The glass-half-empty view would be that it’s a real shame people don’t use DOIs. Don’t they know that their links aren’t future-proof? Don’t they know that DOIs allow you to punch the identifier into other services?
The glass-half-full view is that it’s really exciting that people outside the traditional open identifier crowd are interacting with the literature. We’ve been set a challenge to try and track this usage. By collecting this data and processing it into a form that’s compatible with other services we can add to its value and better help join the dots in and around the community that we serve. Not everyone tweeting about articles counts as ‘scholarly Twitter’, and hopefully we can bridge some divides (the subject of my talk at PIDapalooza last year, 'Bridging Identifiers').
How do we do it?
One of the central tenets of Event Data is transparency. We record as much information as we can about the data we ingest, how we process it, and what we find. Of course, you don’t have to use this data, it’s up to you how much depth you want to go into. But it’s there if you want it.
The resulting data set in Event Data is easy to use, but allows you to peek beneath the surface. We do this by linking every Event that our Agents collect through to an Evidence Record. This in turn links to Artifacts, which describe our working data set.
One such Artifact is the humbly named domain-decision-structure. This is a big tree that records DOI prefixes, domain names, and how they’re connected. It includes information such as “some DOIs with the prefix 10.31139 redirect to the domain polishorthopaedics.pl, and we can confirm that pages on that domain correctly represent their DOI”. We produce this list by visiting a sample of DOIs from every known prefix. We then ask the following questions:
- Which webpage does this DOI redirect to, and what domain name does it have?
- Does the webpage include its correct DOI in the HTML metadata?
From this we build the Artifact that records prefix → domain relationships, along with a flag to say whether or not the domain correctly represents its DOI in at least one case. You can put this data to a number of uses, but we use it to help inform our URL to DOI matching.
What Agents do
The Agents use the domain list to search for links. For example, the Reddit Agent uses it to query for new discussions about websites on each domain. They then pass this data to the Percolator, which is the machinery that produces Events.
The Percolator takes each input, whether it’s a blog post or a Tweet, and extracts links. If it finds a DOI link, that’s low hanging fruit. It then looks for links to URLs on one of the domains in the list. All of these are considered to be candidate landing page URLs. Once it has found a set of candidate links in the webpage it then has to find which ones correspond to DOIs, and validate that correspondence.
For each candidate URL it follows the link and retrieves the webpage. It looks in the HTML metadata, specifically in the <meta name='dc.identifier' content='10.5555/12345678' >, to see if the article indicates its DOI. It also looks in the webpage to see if it reports its DOI in the body text.
Not so fast
But can you trust the web page to indicate its own DOI? What about sites that say that they have a DOI belonging to another member? What about those pages that have invalid or incorrect DOIs? These situations can, and do, occur.
We have the following methods at our disposal, in order of preference.
doi-literal - This is the most reliable, and it indicates that the URL we found in the webpage was a DOI not a landing page. We didn’t even have to visit the article page.pii - The input was a PII (Publisher Item Identifier). We used our own metadata to map this into a DOI.landing-page-url - We thought that the URL was the landing page for an article. Some webpages actually contain the DOI embedded in URL. So we don’t even have to visit the page.landing-page-meta-tag - We had to visit the article landing page. We found a meta tag, eg. dc.identifier, indicating the DOI.landing-page-page-text - We visited the webpage but there was no meta tag. We did find a DOI in the body text and we think this is the DOI for this page. This is the least reliable.
On top of this, we have a number of steps of validation. Again, these are listed in order of preference.
literal - We found a DOI literal, so we didn’t have to do any extra work. This is the most reliable.lookup - We looked up the PII in our own metadata, and we trust that.checked-url-exact - We visited the landing page and found a DOI. We visited that DOI and confirmed that it does indeed lead back to this landing page. We are therefore confident that this is the correct DOI for the landing page URL.checked-url-basic - We visited the DOI and it led back to almost the same URL. The protocol (http vs https), query parameters or upper / lower case may be different. This can happen if tracking parameters are automatically added by the website meaning the URLs are no longer identical. We are still quite confident in the match.confirmed-domain-prefix - We were unable to check the link between the DOI and the landing page URL, so we had to fall back to previously observed data. On previous occasions we have seen that DOIs with the given prefix (e.g. “10.5555”) redirect to webpages with the same domain (e.g. “www.example.com”) and those websites correctly report their DOIs in meta tags. Only the domain and DOI prefix are considered. We therefore believe that the domain reliably reports its own DOIs correctly in at least some cases.recognised-domain-prefix - On previous occasions we have seen that DOIs with the given prefix (e.g. “10.5555”) redirect to webpages with the same domain (e.g. “www.example.com”). Those websites do not always correctly report their DOIs in meta tags. This is slightly less reliable.recognised-domain - On previous occasions we have seen that this domain is associated with DOIs in general. This is the least reliable.
