Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
Bibliographic references in scientific papers are the end result of a process typically composed of: finding the right document to cite, obtaining its metadata, and formatting the metadata using a specific citation style. This end result, however, does not preserve the information about the citation style used to generate it. Can the citation style be somehow guessed from the reference string only?
TL;DR
I built an automatic citation style classifier. It classifies a given bibliographic reference string into one of 17 citation styles or “unknown”.
The classifier is based on supervised machine learning. It uses TF-IDF feature representation and a simple Logistic Regression model.
For training and testing, I used datasets generated automatically from Crossref metadata.
The accuracy of the classifier estimated on the test set is 94.7%.
Threadgill-Sowder, J. (1983). Question Placement in Mathematical Word Problems. School Science and Mathematics, 83(2), 107-111
This reference is the end result of a process that typically includes: finding the right document, obtaining its metadata, and formatting the metadata using a specific citation style. Sadly, the intermediate reference forms or the details of this process are not preserved in the end result. In general, just by looking at the reference string we cannot be sure which document it originates from, what its metadata is, or which citation style was used.
Global multi-billion dollar fashion industry proves without a doubt that people care about their fashion style. But why should we care about the citation style used to generate a specific reference? This might seem like an insignificant piece of information, but it can be a powerful clue when we try to solve tasks like:
Reference parsing, i.e., extracting metadata from the reference string. If the style is known, we also know where to expect metadata fields in the string, and it is typically enough to use simple regular expressions instead of complicated (and slow) machine learning-based parsers.
Discipline/topic classification. Citation styles used in documents correlate with their discipline. As a result, knowing the citation style used in the document could provide a useful clue for a discipline classifier.
Extracting references from documents. Conforming to a specific style might suggest that the reference string was correctly located within a larger document.
Even though the style is not directly mentioned in the reference string, the string contains useful clues. Some styles will abbreviate the authors’ first names, and others won’t. Some will place the year in parentheses, others separate it with commas. The presence of such fragments in the reference string can be used as the input for the style classifier.
I used these clues to build an automatic style classifier. It takes a single reference string on the input and classifies it into one of 17 styles or “unknown”. You can use it as a Python library or via REST API. The source code is also available. If you find this project useful, I would love to hear about it!
And if you are interested in more details about the classifier and how it was built, read on.
Data
The data for the experiments was generated automatically. The training and the test set were generated in the same way but from two different samples. The process was the following:
5,000 documents were randomly chosen from Crossref collection.
Each document was formatted into 17 citation styles. This resulted in 85,000 pairs (reference string, citation style).
Very short reference strings were removed. A short reference string typically results from very incomplete metadata of the document.
From a number of randomly selected references, I removed fragments like the name of the month. These fragments appear in the automatically generated reference strings because sometimes months are included in the metadata records in Crossref collection. However, they rarely appear in the real-life reference strings, so removing them made the dataset more reliable.
5,000 strings labelled as “unknown” were also added. These were generated by randomly swapping the words in the “real” reference strings.
This process resulted in two sets: training set containing 87,808 data points and test set containing 87,625 data points. The training set was used to choose various classification parameters and to train the final model. The test set was used to obtain the final estimation of the classifier’s accuracy.
Styles
The classifier was trained on the following 17 citation styles (+ “unknown”):
acm-sig-proceedings
american-chemical-society
american-chemical-society-with-titles
american-institute-of-physics
american-sociological-association
apa
bmc-bioinformatics
chicago-author-date
elsevier-without-titles
elsevier-with-titles
harvard3
ieee
iso690-author-date-en
modern-language-association
springer-basic-author-date
springer-lecture-notes-in-computer-science
vancouver
These 17 styles were chosen to cover a vast majority of references that we see in the real-life data, without including too many variants of very similar styles.
If you need a different style set, fear not. You can use the library to train your own model based on exactly the styles you need.
Features
Our learning algorithm cannot work directly with the raw text on the input. It needs numerical features. In the case of text classification (and reference strings are text), one very common feature representation is bag-of-words. In the simplest variant, each feature represents a single word, and the value of the feature is binary: 1 if the word is present in the text, 0 otherwise.
