Research is rarely limited to a single contributor performing a single role. Behind every research output are people contributing in various ways: software development, data analyses, methodology design, and much more. Often, the same person contributes in several of these ways. Until now, Crossref metadata could only capture part of that picture, and this is changing now.
Through user experience research (UXR) initiatives that take into account our diverse membership and community, we can have a continuous, deeper understanding of the role of metadata in our members’ workflows, and ensure that our work continues to meet our community’s needs. Your support is the key to this process, and will positively impact the wider community - and if you’d like to start today, you can take part in our latest initiative: help us improve our Events page by sharing your thoughts on the page’s feedback form.
Our 2026 Community Update took place on 13 May. Two calls, one for the eastern and one for the western time zone, highlighted how our global community is growing, how we’re refining the metadata that supports trust in the scholarly record, and connecting records more effectively through our latest tools.
Funding is one of the key enablers of the research lifecycle, but has been one of the hardest parts of the scholarly record to identify, describe and connect. This is slowly changing as we have recently reached a very exciting milestone for Crossref’s Grant Linking System (GLS). What makes it remarkable is not only the numbers reached, but where the data comes from. Research funders, who joined Crossref as members, have actively contributed more than 200,000 grants to the Research Nexus (Figure 1).
The Open Funder Registry (OFR, formerly FundRef) and associated funding metadata allows everyone to have transparency into research funding and its outcomes. It’s an open and unique registry of persistent identifiers for grant-giving organisations around the world.
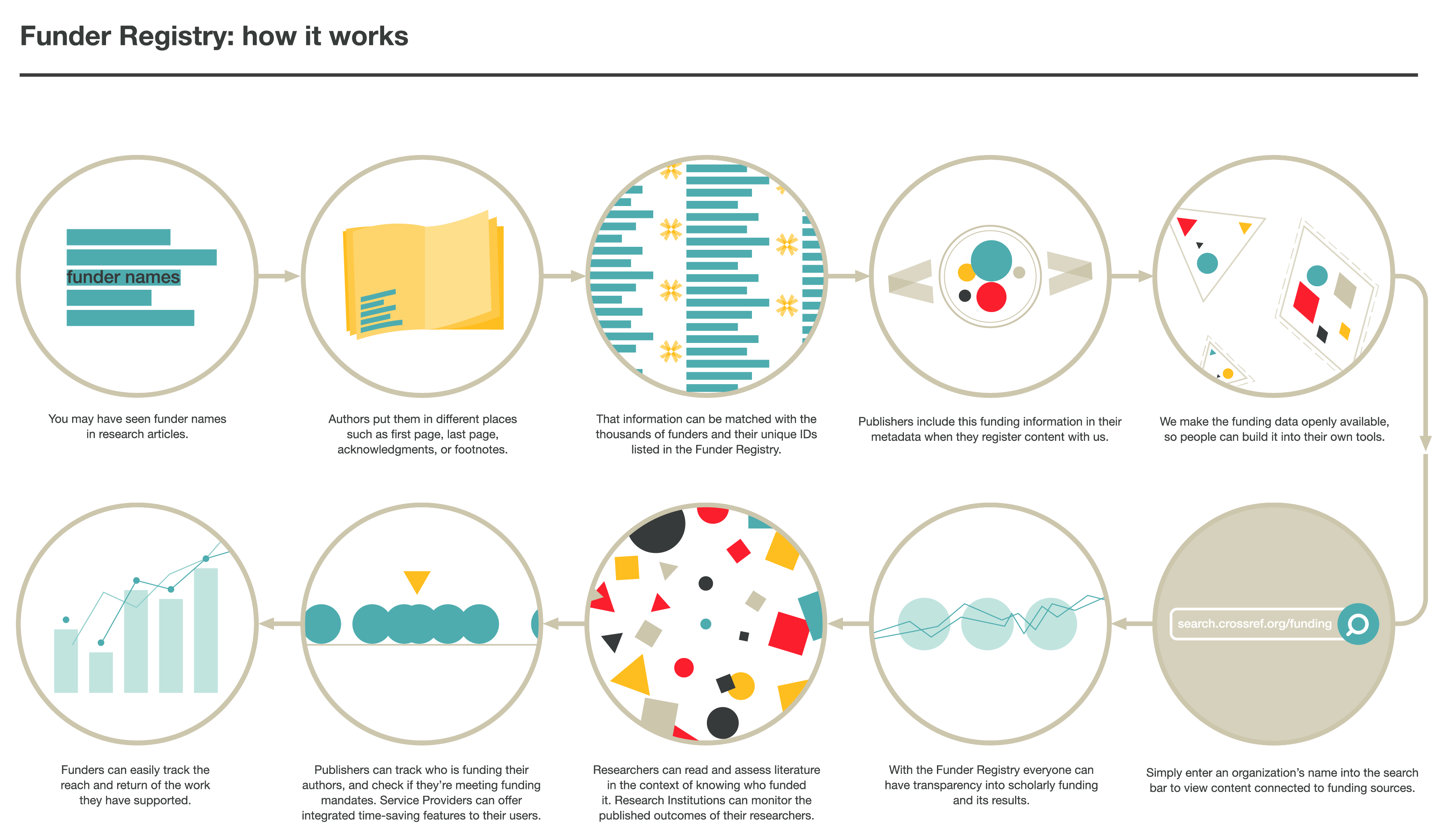
It is good practice for authors to acknowledge support for and contributions to their research in their published articles. This support may be financial, such as a grant or salary award; or practical, such as the use or loan of specialist facilities and equipment. They do this by listing the funding agency and the grant number somewhere in their article - usually the first or last page, or in the acknowledgments or footnotes section. Members contribute by depositing the funding acknowledgements from their publications as part of their standard metadata, together with the unique funder IDs listed in the OFR. The deposit should include funder names, funder IDs, and associated grant numbers.
This means that anyone can make connections, for example, to identify which funders invest in certain fields of research. Funding data is also used by funders to track the publications that result from their grants.
The Crossref OFR is an open registry of grant-giving organisation names and identifiers, which you use to find funder IDs and include them as part of your metadata deposits. It is a freely-downloadable RDF file. It is CC0-licensed and available to integrate with your own systems. Funder names from acknowledgements should be matched with the corresponding unique funder ID from the registry.