We record the method we used to find the DOI, and the way we verified it, right in the Event. Look in the obj.method and obj.verification fields.
Of course, there’s a flowchart.
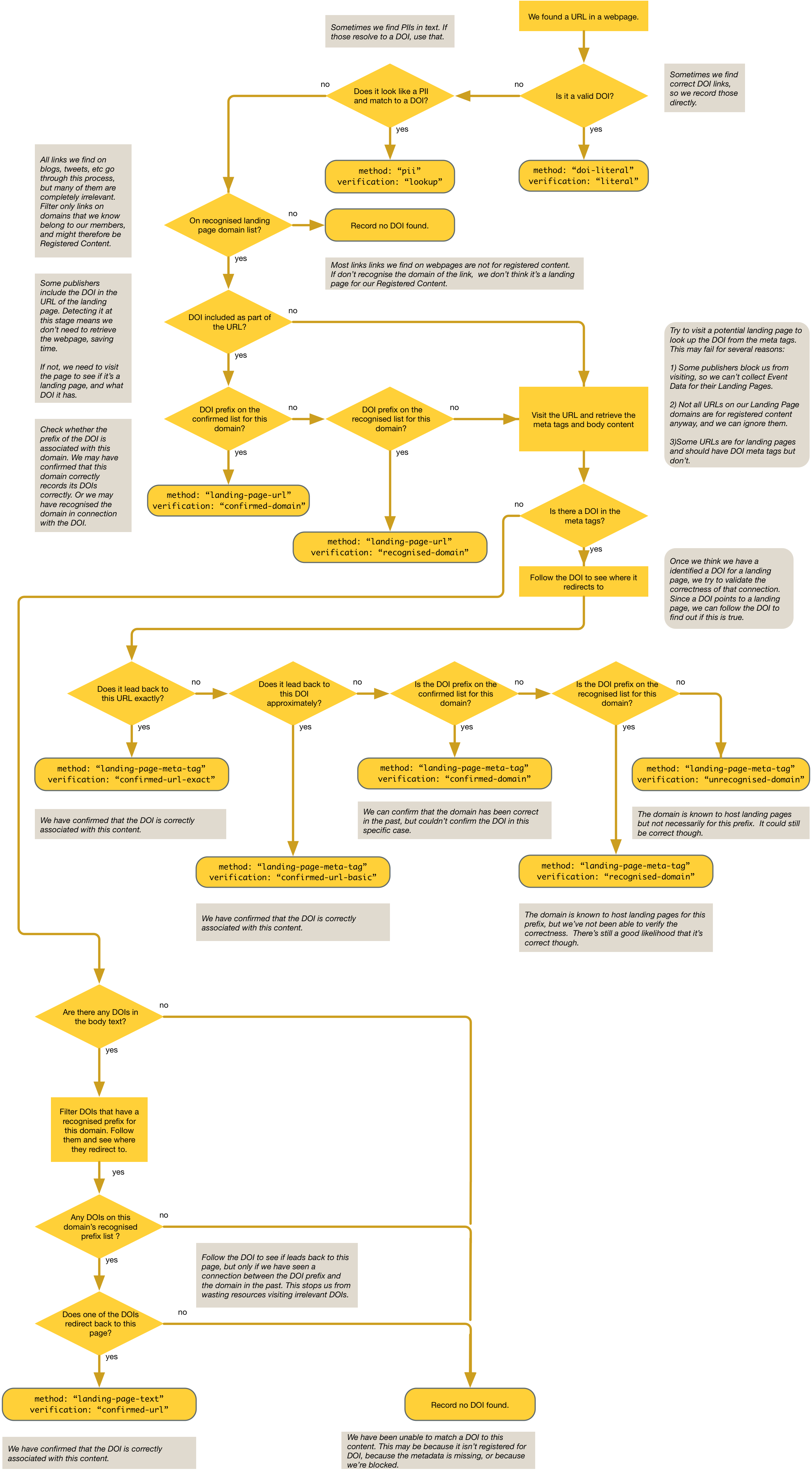
You can take a closer look in the User Guide.