There are many variants of this representation, for example:
The input text typically undergoes normalization before the features are extracted. Depending on the use case, this might include lowercasing, removing punctuation, bringing the words to their canonical form by stemming, etc.
We do not have to use single words as features. In some use cases, it is beneficial to use n-grams, which correspond to fixed-length sequences of words.
Instead of binary values, we might want to use some other feature weight schemes, such as the famous TF-IDF representation.
Our use case is not a typical case of text classification. We cannot use raw words as features, as words do not carry the information about the citation style. Imagine the same document formatted in different styles –– those reference strings will contain the same words, and the learning algorithm won’t be able to distinguish between them.
As a side note, in some cases, some specific words might be important. For example, if the reference contains the word “algorithm”, chances are the document is from computer science. If so, then perhaps the citing paper is from computer science as well. And in computer science, some styles are more popular than others. Machine learning algorithms are pretty good at detecting such correlations in the data. In the first version of our classifier, however, we do not take this into account. This keeps things simpler.
If not words, then what matters in our case? It seems that the information about the style is present in punctuation, capitalization and abbreviations.
To capture these clues, before extracting the features we first map our reference string into a sequence of “word types” (or “character types”). The types are the following: lowercase-word, lowercase-letter, uppercase-word, uppercase-letter, capitalized-word, other-word, year, number, dot, comma, left-parenthesis, right-parenthesis, left-bracket, right-bracket, colon, semicolon, slash, dash, quote, other.
In addition, we mark the beginning and the end of the reference string with special types start and end.
So for example this string:
Eberlein, T. J. Yearbook of Surgery 2006, 322–324.
is mapped into this sequence:
start capitalized-word comma uppercase-letter dot uppercase-letter dot capitalized-word lowercase-word capitalized-word year comma number dash number dot end
This transformation effectively brings together different words, as long as their form is the same.
After transforming the reference string we extract 2-grams, 3-grams and 4-grams. The values of the features are TF-IDF weights.
Some example features in our representation include:
lowercase-word lowercase-word lowercase-word lowercase-word - a sequence of four lowercase words. It is most likely the part of the article title and won’t have a huge impact on the decision about the citation style.
capitalized-word comma uppercase-letter dot - typical representation of an author in some styles, where the first name is given as an initial only and follows the last name.
left-parenthesis year right-parenthesis - typical for styles that enclose the year in parentheses.
number dash number - this sequence is most likely pages range.
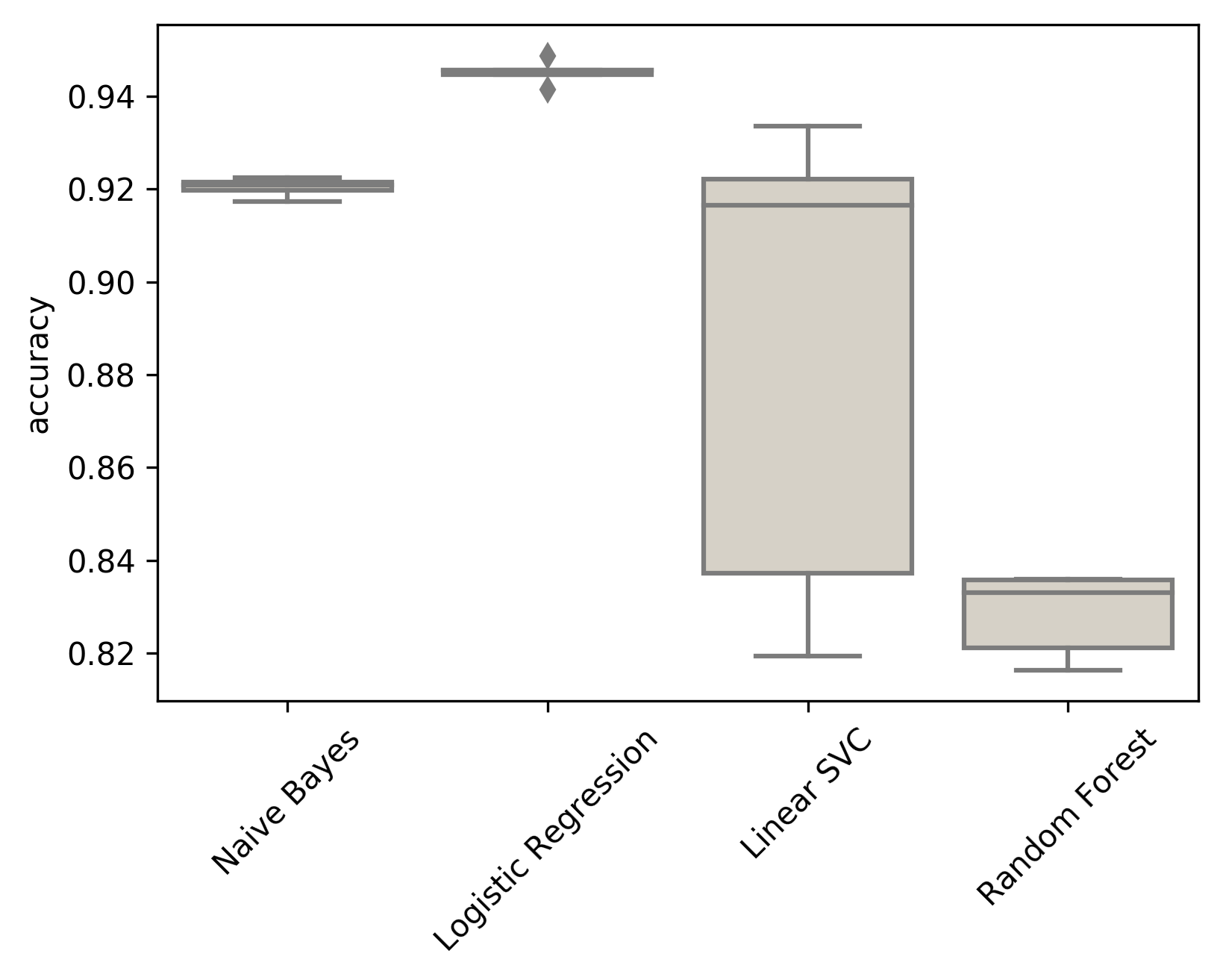
Based on these results, logistic regression was chosen as the algorithm with the best mean accuracy and the lowest variance of the results.
Final accuracy estimation