You can search funding metadata manually using our funding data search, or programmatically via our REST API. This data not only clarifies the scholarly record, but makes life easier for researchers who may need to comply with requirements to make their published results publicly available.
Watch the introductory Open Funder Registry animation in your language:
There are many benefits of clear, transparent, and measurable information on who funded research, and where it has been published. The OFR facilitates accurate funding metadata, which in turn enables multiple parties to better understand the research funding landscape:
Readers and researchers can read and assess literature in the context of knowing who funded it;
Research institutions can monitor the published outputs of their researchers;
Publishers can track who is funding their authors, and check if they’re meeting funding mandates;
Service providers can offer integrated time-saving features to their users; and
Funders can easily track the reach and return of the work they have supported.
The registry is donated by Elsevier, and is updated around every 4-6 weeks with new and updated funder records. Existing entries are also reviewed to make sure that they are accurate and up-to-date. We can then make it openly available through our funding data search and our API. If you spot anything that doesn’t look right, please let us know. You can also download a .csv file of the latest registry.
Using the OFR, members can find the unique IDs for these funders, standardize this metadata to send it to us.
Obligations and fees for the Open Funder Registry
The OFR is open to everyone. There are no fees for members depositing funding data. Open Funder Registry search and our API are also freely available.
Members must include the OFR ID for each funder if it is present in the Registry. If a funder is not in the Registry and does not have an ID, include the name of the funder.
How to participate in the Open Funder Registry
To access the OFR, you do not need to be a member, but you need to be a member to include OFR IDs in your Crossref metadata. Anyone who’s interested can simply enter an organisation’s name into the Open Funder Registry search to view content connected to funding sources. The metadata in the registry is also openly available via our API, and as a downloadable RDF file. Learn more about accessing the OFR.
Depositing metadata (members): collect funder names and grant numbers from your authors through your manuscript tracking system (or extract them from acknowledgements sections) and match them with the corresponding Funder IDs from the registry. Once this is done, it’s easy to add these three additional pieces of metadata - funder name, funder id, and grant number - as additional metadata in the regular Crossref content registration service. Learn more about how to collect and register funding data.
Whenever you register content with us, make sure you include funder names and grant numbers in the submission:
If you’re depositing XML with Crossref, include your funding data in your XML.
Retrieving metadata: you can view the content that has cited a particular funding source by entering the organisation’s name into the Open Funder Registry search. If you prefer a machine-readable query, use our REST API. If you have questions about how your organisation appears in the registry then please get in touch. Learn more about the OFR and our other services on our funder community page.