PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
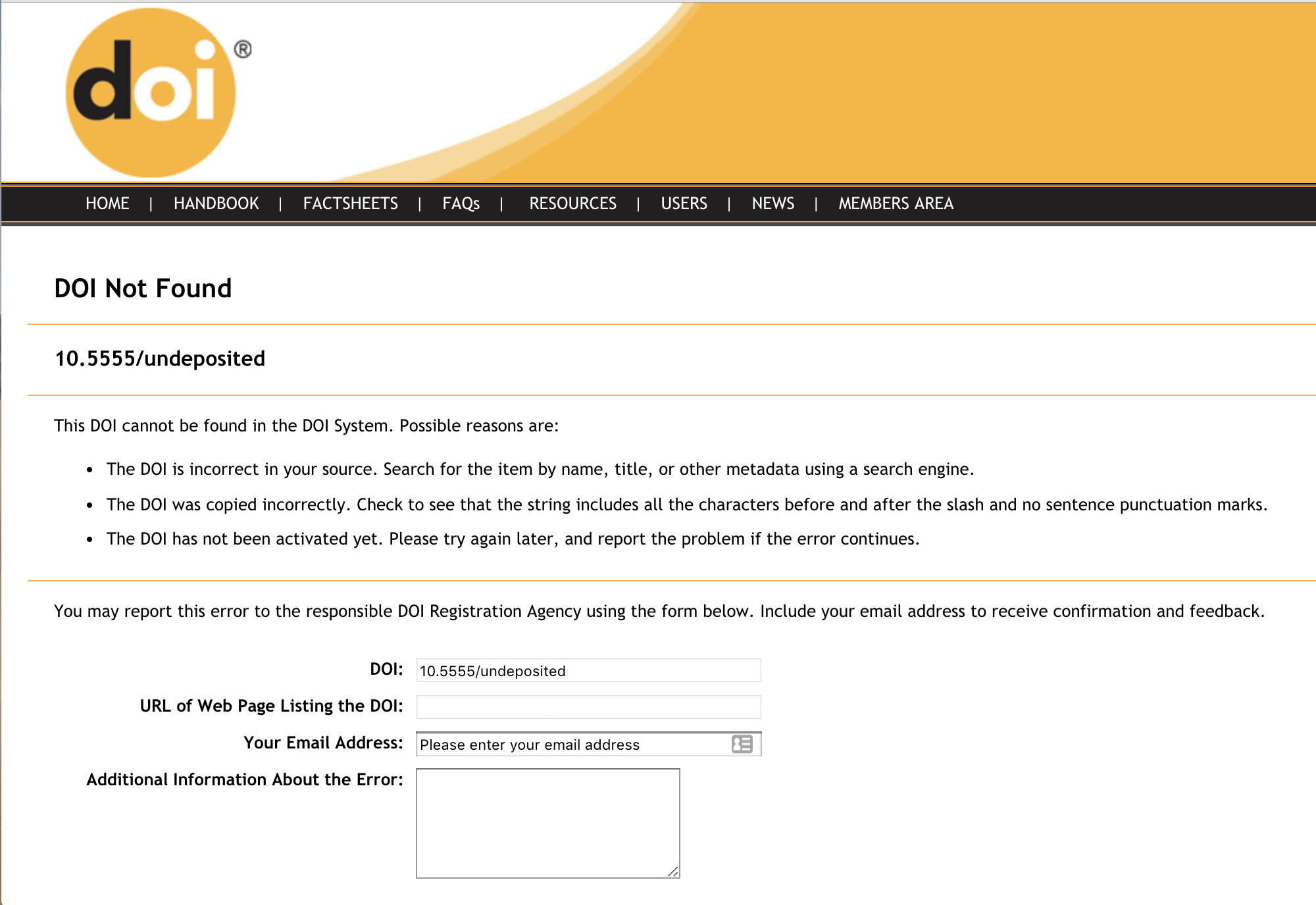
The DOI error report is sent immediately when a user informs us that they’ve seen a DOI somewhere which doesn’t resolve to a website.
The DOI error report is used for making sure your DOI links go where they’re supposed to. When a user clicks on a DOI that has not been registered, they are sent to a form that collects the DOI, the user’s email address, and any comments the user wants to share. We compile the DOI error report daily using those reports and comments, and send it via email to the technical contact at the member responsible for the DOI prefix as a .csv attachment.
If you would like the DOI error report to be sent to a different person, please contact us.
The DOI error report .csv file contains (where provided by the user):
DOI - the DOI being reported
URL - the referring URL
REPORTED-DATE - date the DOI was initially reported
USER-EMAIL - email of the user reporting the error
COMMENTS
We find that approximately 2/3 of reported errors are ‘real’ problems. Common reasons why you might get this report include:
you’ve published/distributed a DOI but haven’t registered it
the DOI you published doesn’t match the registered DOI
a link was formatted incorrectly (a . at the end of a DOI, for example)
a user has made a mistake (confusing 1 for l or 0 for O, or cut-and-paste errors)
What should I do with my DOI error report?
Review the .csv file attached to your emailed report, and make sure that no legitimate DOIs are listed. Any legitimate DOIs found in this report should be registered immediately. When a DOI reported via the form is registered, we’ll send out an alert to the reporting user (if they’ve shared their email address with us).
I keep getting DOI error reports for DOIs that I have not published, what do I do about this?
It’s possible that someone is trying to link to your content with the wrong DOI. If you do a web search for the reported DOI you may find the source of your problem - we often find incorrect linking from user-provided content like Wikipedia, or from DOIs inadvertently distributed by members to PubMed. If it’s still a mystery, please contact us.
Page maintainer: Isaac Farley Last updated: 2024-July-19