The final model was trained on the entire training set and evaluated on the test set. As evaluation metric accuracy was used. In this case, accuracy is simply the fraction of the references in the test set correctly classified by the classifier.
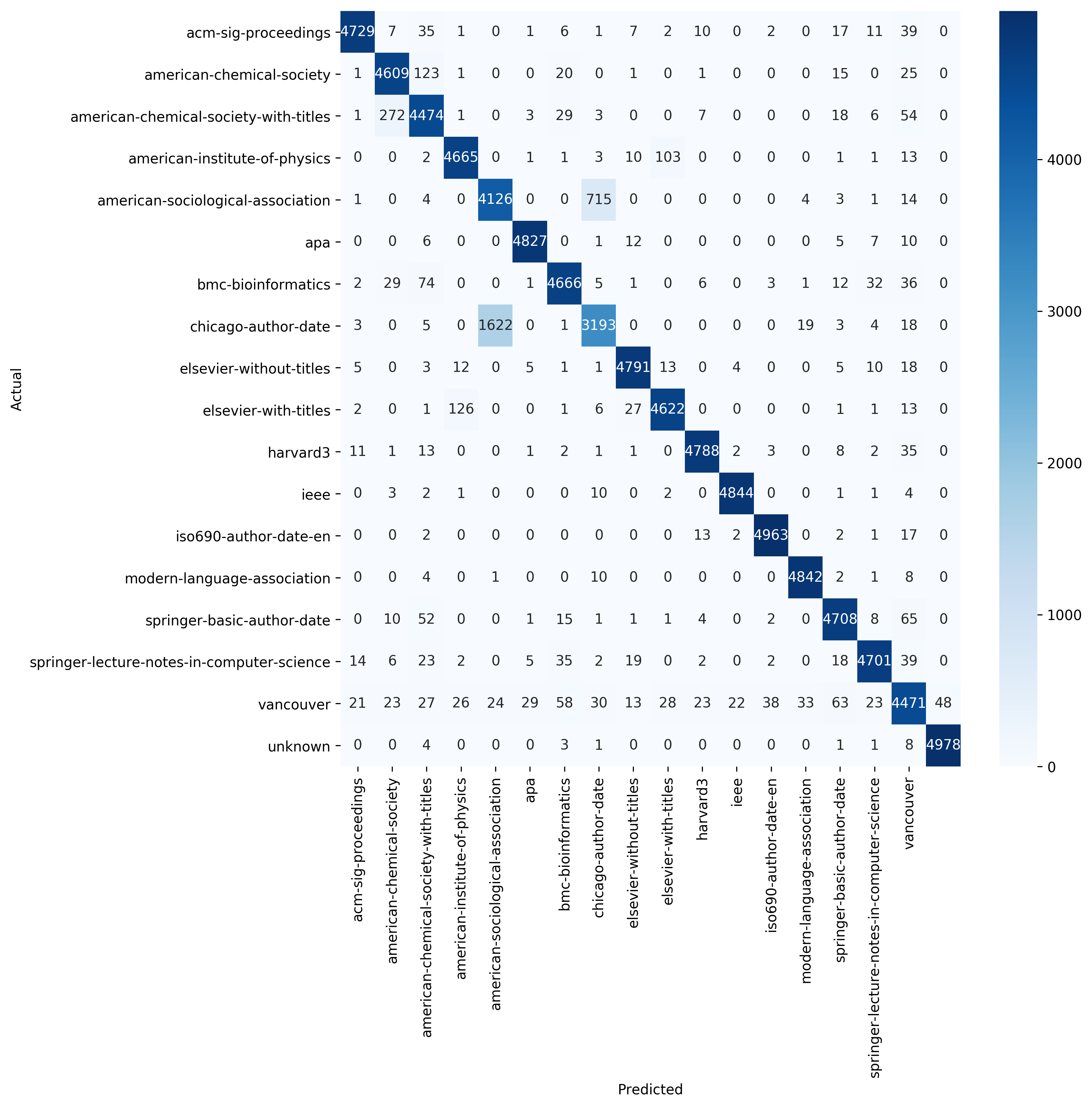
The accuracy on the test set was 94.7%. The confusion matrix shows which styles were most often confused with each other:
The most often confused styles are chicago-author-date and american-sociological-association. Let’s see some example strings from these two styles:
Legros, F. 2003. "Can Dispersive Pressure Cause Inverse Grading in Grain Flows?: Reply." Journal of Sedimentary Research 73(2):335–335
Legros, F. 2003. "Can Dispersive Pressure Cause Inverse Grading in Grain Flows?: Reply." Journal of Sedimentary Research 73 (2) : 335–335
Clarke, Jennie T. 2011. "Recognizing and Managing Reticular Erythematous Mucinosis." Archives of Dermatology 147(6):715
Clarke, Jennie T. 2011. "Recognizing and Managing Reticular Erythematous Mucinosis." Archives of Dermatology 147 (6) : 715
Chalmers, Alan, and Richard Nicholas. 1983. "Galileo on the Dissipative Effect of a Rotating Earth." Studies in History and Philosophy of Science Part A 14(4):315–40
Chalmers, Alan, and Richard Nicholas. 1983. "Galileo on the Dissipative Effect of a Rotating Earth." Studies in History and Philosophy of Science Part A 14 (4) : 315–340
It seems that the styles are indeed very similar. The strings look almost identical, apart from spacing, which is not included in any way in our feature representation. No wonder that the classifier confuses these two styles a lot.
A more detailed analysis of the classifier can be found here.