PID strategies are being written around the world right now, and the decisions being made will shape the scholarly record for decades. After 25 years running open scholarly infrastructure—now on behalf of 25,000 members in 167 countries—Crossref has an informed perspective on what those decisions should ideally rest on. Today we’re setting it out in our’s first position paper: Persistent identifiers in research infrastructure policy: the need for a holistic approach. You can read it online or download the PDF; it’s a 16-minute read.
Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, but this is changing with Schema 5.5.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
This section is for Similarity Check account administrators using iThenticate 2.0 through the browser, and describes how you can manage exclusions within your account settings..
Not sure if you’re using iThenticate v1 or iThenticate 2.0? More here.
Not sure whether you’re an account administrator? Find out here.
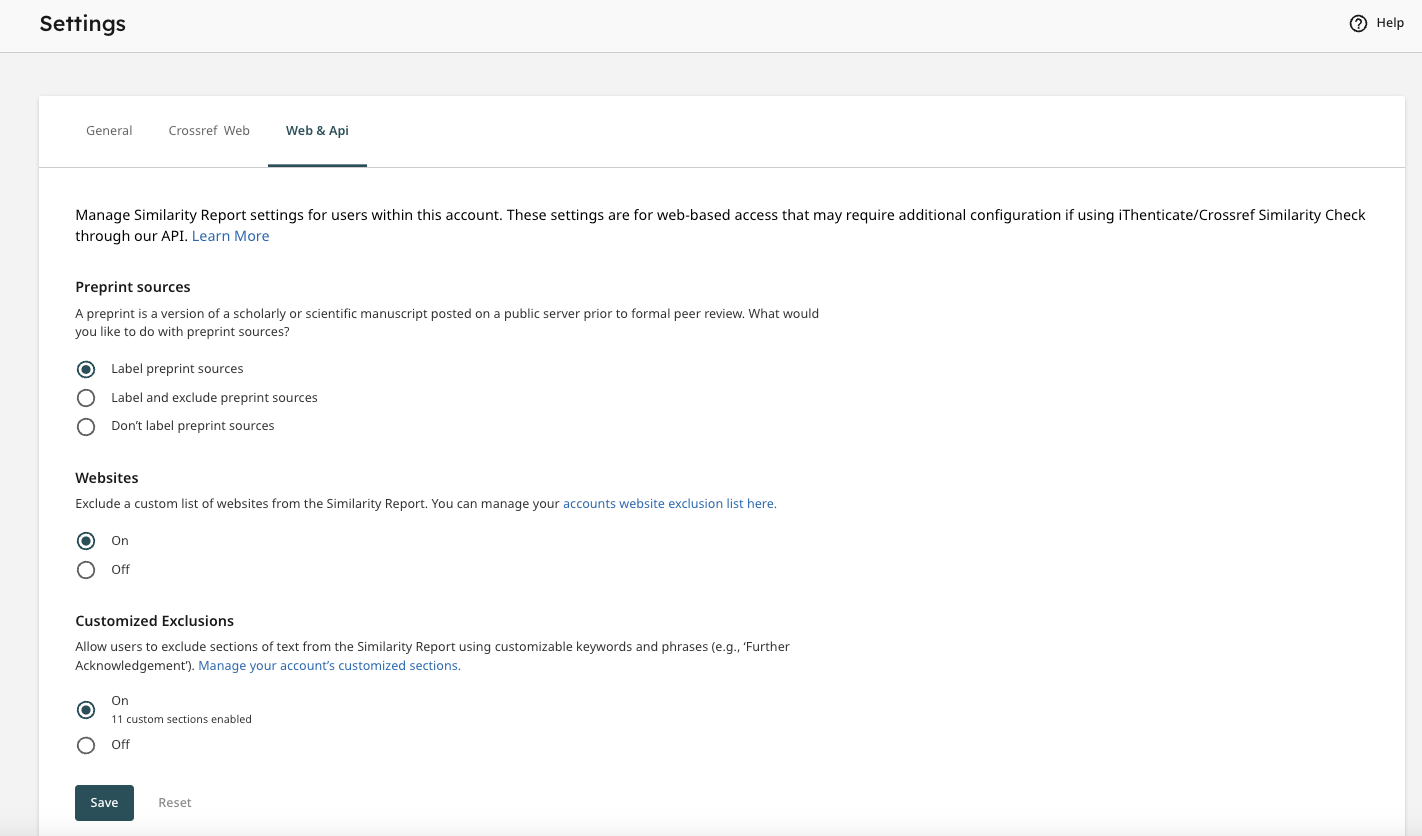
Exclusions
If you want to exclude items from your Similarity Report results, you can do this by clicking on Settings in the left hand menu in iThenticate 2.0 homepage. There are two tabs where you can change different items - one is labelled Crossref Web, and the other is labelled Web and API. Here are the various items you can exclude.
Preprint Label and Exclusions
iThenticate 2.0 introduces a new feature which will automatically identify preprint sources within your Similarity Report. This will allow you to easily identify preprints so your editors can make a quick decision as to whether to investigate this source further or exclude it from the report.
In order to start using this feature you will need to configure it within the iThenticate settings by logging directly into your iThenticate account. You can find instructions on how to configure this feature in Turnitin’s help documentation.
You also have the option to automatically exclude all preprint sources from reports. All excluded preprints will still be available within the Similarity Exclusions panel of your Similarity Report and can be reincluded in the report.
Further details of how preprints appear within the Similarity Report can be found in Turnitin’s help documentation .
The Website Exclusions setting will allow you to automatically exclude all matches to specific websites. Instructions on how to turn on and configure this feature can be found in Turnitin’s help documentation.
This feature will only exclude matches in the Internet repository. If a journal website is added to the list of excluded websites then all pages which have been crawled and indexed into Turnitin’s Internet repository will be excluded. However, journal articles from that journal which appear in the Crossref repository will not be excluded.
This feature will apply to all submissions made to the iThenticate account; including all web submissions and submissions made through any integration.
All excluded matches will still be available within the Similarity Exclusions panel of your Similarity Report and can be reincluded in the report. Further details of how these exclusions will appear can be found in Turnitin’s help documentation.
Customized Exclusions
A new feature in iThenticate 2.0 is Customized Exclusions. The Customized Exclusions setting allows administrators to create sections of text that can be excluded from the Similarity Report. Administrators can tailor these keywords and phrases to best meet the needs of their organisation (for example, ‘Further Acknowledgments’).