If you think that’s a bit long-winded, well, you’re right. But it does enable us to capture DOI links without giving a false sense of security.
So, what happens?
If you ask the Event Data Query API for the top ten domains that we matched to DOIs in the first 20 days of January 2019, it would tell you:
| Domain | Number of Events captured |
|---|
doi.org | 2058433 |
dx.doi.org | 242707 |
www.nature.com | 170808 |
adsabs.harvard.edu | 163387 |
www.sciencedirect.com | 96849 |
onlinelibrary.wiley.com | 88760 |
link.springer.com | 63869 |
www.tandfonline.com | 41911 |
www.sciencemag.org | 39489 |
academic.oup.com | 39267 |
Here we see a healthy showing for actual DOIs (which you can explain by Wikipedia’s excellent use of DOIs) followed by some of the larger publishers. This demonstrates that we’re capturing a healthy number of Events from Wikipedia pages, tweets, blog posts etc that reference landing pages.
Awkward questions
This is not a perfect process. The whole point of PIDs is to unambiguously identify content. When users don’t use PIDs, there will inevitably be imperfections. But because we collect and make available all the processing along the way, hopefully we can go back to the old data, or allow any researchers to try and squeeze more information out of the data.
Q: Why bother with all of this? Can’t you just use the URLs?
We care about persistent identifiers. They are stable identifiers, which means they don’t change over time. The same DOI will always refer to the same content. In contrast, publishers’ landing pages can and do change their URLs over time. If we didn’t use the DOIs then our data would suffer from link-rot.
DOIs are also compatible across different services. You can use the DOI for an article to look it up in metadata and citation databases, and to make connections with other services.
This is not the only solution to the problem. Other services out there, such as Cobalt Metrics, do record the URLs and store an overlaid data set of identifier mappings. At Crossref we have a specific focus on our members and their content, and we all subscribe to the value of persistent identifiers for their content.
Of course, we don’t throw anything away. The URLs are still included in the Events. Look in the obj.url field.
Q: If DOIs are so amazing why keep URLs?
Event Data is useful to a really wide range of users. Some will need DOIs to work with the data. But others, who may want to research the stuff under the hood, such as the behaviour of social media users, or the processes we employ, may want to know more detail. So we include it all.
Q: Can’t you just decide for me?
In a way, we do. If an Event is included in our data set, we are reasonably confident that it belongs there. All we are doing is providing you with more information.
Q: Why only DOIs?
We specialise in DOIs and believe they are the right solution for unambiguously and persistently identifying content. Furthermore the content registered with Crossref has been done so for the specific benefits that DOIs bring.
Q: What about websites that require cookies and/or JavaScript to execute?
Some sites don’t work unless you allow your browser to accept cookies. Some sites don’t render any content unless you allow their JavaScript to execute. Large crawlers, like Google, emulate web browsers when they scrape content, but it’s resource-intensive and not everyone has the resources of Google!
This is an issue we’ve known about for a while. My talk two years ago was about precisely this topic. We know it’s a hurdle we’ll have to overcome at some point. We do have plans to look into it, but we haven’t found a sufficiently cost-effective and reliable way to do it yet.
Any sites that do do this will be inherently less reliable, so we recommend everyone to put their Dublin Core Identifiers in the HTML, render your HTML server-side (which is the default way of doing things) and don’t require cookies.
Q: What’s the success rate?
This is an interesting question. The results aren’t black and white. At the low end of the confidence spectrum we do have a cut-off point, at which we don’t generate an Event. But when we do create one we qualify it by describing the method we used to match and verify the connection. What level of confidence you want to trust is for you to decide. We just describe the steps we took to verify it.
It’s tricky quantifying false negatives. We have plenty of unmatched links, but not every unmatched link even could be matched to a DOI, for example there are some domains that have some DOI-registered content mixed with non-registered content.
We therefore err on the side of optimism, and let users choose what level of verification they require.
So talking of false positives or false negatives is a complicated question. We’ve not done any analytical work on this yet, but would welcome any input from the community.
Q: Why isn’t the domain-decision-structure Artifact more detailed?
We looked into various ways of constructing this, including more detailed statistics. At the end of the day our processes have to be understandable and easy to re-use. The process already takes a flow-chart to understand, and we felt that we got the balance right. Of course, as a user of this data, you are welcome to further refine and verify it.




